Relational Databases: Exploring Indexes and Transactions
Indexes serve as the key to unlocking the immense potential of relational databases, enabling swift and optimized data access.
They act as a roadmap, allowing the database engine to locate specific data quickly, ultimately enhancing query performance. Understanding the nuances of indexes and employing the appropriate indexing techniques can significantly impact the efficiency of a database system.
Transactions, on the other hand, play a vital role in ensuring data integrity and consistency in a multi-user environment. As users simultaneously access and modify data, transactions act as a protective shield, preventing data corruption and maintaining the reliability of the database.
Delving into the intricacies of transactions, we explore their properties, isolation levels, and the ACID (Atomicity, Consistency, Isolation, Durability) principles that govern their execution.
Throughout this article, we aim to provide a comprehensive overview of indexes and transactions, highlighting their significance in optimizing database performance and ensuring data reliability. So, let’s get started!
Table Of Contents
- Why do we need Indexes?
- What is a Transaction?
- ACID properties of Transactional Databases
- Read Phenomenon
Why do we need Indexes?
Indexes allow for quick access to specific rows or ranges of data within a table. By creating an index on one or more columns, the database engine can use the index to locate the desired data directly, bypassing the need to scan the entire table. This significantly reduces the time required to retrieve data, especially when dealing with large datasets.
Indexes can dramatically improve the performance of queries by providing the database optimizer with valuable information about the data distribution and organization. With this knowledge, the optimizer can choose the most efficient execution plan, such as utilizing index scans or index seeks, resulting in faster query execution times.
Indexes can also enforce constraints such as primary key and unique key constraints. These constraints ensure data integrity by preventing the insertion of duplicate values or null values in critical columns.
Indexes reduce the number of disk I/O operations required to fetch data. Instead of scanning the entire table, the database engine can utilize the index structure to access only the necessary data pages, resulting in reduced disk I/O and improved overall system performance.
Index Leaf Nodes
Index leaf nodes, also known as leaf pages or leaf blocks, are the bottom level of an index structure in a relational database. They contain the actual data values or references to the data rows associated with the indexed column(s). Each leaf node corresponds to a specific key value or range of key values.
Here's an example to illustrate index leaf nodes:
Assuming we have created an index on the "Department" column, the index leaf nodes for this table will look like this:
Index: Department
In this example, the index leaf nodes store the distinct department values from the "Department" column and the corresponding pointers to the data rows where the department information is stored. Each leaf node entry represents a specific key value (department) and points to the associated data row.
For instance, in the index leaf node entry with the key value "Marketing," there are two pointers, pointing to the data rows with EmployeeIDs 2 and 5, respectively. Similarly, the leaf node entry for "Sales" points to the data rows with EmployeeIDs 1 and 3.
By organizing the data in index leaf nodes, the database engine can efficiently locate the desired data rows by performing index scans or seeks, greatly improving the speed and efficiency of data retrieval operations.
Linked lists
A linked list is a fundamental data structure consisting of a sequence of nodes, where each node contains a value and a reference (or link) to the next node in the sequence. It provides a flexible way to store and manipulate data dynamically, as elements can be easily inserted, removed, or accessed.
