How to Fix Kubernetes CrashLoopBackOff Error

Kubernetes is one of the most popular container orchestration platforms. It helps with automated deployment, scaling, and management of containerized applications. But sometimes, it experiences some turbulences - as in a CrashLoopBackOff Error.
Calling it an error is not entirely right. It expresses a state of restart loop happening somewhere in the background, i.e., in a pod. When you try to start a Kubernetes container, and if it fails to start up repeatedly, it is said to have been experiencing repeated crashes.
You must note the reason why it is always restarting is because Kubernetes restartpolicy is set to always (by default) or Onfailure. The kubelet reads this configuration and tries to restart it, eventually ending in a loop. This wait time lets us know that there is a problem within the program and gets us to check on them. So, CrashLoopBackOff is not entirely bad. It works like a warning signal for us.
This article will discuss the main reasons for encountering a CrashLoopBackOff and efficient ways to fix them. You can also follow some of the best practices given in this article to prevent it from occurring at all. So, let’s get started.
Table Of Contents:-
- What is CrashLoopBackOff Error?
- How does Kubernetes CrashLoopBackOff Error occur?
- Causes for CrashLoopBackOff Error
- Troubleshooting CrashLoopBackOff Errors
- How to prevent it from the start?
What is CrashLoopBackOff Error?
A CrashLoopBackOff error in Kubernetes is a state in which a container (or containers) running within a pod repeatedly fails to start and immediately exits, causing Kubernetes to automatically restart the container. This process continues in a loop, leading to the pod being in a perpetual state of failure and restart. This error indicates a problem with the container or application inside it, preventing it from running successfully.
The error typically occurs when the container inside a Pod crashes immediately upon startup or shortly after starting. Kubernetes has a built-in mechanism to retry starting a container when it crashes. If the container keeps crashing, the interval between retries increases, leading to the back-off in the "CrashLoopBackOff" term.
When a Pod enters a CrashLoopBackOff state, it's essential to diagnose the root cause. This can often be done by examining the logs of the crashing container, describing the Pod to see any relevant events or errors, and checking configurations or dependencies that the container relies on.
How does Kubernetes CrashLoopBackOff Error occur?
In the previous passage, you saw how CrashLoopBackOff serves as a warning while finishing loading the missing resources. But to be sure, you can run the following command and check if the pod status is showing CrashLoopBackOff:
Kubectl get pods For example, if you run the above command, it would show something like this:
NAME READY STATUS RESTARTS AGE
my-app-6f96f97d6b-7b5dk 1/1 Running 0 2m
my-app-6f96f97d6b-9mz7p 1/1 Running 0 2m
my-app-6f96f97d6b-dc9gw 1/1 Running 0 2m
my-app-6f96f97d6b-jgj7s 0/1 CrashLoopBackOff 5 2m
my-database-75c6c7d8d5-vl5rk 1/1 Running 0 5m
nginx-7db9fccd9b-xkw6g 1/1 Running 0 10mHere you can see one pod (my-app-6f96f97d6b-jgj7s) is not ready (0/1), and its status shows as CrashLoopBackOff state with 5 restarts. This typically indicates that the container running inside the pod is encountering an issue or crashing repeatedly, and Kubernetes is trying to restart it, but it keeps failing, resulting in the CrashLoopBackOff error. You need to investigate the logs and the configuration of this pod to determine and fix the issue.
Why does it occur?
There can be multiple reasons why the pod is not able to start naturally, like the ones listed below:
#1 Configuration Errors
Misconfigurations in the application, such as incorrect environment variables or command-line arguments, can lead the application to exit unexpectedly.
Verify application configuration. Ensure environment variables and command-line arguments in the pod specification are correct.
#2 Application Errors
Bugs or errors in the application code can cause it to crash. For instance, trying to connect to a database that doesn't exist or isn't running can throw an unhandled exception, causing the application to exit.
