Understanding the Fallacies of Distributed Systems
Imagine you have a big, complex task to complete, but it's too much for one person to handle alone. So, you decide to break the task into smaller parts and ask your friends to help you. Each friend takes care of their assigned part independently, and when everyone finishes their part, the entire task is complete.
In the world of computers, a distributed system is similar to this idea. It's a way of organizing and managing tasks across multiple computers or servers, working together as a team to accomplish a bigger goal. Instead of relying on a single powerful computer to handle everything, a distributed system divides the work into smaller tasks and distributes them to different computers, which are often located in different physical locations.
Distributed systems are a fascinating and powerful approach to solving complex tasks by dividing them among multiple computers. However, they are not without their challenges. Over time, certain misconceptions, or fallacies, have emerged that can stumble even the most experienced developers.
In this blog, we will explore these fallacies one by one, explaining each in simple terms. We'll dive into the reasons behind these misconceptions, their potential impact on system design and performance, and most importantly, how to avoid falling into these traps.
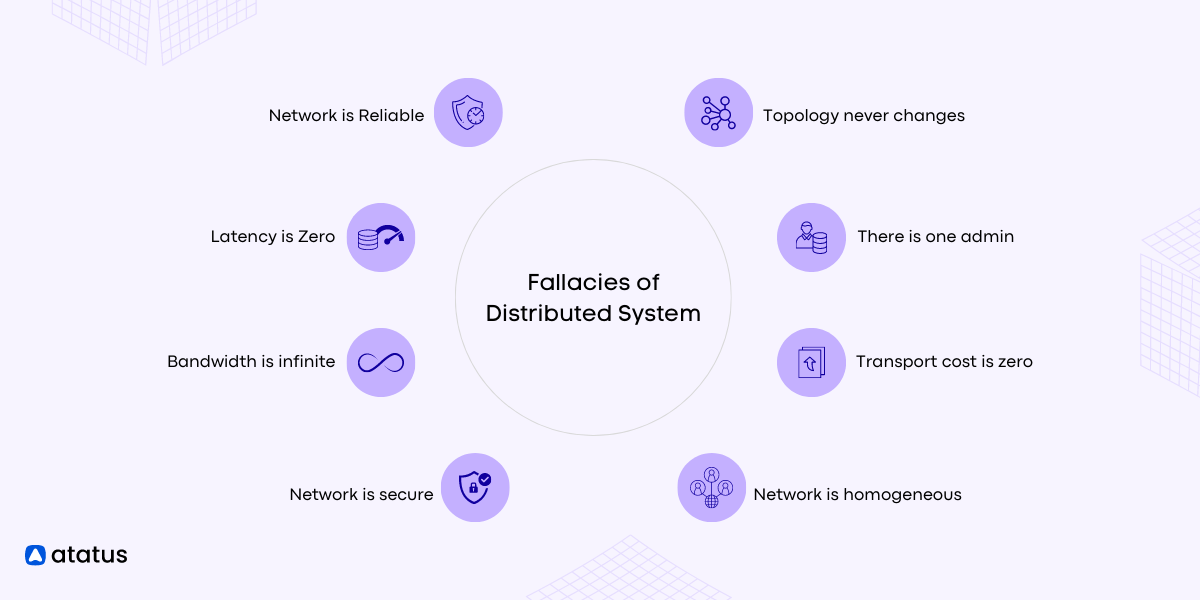
Fallacies of Distributed System
- Network is Reliable
- Latency is Zero
- Bandwidth is Infinite
- Network is Secure
- Topological Stability
- Zero Administration
- Infinite Scalability
- Homogeneity
1. Network is Reliable
Assumption: The network connecting components is always dependable and free from failures.
This fallacy assumes that the network has perfect reliability, meaning messages will always be delivered without errors or delays. It overlooks the fact that networks can experience outages, congestion, or packet losses, leading to service disruptions or data inconsistencies.
Creating a dependable distributed system involves acknowledging the inevitability of failures and integrating strategies to mitigate their effects. By proactively designing the system as below, you can easily withstand these challenges and it can continue operating smoothly even in the presence of unreliable networks.