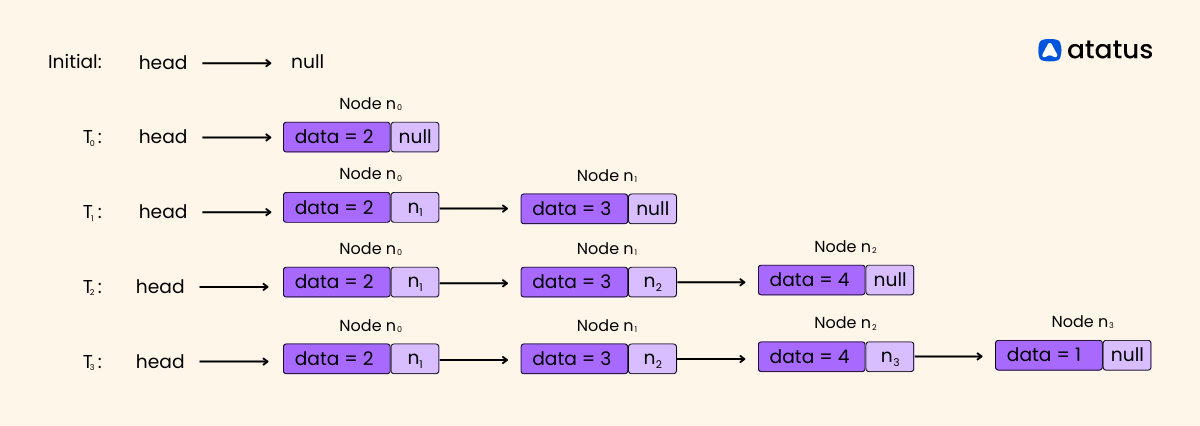
Consider a simple linked list representing a list of names in a particular order:
Node 1: "John" -> Node 2: "Jane" -> Node 3: "Robert" -> Node 4: "Lisa" -> nullIn this example, each node contains two parts: the value (a name) and the reference (or link) to the next node. The arrow "->" represents the link between nodes. The last node in the list, "Lisa," points to null, indicating the end of the list.
To access elements in a linked list, you start from the head of the list (the first node) and follow the links until you reach the desired node. For instance, to access the third element, "Robert," you would start from the head and follow the links to Node 3.
Linked lists allow for efficient insertion and deletion of elements. For example, let's say we want to insert a new name, "Michael," between "Jane" and "Robert":
Node 1: "John" -> Node 2: "Jane" -> Node 5: "Michael" -> Node 3: "Robert" -> Node 4: "Lisa" -> nullTo achieve this, we create a new node, Node 5, with the value "Michael" and update the links. Node 2 now points to Node 5, and Node 5 points to Node 3.
Similarly, deleting an element involves updating the links. Suppose we remove "Robert" from the list:
Node 1: "John" -> Node 2: "Jane" -> Node 4: "Lisa" -> nullIn this case, Node 2's link is updated to skip Node 3, effectively removing it from the list.
Linked lists are advantageous in scenarios where dynamic data manipulation, such as frequent insertions or deletions, is required. Unlike arrays, linked lists can easily accommodate changes in size without requiring a complete reallocation of memory.
However, one drawback of linked lists is that accessing elements by index (e.g., the nth element) can be less efficient compared to arrays, as you must traverse the list from the head to reach the desired node.
Balanced Trees
Balanced trees, specifically balanced search trees like B-trees and AVL trees, play a crucial role in relational databases by providing efficient and balanced storage structures for indexing and searching data. These trees ensure optimal performance for operations like data insertion, deletion, and retrieval, regardless of the data distribution.
Consider a database table named "Customers" with millions of rows, each representing a customer record. One of the commonly used columns for searching and querying data is the "CustomerID." To efficiently retrieve customer records based on their IDs, an index structure is created on the "CustomerID" column.
If a simple unbalanced tree, like a binary search tree, were used for indexing, the tree's structure could become skewed if the IDs are inserted in a specific order (e.g., ascending or descending). This skewed structure leads to poor search performance, with some operations requiring traversing a large number of levels in the tree, leading to increased time complexity.
However, a balanced tree, such as a B-tree or AVL tree, addresses this issue by ensuring the tree remains balanced regardless of the order of insertion. These trees maintain a specific balance factor or height constraint that guarantees a balanced distribution of data across the tree's levels.
For instance, a B-tree might have a balance factor that allows a certain range of keys in each node and requires all leaf nodes to be at the same level. With this structure, the database engine can efficiently search for a specific CustomerID by traversing the tree in a logarithmic time complexity, irrespective of the data distribution or the number of records.
