What is RabbitMQ Queues Test?
RabbitMQ is one of the most popular open source message brokers. It is designed to provide high availability, scalability and reliability for enterprise level messaging applications.
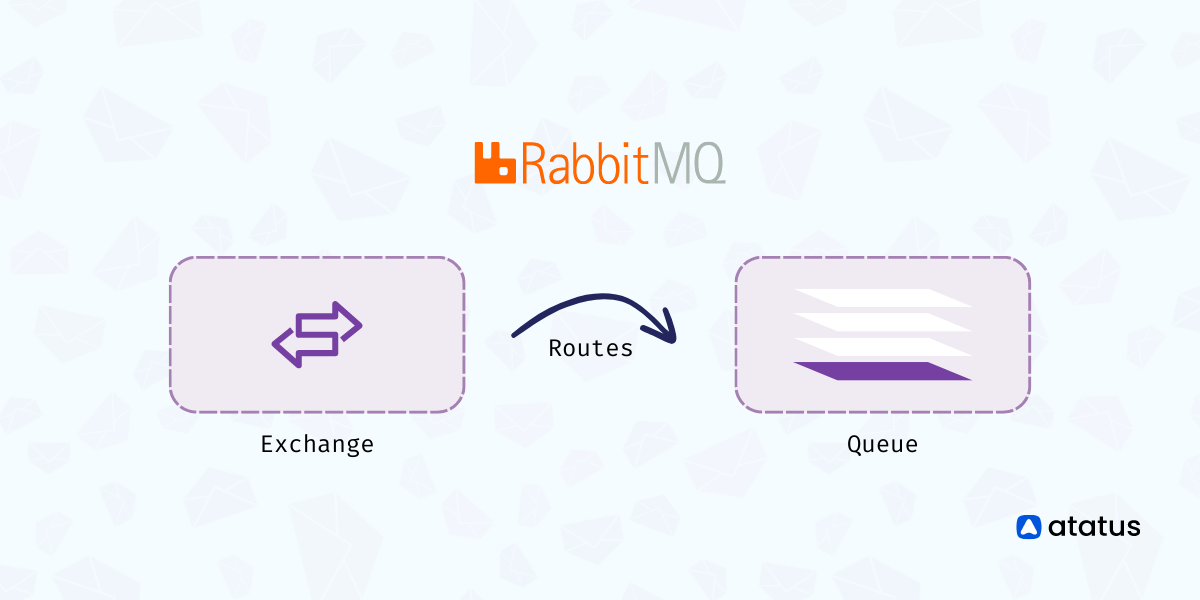
RabbitMQ basically navigates exchanges between a client (producer) and a consumer, who receives these processed messages. Messages are bundled into queues based on their characteristics and adequately processed.
This segregation helps organize data much easier and makes alloting similar functions to a single queue.
RabbitMQ queues involves publisher publishing messages to an exchange, which directs these messages based on their binding to different queues. The queues further send these messages to the customer.
Table Of Contents:-
- What is RabbitMQ queues test?
- How does RabbitMQ Queues Test work?
- What are the different RabbitMQ tests?
- Testing RabbitMQ Queues with Node.js and amqplib
- What does a RabbitMQ test measure?
- What is the use of these tests?
What is RabbitMQ queues test?
A RabbitMQ queues test is a specific type of testing that focuses on verifying the functionality and behavior of queues within the RabbitMQ message broker.
In RabbitMQ, queues are fundamental components used to store and hold messages until they are consumed by consumers (subscribers) connected to the queue. Properly testing queues ensures that messages are correctly routed, stored, and processed within the message broker, which is crucial for building reliable and efficient messaging systems.
Reasons for it being popular:
- Lightweight and easy to install
- Supports multiple messaging protocols
- Provides client APIs for Java, Javascript, Python, Ruby, etc
- Easy administration console but with powerful features
- Supports LDAP and TLS, can be deployed in both public and private clouds
- Provides many features for both broker and client
How does RabbitMQ Queues Test work?