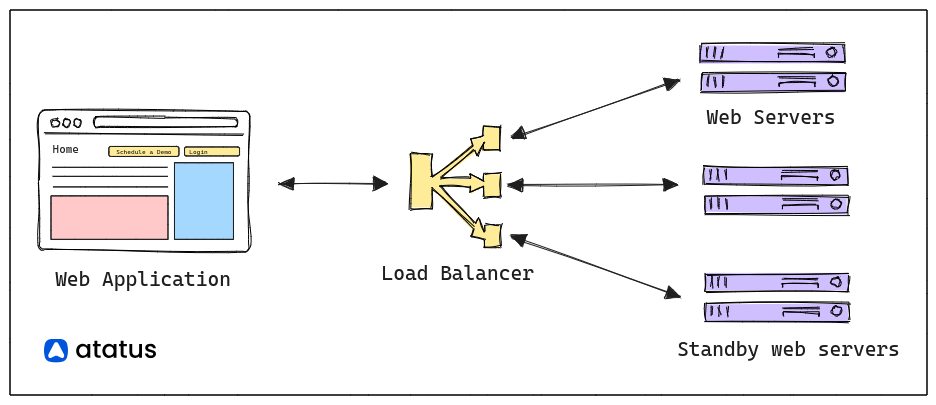
Example: Imagine a distributed application where a client sends a request to a server over the internet. The fallacy assumes that the request will always reach the server and the response will return to the client flawlessly, regardless of any network issues.
To overcome this fallacy, developers must implement strategies for handling network failures, such as redundancy, retries, and error handling. Building fault-tolerant systems that can gracefully degrade when network disruptions occur is crucial.
2. Latency is Zero
Assumption: Message transmission between components has no delay or negligible delay.
This fallacy assumes that the time taken for a message to travel from one component to another is virtually instantaneous. It disregards the inherent latency introduced by network communication, which can vary based on factors like distance, congestion, and processing time.
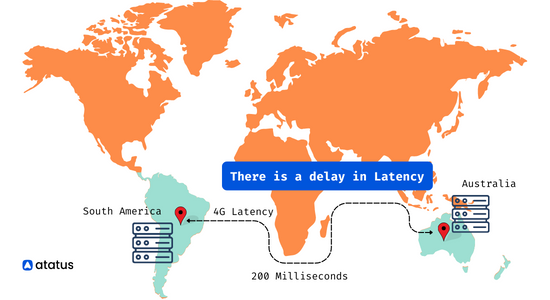
Example: In a distributed real-time gaming system, assuming that all players will experience zero latency when interacting with each other.
To overcome this fallacy, developers can use techniques such as caching, asynchronous communication, and content delivery networks (CDNs) to minimize the impact of latency. Designing applications with awareness of potential delays can also lead to better user experiences.
3. Bandwidth is Infinite
Assumption: There is an unlimited capacity for data transfer in the network.
This fallacy assumes that the network has an infinite capacity to transmit data, allowing for unrestricted data transfer between components. In reality, networks have finite bandwidth, and data-intensive operations can lead to congestion and reduced performance.
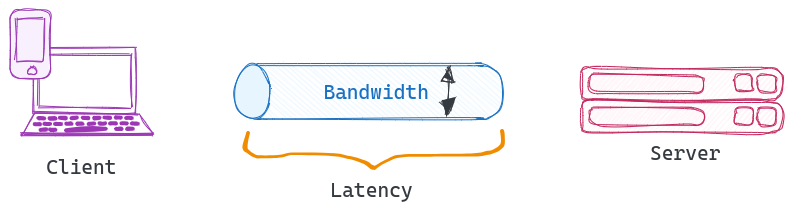
Example: Assuming that a distributed file-sharing system can transfer files of any size instantly without affecting other network traffic.
Developers can overcome this fallacy by optimizing data formats and compressing data when possible. Additionally, they should implement bandwidth management techniques, like throttling or traffic shaping, to ensure fair usage of network resources.
4. Network is Secure
Assumption: The network is protected from unauthorized access and security threats.