Let's say we have a B-tree index on the "CustomerID" column:
B-tree Index: CustomerID
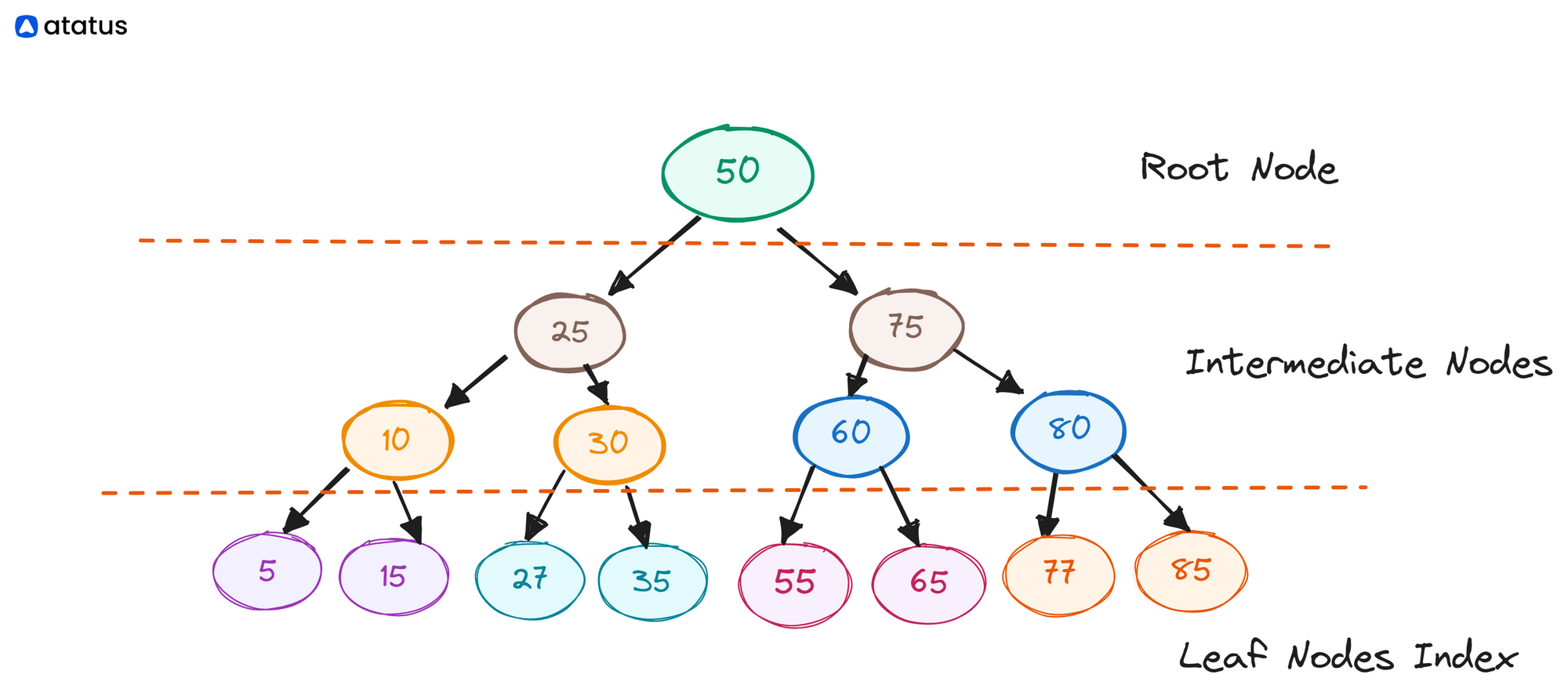
In this example, the B-tree structure ensures a balanced distribution of CustomerIDs across the tree's levels. When searching for a specific CustomerID, the database engine starts from the root and follows the appropriate branches based on the comparison with the target value, efficiently narrowing down the search space.
The balanced tree structure ensures that the height of the tree remains small, reducing the number of disk I/O operations required to access data. This leads to improved query performance, faster data retrieval, and overall efficient management of the indexed data in the relational database.
What is a Transaction?
A transaction in a relational database is a logical unit of work that consists of multiple database operations, typically including one or more data modifications (such as insert, update, or delete) and data retrieval (select) operations. Transactions ensure the integrity and consistency of data by enforcing the ACID properties. Let's delve into the key components of a transaction:
1. Begin
The "Begin" step marks the start of a transaction. It defines the boundary within which a set of related database operations will be treated as a single unit.
Once a transaction begins, any subsequent changes made to the database are isolated from other concurrent transactions until the transaction is completed.