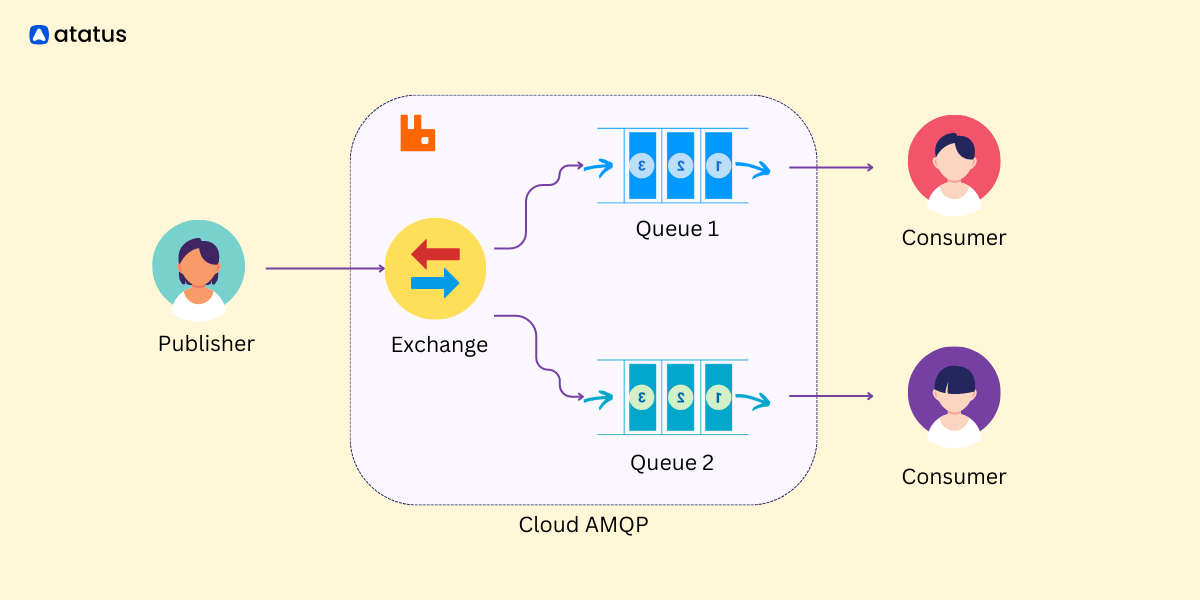
Before starting the tests, you need to set up a RabbitMQ instance or cluster for testing purposes. This involves installing RabbitMQ, configuring necessary exchanges, queues, and bindings.
After setting up RabbitMQ, you prepare the test environment by creating a separate virtual host in RabbitMQ dedicated to testing, so that the tests don't interfere with the production environment.
Then you create a queue programmatically or using RabbitMQ management tools. Ensure the queue properties (durable, non-durable, exclusive, auto-delete) are correctly set.
Still unclear? Don't worry, learn more about RabbitMQ Monitoring here.
That’s it! You are all set to run the tests now. Let’s look at some of these different tests now.
What are the different RabbitMQ tests?
Now, let’s look at the different tests available in RabbitMQ:
1. Basic Publish/Subscribe Test
A basic test would involve creating a producer application that sends messages to a specific queue, and a consumer application that retrieves and acknowledges these messages. The test is considered successful if the consumer receives all messages the producer sent in the correct order.
2. Message Persistence Test
In this test, after a producer sends messages to a queue, the RabbitMQ server is intentionally shut down and restarted. The consumer then attempts to retrieve these messages. If the messages are retrieved successfully, it implies that the messages were correctly persisted in the queue even when RabbitMQ was not running.
3. Message Acknowledgement Test
Here, the behavior of manual message acknowledgments is tested. A consumer fetches a message but does not acknowledge it. The consumer then disconnects. A new consumer connects and checks whether it can retrieve that same message. If it can, the test is successful, showing that RabbitMQ correctly re-queued an unacknowledged message.