This fallacy assumes that the network connections and data transmission between components are inherently secure and free from eavesdropping or tampering. It disregards the need for proper authentication and encryption mechanisms.
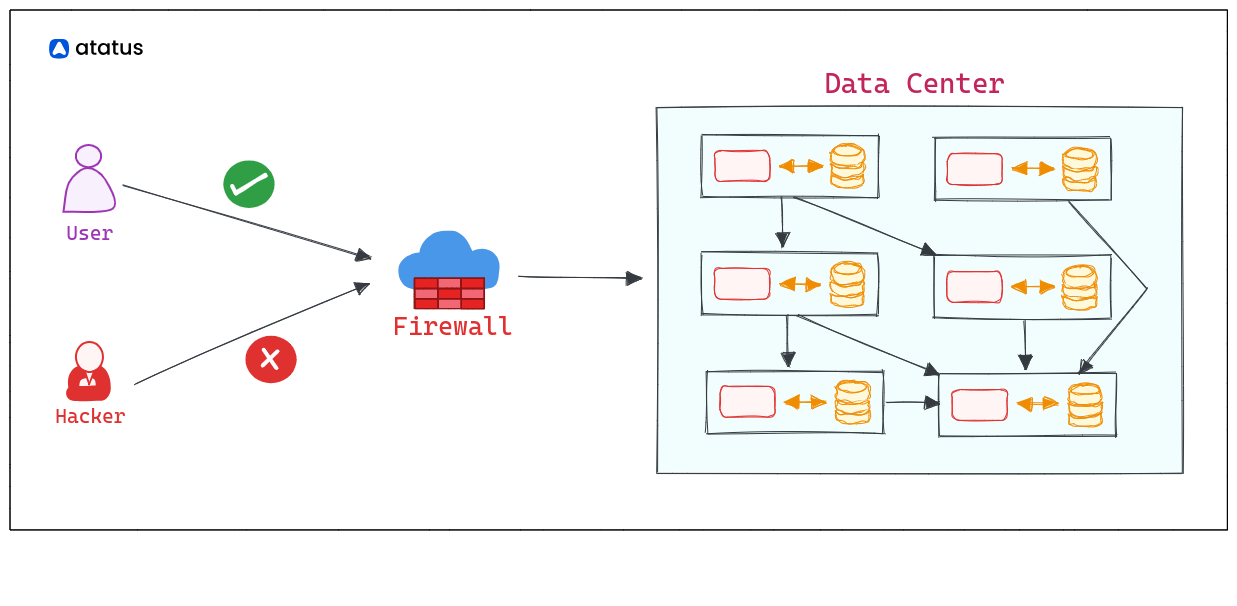
Example: Assuming that sending sensitive data between two components in a distributed system is safe without any encryption or authentication.
To overcome this fallacy, developers must implement strong security measures, such as using encrypted communication protocols (e.g., TLS/SSL), employing secure authentication mechanisms (e.g., OAuth, JWT), and implementing access controls to restrict unauthorized access.
5. Topological Stability
Assumption: The network topology remains fixed and consistent over time.
This fallacy assumes that the connections between components in a distributed system have a stable and unchanging topology. In reality, networks are dynamic, and components can join or leave the system, leading to shifts in the network structure.
As you design your distributed system, it's essential to avoid assuming a consistent and predictable network topology. Networks can vary in behavior, and different topologies offer distinct advantages and drawbacks.
For instance, in a ring topology, nodes form a circular connection, and data travels from one node to the next, with each node handling packets. Some benefits of a ring topology include:
- No need for a central node to manage connectivity.
- Relatively easy reconfiguration possibilities.
- Potential for full-duplex communication with a dual ring setup, enabling data flow in both directions.