BEGIN;2. Commit
The "Commit" step signifies the successful completion of a transaction. When a transaction is committed, all the changes made within the transaction are permanently saved to the database, making them visible to other transactions.
At this point, the database ensures that the transaction's changes are durable and will survive future system failures.
COMMIT;3. Rollback
The "Rollback" step is used to abort or cancel a transaction and revert any changes made within the transaction to their previous state.
It is typically invoked when an error or exceptional condition occurs during the transaction or when the transaction fails to meet certain criteria or constraints.
When a rollback is executed, all the modifications made within the transaction are undone, and the database is restored to its state before the transaction began.
ROLLBACK;Example:
Let's create an example using all three statements (`BEGIN`, ROLLBACK, and COMMIT) for a transaction involving two tables in SQL: Employees and SalaryChanges. The SalaryChanges table will be used to log the changes made to the employees' salaries during the transaction.
-- Check if the salary change for EmployeeID 1234 is greater than 10000
DECLARE SalaryChangeAmount INT;
SET SalaryChangeAmount = (SELECT Salary - (Salary - 5000) FROM Employees WHERE EmployeeID = 1234);
-- Start the transaction
BEGIN;
-- Check if the salary change is greater than 10000
IF SalaryChangeAmount > 10000 THEN
-- If the salary change is too high, rollback the transaction
ROLLBACK;
SELECT 'Salary change exceeds the threshold. Transaction rolled back.' AS Message;
ELSE
-- If the salary change is within the threshold, commit the transaction
COMMIT;
SELECT 'Transaction committed successfully.' AS Message;
END IF;
ACID Properties of Transactional Databases
The ACID properties, which stand for Atomicity, Consistency, Isolation, and Durability, are a set of fundamental principles that ensure the reliability, integrity, and consistency of transactions in a database management system. Let's explore each of these properties:
1. Atomicity
Atomicity guarantees that a transaction is treated as an indivisible and irreducible unit of work. It ensures that either all the operations within a transaction are successfully completed, or none of them are performed at all.
If any operation within the transaction fails or encounters an error, the entire transaction is rolled back, and all changes made within the transaction are undone. Atomicity helps maintain the consistency of the database by preventing partial or incomplete updates.
Example: Transfer money between two accounts (Savings and Checking) in a single transaction. If any of the updates fail (e.g., insufficient balance), the entire transaction will be rolled back, and no money will be transferred.
-- Begin the transaction
BEGIN;
-- Step 1: Withdraw $100 from Account A
UPDATE Accounts
SET Balance = Balance - 100
WHERE AccountNumber = 'A';
-- Step 2: Deposit $100 into Account B
UPDATE Accounts
SET Balance = Balance + 100
WHERE AccountNumber = 'B';
-- Commit the transaction
COMMIT;2. Consistency
Consistency ensures that a transaction brings the database from one consistent state to another consistent state. It enforces integrity constraints, domain rules, and predefined consistency rules during transaction execution.
In other words, a transaction should not violate any integrity constraints or leave the database in an inconsistent state. If a transaction violates any constraints, it is rolled back, and the database remains unchanged.
Example: Before processing the transaction, we check if both accounts exist in the database. If any of the accounts are missing, the transaction is rolled back, ensuring consistency.
-- Begin the transaction
BEGIN;
-- Check if both accounts exist
IF (SELECT COUNT(*) FROM Accounts WHERE AccountNumber IN ('A', 'B')) = 2
BEGIN
-- Step 1: Withdraw $100 from Account A
UPDATE Accounts
SET Balance = Balance - 100
WHERE AccountNumber = 'A';
-- Step 2: Deposit $100 into Account B
UPDATE Accounts
SET Balance = Balance + 100
WHERE AccountNumber = 'B';
-- Commit the transaction
COMMIT;
END
ELSE
BEGIN
-- Roll back the transaction if any account does not exist
ROLLBACK;
PRINT 'Invalid account(s). Transaction canceled.';
END3. Isolation
Isolation guarantees that each transaction is executed in isolation from other concurrent transactions. It ensures that the intermediate state of a transaction is invisible to other transactions until it is committed.
Isolation prevents interference or conflicts between concurrent transactions, maintaining data integrity and preventing anomalies such as dirty reads, non-repeatable reads, and phantom reads.