Check the logs using kubectl logs
#3 Insufficient Resources
If a pod requests more memory than is available, the system might kill it. This could lead to a CrashLoopBackOff if the pod is continuously restarted and subsequently killed due to the same memory issue.
Adjust the resource requests and limits in the pod's configuration to match the available resources in the cluster. Ensure that resource requests are realistic and match your application's requirements.
#4 Persistent Volume Issues
For stateful applications, issues with persistent storage, such as incorrect permissions or full disk space, can cause the application to crash.
Investigate the persistent volume and storage class configuration. Ensure there is enough free space, and permissions are set correctly. Fix any issues with the storage.
#5 Dependency Failures
The application might depend on other services to be available. If these services are unavailable or malfunctioning, the application might crash.
Ensure that dependent services are up and running correctly. Implement proper error handling and retry mechanisms in your application to gracefully handle dependency failures.
#6 Readiness/Liveness Probes
Misconfigured or overly aggressive readiness or liveness probes can result in pods being killed and restarted frequently.
Adjust the probe parameters (initialDelaySeconds, periodSeconds, failureThreshold, etc.). Ensure the endpoint used by the probe in the application is working correctly.
#7 Bad Container Images
Using a corrupt or incorrect container image can cause the container to exit unexpectedly.
Ensure that you are using the correct and healthy container image. Double-check the image tag and repository. Consider rebuilding the container image if necessary.
#8 Severe System Errors
Rarely, but sometimes, underlying system errors or kernel panics can cause applications to crash.
These issues are typically beyond the control of Kubernetes or your application. Monitor system logs and consider updating or patching the underlying infrastructure to address these issues.
#9 Application Doesn't Stay in Foreground
In Docker, the primary process (PID 1) is expected to stay in the foreground. If your application daemonize itself and exits, Kubernetes will think it has crashed and will try to restart it.
Modify the application or entry point to stay in the foreground. In many cases, you can use tools like tini to manage child processes and ensure the main application process remains in the foreground.
Troubleshooting CrashLoopBackOff Error
You might have understood why CrashLoopBackOff error occurs. Now, it’s time we started discussing ways to have a proper fix for this error.
Ideally, when you want to diagnose the exact cause when a pod is in a CrashLoopBackOff state:
- Describe the pod for more detailed information using kubectl describe pod
<pod_name>. - Check the pod's logs using kubectl logs
<pod_name>. - Use
kubectl_get_eventsto list out all events occurring in a single pod and try looking where things went wrong. - Check deployment status
1. Checking Pod Description
Before diving deep into logs or events, get a quick overview of what's going on by describing the problematic pod.
kubectl describe pod <POD_NAME> -n <NAMESPACE>Name: my-app-pod-12345
Namespace: default
Containers:
my-app-container:
State: Waiting
Reason: CrashLoopBackOff
Last State: Terminated
Reason: Error
Exit Code: 1
Restart Count: 5
Events:
Warning BackOff 98s (x14 over 9m58s) kubelet Back-off restarting failed containerWhat you get from the output:
- The pod's container (my-app-container) is repeatedly crashing (as shown by Restart Count: 5).
- The State section indicates that the container is in a "CrashLoopBackOff" state, which means it's crashing repeatedly shortly after starting.
- The Last State section shows that the container's last termination reason was an "Error" with an Exit Code of 1. This is a generic error exit code and you would need to check the container's logs (kubectl logs my-app-pod-12345) to determine the exact cause.
- The Events section at the bottom provides a history of events related to the pod. In this case, the container has been restarted multiple times, and there's a warning about the back-off for restarting the failed container.
2. Checking Pod Logs
To resolve the issue above, the next step would typically be to look at the container logs (kubectl logs my-app-pod-12345) to pinpoint the root cause of the crash.
kubectl logs <POD_NAME> -n <NAMESPACE>If the pod has multiple containers, specify the container name with:
kubectl logs <POD_NAME> -c <CONTAINER_NAME> -n <NAMESPACE>What to look for:
- Error messages or stack traces that might indicate software bugs or misconfigurations.