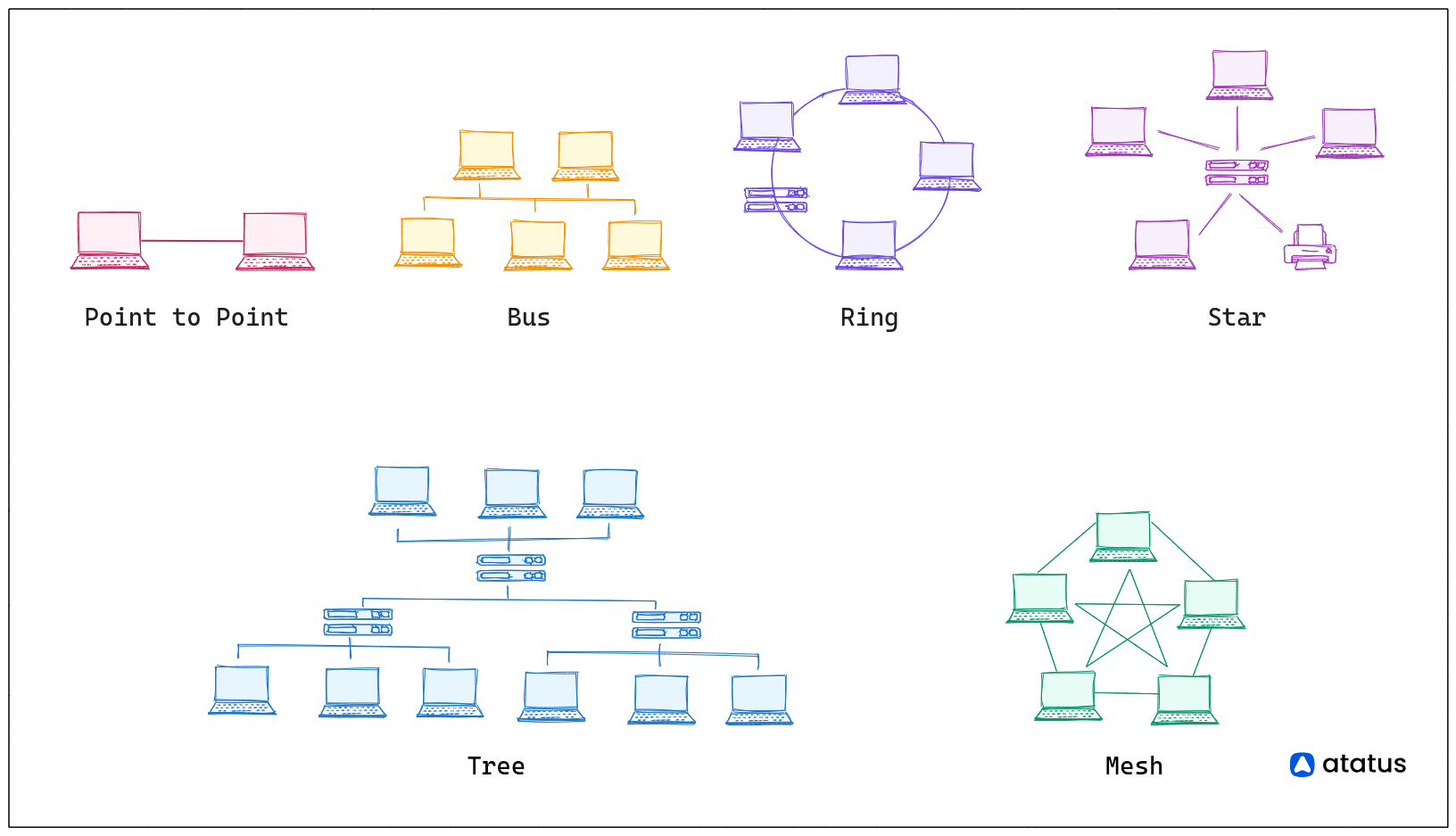
Now, let's consider another type of topology, the mesh topology. In a mesh topology, nodes are interconnected, creating multiple paths for data transmission. Mesh topologies use two main methods for data transfer:
- Routing: Nodes determine the shortest path from source to destination.
- Flooding: Information is sent to all nodes within the network.
To overcome this fallacy, developers can use dynamic discovery mechanisms, such as service registries or distributed consensus protocols, to adapt to changing network topologies. Components should be designed to handle node failures and updates gracefully.
6. Zero Administration
Assumption: The distributed system requires no administrative overhead and will manage itself seamlessly.