4. Message Routing Test
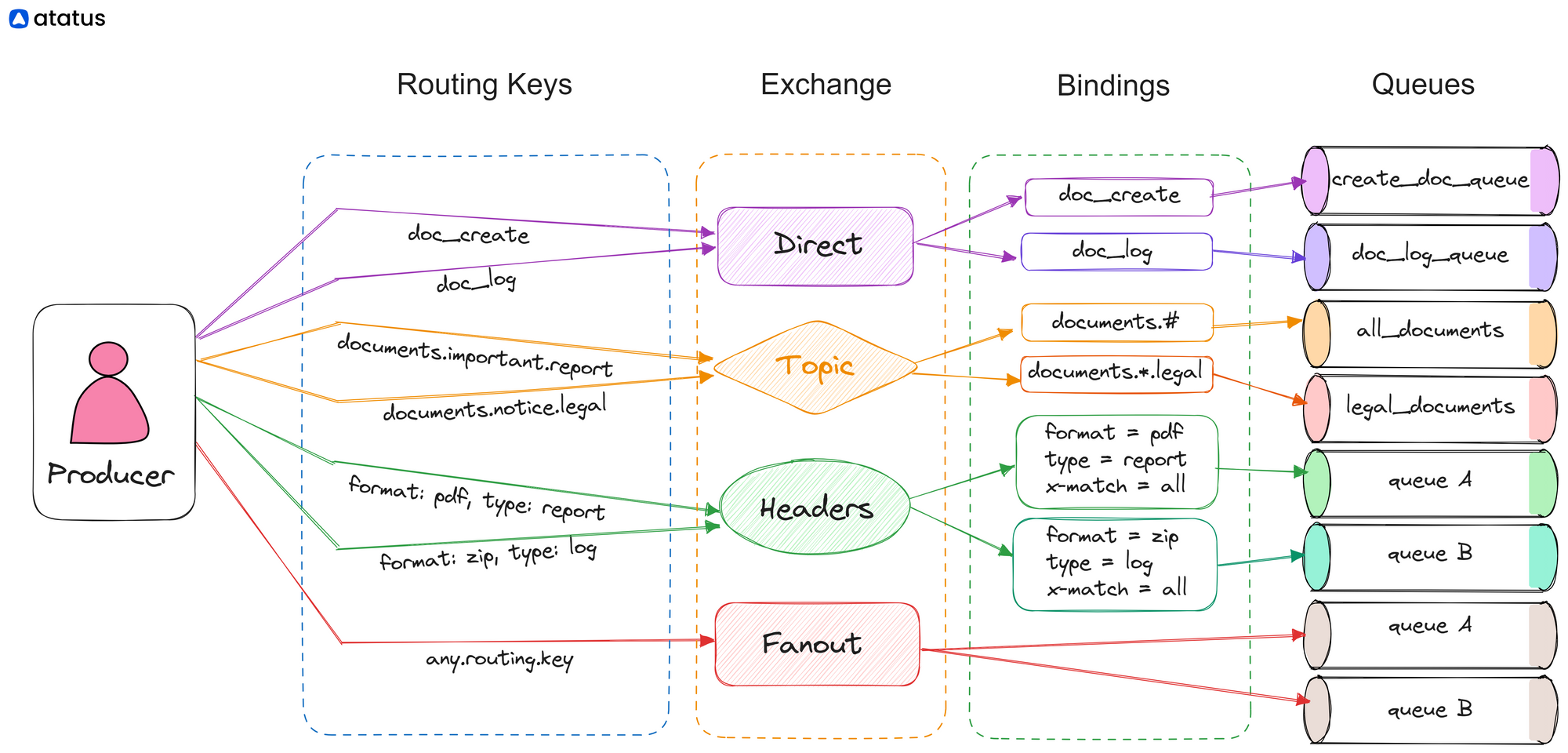
These tests check the routing of messages to the correct queues. If using direct exchange, each queue is bound to the exchange with a specific routing key. The producer then sends messages with the routing key, and the test checks if the messages are correctly routed to the associated queue. For topic exchange, similar tests are performed with the routing key having a pattern, and the routing of the messages is checked based on these patterns.
5. Load Testing
This test checks RabbitMQ's behavior under heavy loads. A large number of messages are sent to a queue, and the system's behavior is monitored to check for any slowdowns or crashes.
6. Cluster and High Availability Test
If RabbitMQ is set up in a clustered environment for high availability, tests are performed by shutting down nodes intentionally to see if the messages are still available and the system continues to function correctly.
It's worth noting that these tests can be manually done, but it's a good practice to automate them using testing frameworks (like Python's unittest or pytest, or Java's JUnit). The framework would typically allow defining setup and teardown actions (like creating and deleting queues), as well as assertions to compare the expected and actual results.
Testing RabbitMQ Queues with Node.js and amqplib
To create an example for testing RabbitMQ queues, we'll use Node.js along with the amqplib library, which is a popular RabbitMQ client for Node.js. Make sure you have RabbitMQ installed and running on your machine.