Different isolation levels, such as Read Uncommitted, Read Committed, Repeatable Read, and Serializable, offer varying degrees of isolation based on the specific requirements of the application.
Example: Ensure that each customer's transaction is independent, and only one of them will successfully transfer the money.
-- Customer 1 attempts to transfer money
START TRANSACTION;
-- Step 1: Withdraw $100 from Account A
UPDATE Accounts
SET Balance = Balance - 100
WHERE AccountNumber = 'A';
-- Step 2: Deposit $100 into Account B
UPDATE Accounts
SET Balance = Balance + 100
WHERE AccountNumber = 'B';
-- Commit the transaction for Customer 1
COMMIT;
-- Customer 2 attempts to transfer money
START TRANSACTION;
-- Step 1: Withdraw $50 from Account A
UPDATE Accounts
SET Balance = Balance - 50
WHERE AccountNumber = 'A';
-- Step 2: Deposit $50 into Account B
UPDATE Accounts
SET Balance = Balance + 50
WHERE AccountNumber = 'B';
-- Commit the transaction for Customer 2
COMMIT;4. Durability
Durability ensures that once a transaction is committed, its changes are permanent and will survive even in the event of a system failure or restart.
The committed data is stored in a non-volatile storage medium (such as disk) and can be recovered in case of a system crash or power failure.
Durability guarantees that the effects of committed transactions are persistent and can be relied upon even in the face of unforeseen circumstances.
Example: Transferring $100 from "Account A" to "Account B." After committing the transaction, the changes to the account balances are durable and will be retained, even in case of system failures or crashes.
-- Begin the transaction
BEGIN;
-- Step 1: Withdraw $100 from Account A
UPDATE Accounts
SET Balance = Balance - 100
WHERE AccountNumber = 'A';
-- Step 2: Deposit $100 into Account B
UPDATE Accounts
SET Balance = Balance + 100
WHERE AccountNumber = 'B';
-- Commit the transaction
COMMIT;
-- The changes are now durable and permanent, even in case of system failures or crashes.Read Phenomenon
Non-repeatable reads is an anomaly that can occur in a multi-user database environment when one transaction reads a row multiple times and obtains different values each time due to other concurrent transactions modifying the data. It arises when the isolation level of the transaction allows for reading uncommitted or modified data by other transactions. This phenomenon can lead to inconsistent or unexpected results.
Consider a database table named "Orders" with the following columns:
Suppose there are two concurrent transactions: Transaction A and Transaction B.
Transaction A:
- Transaction A reads the "TotalAmount" of OrderID 1 and obtains the value 500.
- Meanwhile, Transaction B updates the "TotalAmount" of OrderID 1 to 550.
- Transaction A reads the "TotalAmount" of OrderID 1 again and now obtains the updated value of 550.
In this scenario, Transaction A encountered a non-repeatable read. When it initially read the "TotalAmount" of OrderID 1, it obtained a value of 500. However, when it performed the same read later, it obtained a different value of 550. The inconsistency is caused by Transaction B modifying the data between the two reads performed by Transaction A.