- Errors connecting to databases or other external services.
- Any other unusual or unexpected log messages shortly before the pod crashes.
3. Checking Events
Events in Kubernetes provide a stream of what's happening in the cluster, from scheduling decisions to network issues.
kubectl get events -n <NAMESPACE> --sort-by=.metadata.creationTimestampWhat to look for:
- Pod-related errors, such as scheduling issues or image pull problems.
- Warnings or errors related to resource constraints or limits.
- Node-level issues that might affect the pod.
4. Checking Deployment
Inspecting the Deployment can give insights into how the pod should behave when running.
kubectl describe deployment <DEPLOYMENT_NAME> -n <NAMESPACE>What to look for:
- Replicas: Ensure that the desired number matches the current state.
- Strategy: If the rolling update strategy is used, look for any issues related to updating the pods.
- Pod Template: Check for configuration issues, such as environment variables, secrets, or other injected data.
- Selectors: Ensure that the selectors match the expected labels on the pods, ensuring proper management.
- Conditions: Identify any failed conditions related to the Deployment.
Ways to prevent it from the start
- Implement readiness and liveness probes in your pod configurations. These checks help Kubernetes understand the health of your application. The readiness probe ensures that your application is ready to serve traffic, while the liveness probe confirms that your application is still functioning as expected. Properly configured probes can prevent restarting containers when there is no need, and can gracefully handle transient issues.
- Set appropriate resource requests and limits for CPU and memory in your pod specifications. Underestimating or overestimating resource requirements can lead to "CrashLoopBackOff" errors. Accurate resource definitions ensure that your application gets the resources it needs without overloading the node.
- Unhandled exceptions and errors can lead to container crashes. Implement error logging and graceful recovery mechanisms, such as retries for network connections or external dependencies. Be sure to monitor these logs for unexpected errors.
- Include comprehensive testing as part of your CI/CD pipeline. Run unit tests, integration tests, and container security scans. This helps catch issues early in the development process, reducing the likelihood of encountering "CrashLoopBackOff" errors in production.
- Implement comprehensive logging and monitoring solutions. Centralized logging, using tools like Elasticsearch, Logstash, and Kibana (ELK stack), or Prometheus and Grafana for monitoring, helps you quickly identify issues and troubleshoot "CrashLoopBackOff" errors. Establish alerting mechanisms to proactively address problems.
- When making changes to your applications or configuration, use rolling updates to minimize service disruption. Ensure that you have the ability to quickly roll back to a stable version in case new deployments cause issues.
Conclusion
Preventing "CrashLoopBackOff" errors requires a combination of proactive measures, robust application design, thorough testing, and continuous improvement through monitoring and feedback.
To effectively diagnose and fix "CrashLoopBackOff" errors, it's important to have robust monitoring and logging in place. Implement practices such as regular code reviews, testing, and continuous integration to catch configuration and application code errors early.
Additionally, ensure that your Kubernetes cluster is correctly sized and configured to meet the resource demands of your applications. By following these best practices, you can maintain the reliability and availability of your applications in a Kubernetes environment.
Atatus Kubernetes Monitoring
With Atatus Kubernetes Monitoring, users can gain valuable insights into the health and performance of their Kubernetes clusters and the applications running on them. The platform collects and analyzes metrics, logs, and traces from Kubernetes environments, allowing users to detect issues, troubleshoot problems, and optimize application performance.