Step-1: Install the required library:
npm install amqplibStep-2: Create a publisher and consumer script:
//publisher.js
const amqp = require('amqplib');
async function publishMessage() {
try {
const connection = await amqp.connect('amqp://localhost');
const channel = await connection.createChannel();
const queue = 'test_queue';
await channel.assertQueue(queue, { durable: false });
setInterval(() => {
const message = `Message sent at ${new Date().toISOString()}`;
channel.sendToQueue(queue, Buffer.from(message));
console.log(`Sent: ${message}`);
}, 1000);
} catch (error) {
console.error('Error publishing message:', error);
}
}
publishMessage();// consumer.js
const amqp = require('amqplib');
async function consumeMessage() {
try {
const connection = await amqp.connect('amqp://localhost');
const channel = await connection.createChannel();
const queue = 'test_queue';
await channel.assertQueue(queue, { durable: false });
console.log('Waiting for messages...');
channel.consume(queue, (message) => {
console.log(`Received: ${message.content.toString()}`);
}, { noAck: true });
} catch (error) {
console.error('Error consuming message:', error);
}
}
consumeMessage();Step-4: Run the scripts in two separate terminal windows:
node publisher.jsnode consumer.jsThe Publisher.js script will send a new message to the test_queue every second, and the Consumer.js script will receive and print the messages as they arrive.
You can observe how messages are being sent and received through the RabbitMQ queue. This example demonstrates a basic setup for testing RabbitMQ queues and can be extended further based on your specific use case.
What does a RabbitMQ test measure?
From the above sections, you might have come across the many number of tests available in RabbitMQ. But do you know what they are all for? In this section we will take a look at what these tests measure in real life and see how they might be of help to us.
| Parameters | Description | Interpretation |
|---|---|---|
| State | Indicates the state of the queue | Measures the state of the queues - whether running or idle |
| Running queues | Indicates the number of queues running currently | You can identify which queues are running within a cluster |
| Idle/down queues | Indicates the number of queues remaining idle now | Ideally, this measure value should be 0. If you see queues going down persistently, try mirroring the queues. Mirroring: Each mirrored queue consists of one master and one or more mirrors. The master is hosted on one node commonly referred as the master node. Each queue has its own master node. All operations for a given queue are first applied on the queue's master node and then propagated to mirrors. Messages published to the queue are replicated to all mirrors. Consumers are connected to the master regardless of which node they connect to, with mirrors dropping messages that have been acknowledged at the master. Queue mirroring therefore enhances availability, but does not distribute load across nodes (all participating nodes each do all the work). If the node that hosts queue master fails, the oldest mirror will be promoted to the new master as long as it synchronised. Unsynchronised mirrors can be promoted, too, depending on queue mirroring parameters. |
| Unacknowledged messages | This measure indicates the number of messages waiting in all queues waiting for acknowledgement | Ideally this value should be less. Because if you have too many unacknowledged messages, this can lead to taking up of lot of memory space. |
| Messages in queue | Measures the total number of messages in all the queues across all the clusters | When messages are lesser in number, customers receive prompt reply message and vice-versa. Some problems with long queues are:
|
| Published message rate | Indicates the rate at which publishers are publishing the messages | Can be considered as the average rate at which messages are getting published across the queues. |
| Publisher confirmation Rate | A 'Publish Confirm' is simply an acknowledgement sent by the cluster to a publisher, confirming receipt of the message. | This rate has a performance impact - the lesser the better. |
| Manually acknowledged message delivery rate | A manual acknowledgement is an 'explicit' acknowledgement that is received from the consumer. | Acknowledgements sent manually can be positive or negative. A positive acknowledgement instructs RabbitMQ to record a message as delivered and can be discarded. Negative acknowledgements with basic.reject have the same effect. But you must understand that manually acknowledging messages is not feasible in real when the load become high and hence should be avoided. |
| Auto-acknowledged message delivery rate | Here the consumer sets up acknowledgement initially so that he doesnt have to assess them individually everytime. | This method is preferred more to manual acknowledgement as it makes the process more easier and faster. |
| Consumer acknowledgment rate | Indicates the rate at which messages in this queue are being acknowledged by consumers. | When this value is abysmmally low, be sure to check out if the delay is caused by manual acknowledgements or not. Because otherwise it is time that you re-fix your settings. |