This fallacy assumes that a distributed system can operate autonomously without the need for ongoing administrative efforts, such as configuration management or monitoring.
Example: Assuming that a distributed database will optimize its own performance and automatically scale as data grows, without any intervention from administrators.
To overcome this fallacy, developers and administrators must implement effective monitoring and management tools, as well as automation for tasks like configuration, deployment, and scaling. However, it is essential to recognize that some administrative efforts will always be necessary to maintain a healthy distributed system.
7. Infinite Scalability
Assumption: The system can scale indefinitely without encountering challenges or limitations.
This fallacy assumes that a distributed system can handle an unlimited number of users, data, or requests without any constraints.
Example: Assuming that a web application can serve an infinite number of concurrent users without performance degradation.
To overcome this fallacy, developers should design systems for horizontal scalability, meaning they can add more servers or resources to handle increased load. Proper load balancing and resource management techniques should also be employed to achieve better scalability.
8. Homogeneity
Assumption: All components in the distributed system have the same properties and performance characteristics.
This fallacy assumes that all components in a distributed system are identical in terms of processing power, memory, and other capabilities. It overlooks the reality that distributed systems often involve various types of devices and hardware with differing capacities.
Example: Assuming that all servers in a cluster have the same processing speed and memory capacity, leading to equal performance.
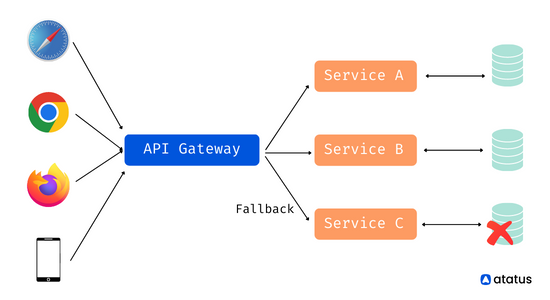
When developing an application, it is crucial to ensure the robustness and reliability of your services. To achieve this, consider implementing essential design patterns such as the Circuit Breaker Pattern, Retry Design Pattern, and Timeout Design Pattern. These patterns will enhance the resilience and fault tolerance of your services, helping them handle unexpected situations and recover gracefully from failures.
Additionally, developers must account for heterogeneity in the distributed system. Load balancing and resource allocation strategies can be implemented to ensure that tasks are distributed effectively based on the capabilities of each component. Performance optimization should be tailored to each component's specific capabilities.
Conclusion
Understanding and acknowledging the fallacies of distributed systems is essential for building successful and resilient applications. The assumptions of a reliable network, zero latency, infinite bandwidth, and other ideal conditions can lead to significant challenges in real-world deployments.
By embracing the realities of distributed environments and implementing appropriate strategies, such as redundancy, fault tolerance, and security measures, developers can create distributed systems that thrive in the face of network uncertainties.
Remember, a well-designed distributed system takes into account the inherent complexities of the network, ensuring a smoother and more reliable experience for users and administrators alike. So, embrace the fallacies, overcome the challenges, and build distributed systems that stand strong in the dynamic world of networks.
Monitor Your Entire Application with Atatus
Atatus is a Full Stack Observability Platform that lets you review problems as if they happened in your application. Instead of guessing why errors happen or asking users for screenshots and log dumps, Atatus lets you replay the session to quickly understand what went wrong.
We offer Application Performance Monitoring, Real User Monitoring, Server Monitoring, Logs Monitoring, Synthetic Monitoring, Uptime Monitoring, and API Analytics. It works perfectly with any application, regardless of framework, and has plugins.
Atatus can be beneficial to your business, which provides a comprehensive view of your application, including how it works, where performance bottlenecks exist, which users are most impacted, and which errors break your code for your frontend, backend, and infrastructure.
If you are not yet an Atatus customer, you can sign up for a 14-day free trial.
#1 Solution for Logs, Traces & Metrics
![]() APM
APM
![]() Kubernetes
Kubernetes
![]() Logs
Logs
![]() Synthetics
Synthetics
![]() RUM
RUM
![]() Serverless
Serverless
![]() Security
Security
![]() More
More