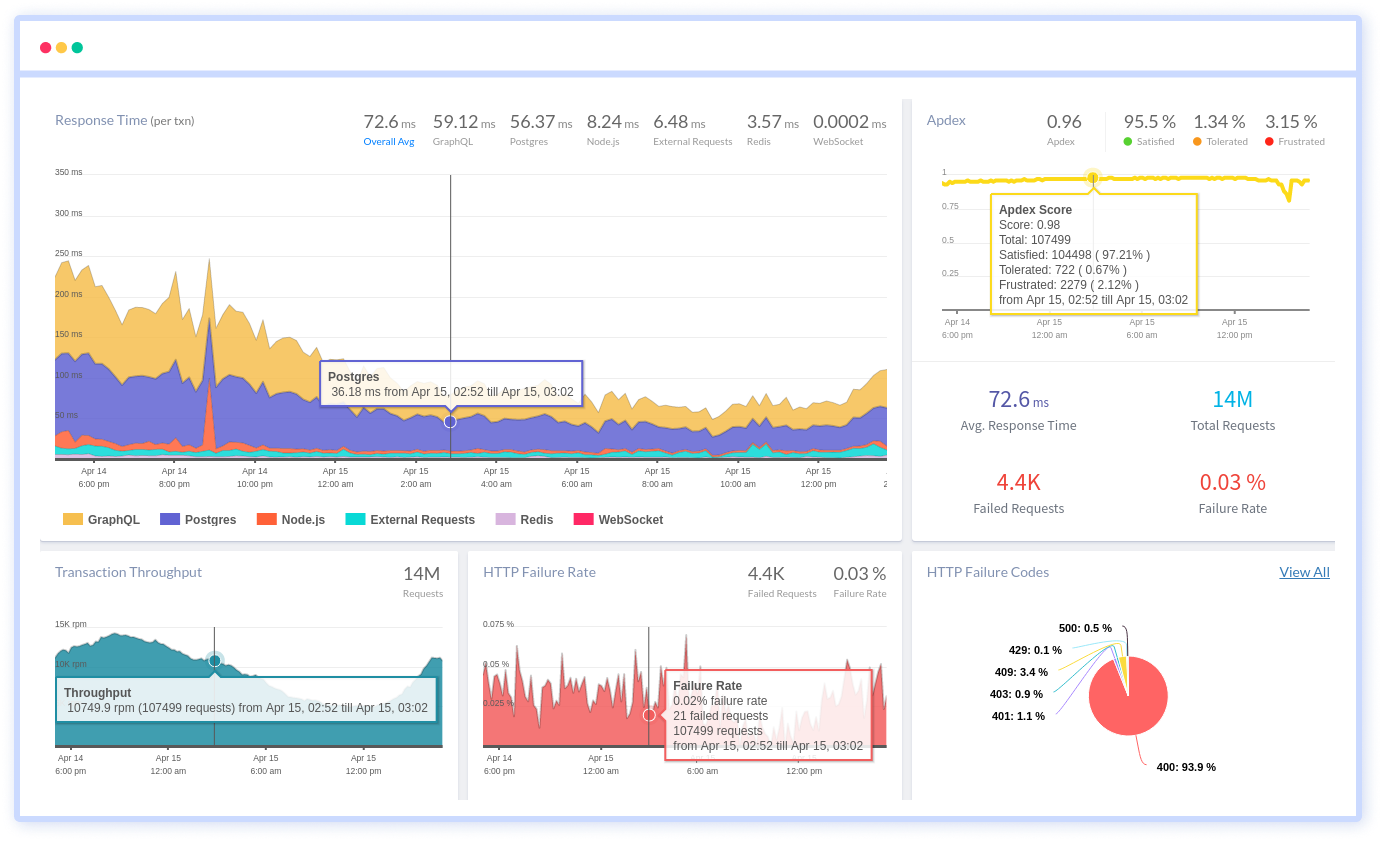
You can easily track the performance of individual Kubernetes containers and pods. This granular level of monitoring helps to pinpoint resource-heavy containers or problematic pods affecting the overall cluster performance.
#1 Solution for Logs, Traces & Metrics
![]() APM
APM
![]() Kubernetes
Kubernetes
![]() Logs
Logs
![]() Synthetics
Synthetics
![]() RUM
RUM
![]() Serverless
Serverless
![]() Security
Security
![]() More
More