| Message redelivery rate | Checks the rate at which messages with redelivery flag are prompted. | |
| Message return rate | When messages in a queue are set to mandatory “true”, queues cannot generally return them. But when the messages are unroutable, then there is no other way to process them. |
Unroutable messages have no destination. For example, a message sent to an exchange without any bound queue. Clusters with the 'mandatory' flag set to 'true' return an unroutable message to producers via the `basic.return` AMQP method. |
| Disk read rate | The rate at which queues read the messages from the disk. | It is possible that a high value indicates that messages are frequently read from the disk and not from RAM. The reason could have been high memory pressure, forcing RabbitMQ to store messages on disk instead of in RAM. |
| Disk write rate | The rate at which queue wrote messages to the disk. | Same as disk read rate. |
| Queues | Total number of queues present in the cluster. | We can identify how many queues are present, which clusters have which queues. |
| Used memory | Total memory used up by the queue. | The key factor impacting memory usage is message queue length. To see if queue length is what is eating up your memory, try to correlate messages in queue with the used memory value at a particular time period. If you find that as a cause then try limiting the size of your queues. |
What is the use of RabbitMQ tests?
RabbitMQ queues tests are vital for assessing and ensuring the proper operation, reliability, and performance of RabbitMQ, a popular open-source message-broker software. RabbitMQ plays a crucial role in facilitating asynchronous communication between different components of a software application, and its performance directly impacts the overall application's functionality.
The use of RabbitMQ queues tests involves confirming the correct routing and processing of messages, testing the system's behavior under various workloads, and ensuring that it can handle different failure scenarios. These tests provide a means to validate that messages are correctly published and consumed, that they persist as expected, and are correctly acknowledged or re-queued as needed.
Additionally, RabbitMQ queues tests are essential for evaluating how the system performs under high loads, with a large number of messages being sent to a queue. This helps in identifying potential bottlenecks and understanding the scalability of the system.
The tests also examine how RabbitMQ handles different message routing scenarios based on exchange types (direct, fanout, topic, headers) and routing keys. This ensures that messages are routed correctly to the appropriate queues.
If RabbitMQ is deployed in a clustered setup for high availability, the tests validate the cluster's ability to handle node failures and continue functioning, ensuring the messages remain available.
By carrying out these tests, system administrators and developers gain confidence in the reliability and performance of their RabbitMQ-based messaging system, ensuring it functions as expected under different scenarios. This is crucial for building robust applications and minimizing downtime or issues in production.
Summary
Most often contents of a queue are located on a single node within a cluster. When this node experiences any failures, it will affect customers who were dependent on that queue and its contents. So admins have to keep track of their queue’s status constantly.
Secondly having too many messages in a queue or each message being extra lengthy can all result in consuming much of your disk space. This will cause memory overhead and result in lag. You can limit this from happening by adjusting the message length, queue size and using TTL recovery mechanisms.
These measurements provide valuable insights into the behavior and performance of RabbitMQ queues. Monitoring these metrics helps identify potential issues, such as message overload, memory usage, queue state, and message acknowledgement rates.
By analyzing these measurements, administrators can take appropriate actions to optimize the system's performance, maintain high availability, and ensure smooth message processing in RabbitMQ.
Atatus API Monitoring and Observability
Atatus provides Powerful API Observability to help you debug and prevent API issues. It monitors the consumer experience and is notified when abnormalities or issues arise. You can deeply understand who is using your APIs, how they are used, and the payloads they are sending.
Atatus's user-centric API observability tracks how your actual customers experience your APIs and applications. Customers may easily get metrics on their quota usage, SLAs, and more.
It monitors the functionality, availability, and performance data of your internal, external, and third-party APIs to see how your actual users interact with the API in your application. It also validates rest APIs and keeps track of metrics like latency, response time, and other performance indicators to ensure your application runs smoothly.
#1 Solution for Logs, Traces & Metrics
![]() APM
APM
![]() Kubernetes
Kubernetes
![]() Logs
Logs
![]() Synthetics
Synthetics
![]() RUM
RUM
![]() Serverless
Serverless
![]() Security
Security
![]() More
More