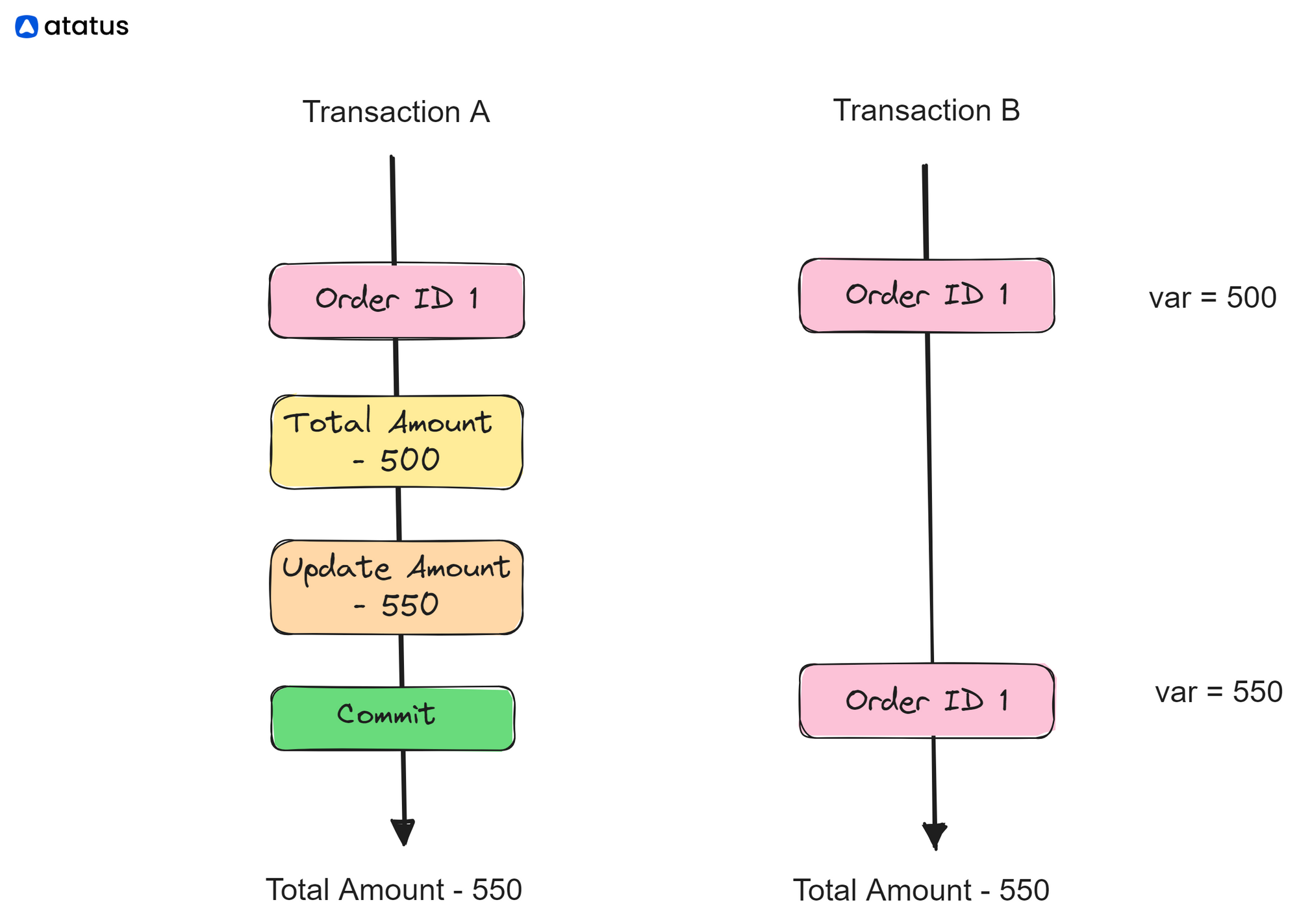
Non-repeatable reads can lead to unexpected behavior and data inconsistency, as the values obtained in different reads may not be consistent with each other. This can pose challenges when transactions rely on the assumption that the data they read will remain unchanged during their execution.
To mitigate non-repeatable reads, higher isolation levels, such as Serializable, can be used, which provide stronger guarantees of data consistency by ensuring that transactions have exclusive access to the data they read until they are completed. However, higher isolation levels may introduce other performance trade-offs, such as increased locking and reduced concurrency.
Phantom Reads
Phantom reads occur when a transaction retrieves a set of rows based on a certain condition, but during a subsequent read, the number of rows meeting that condition changes due to other committed transactions inserting or deleting data.
Transaction A:
- Transaction A retrieves all rows from the "Orders" table where the TotalAmount is greater than 600.
Transaction B:
- Transaction B inserts a new row into the "Orders" table with a TotalAmount of 700.
- Transaction B commits the insertion.
Transaction A (Continued):
- Transaction A re-executes the retrieval query and finds an additional row that didn't exist in the previous read.
Here, Transaction A initially reads all rows where the TotalAmount is greater than 600. However, after Transaction B inserts a new row with a TotalAmount of 700, the subsequent read by Transaction A includes the newly inserted row, resulting in a phantom read.
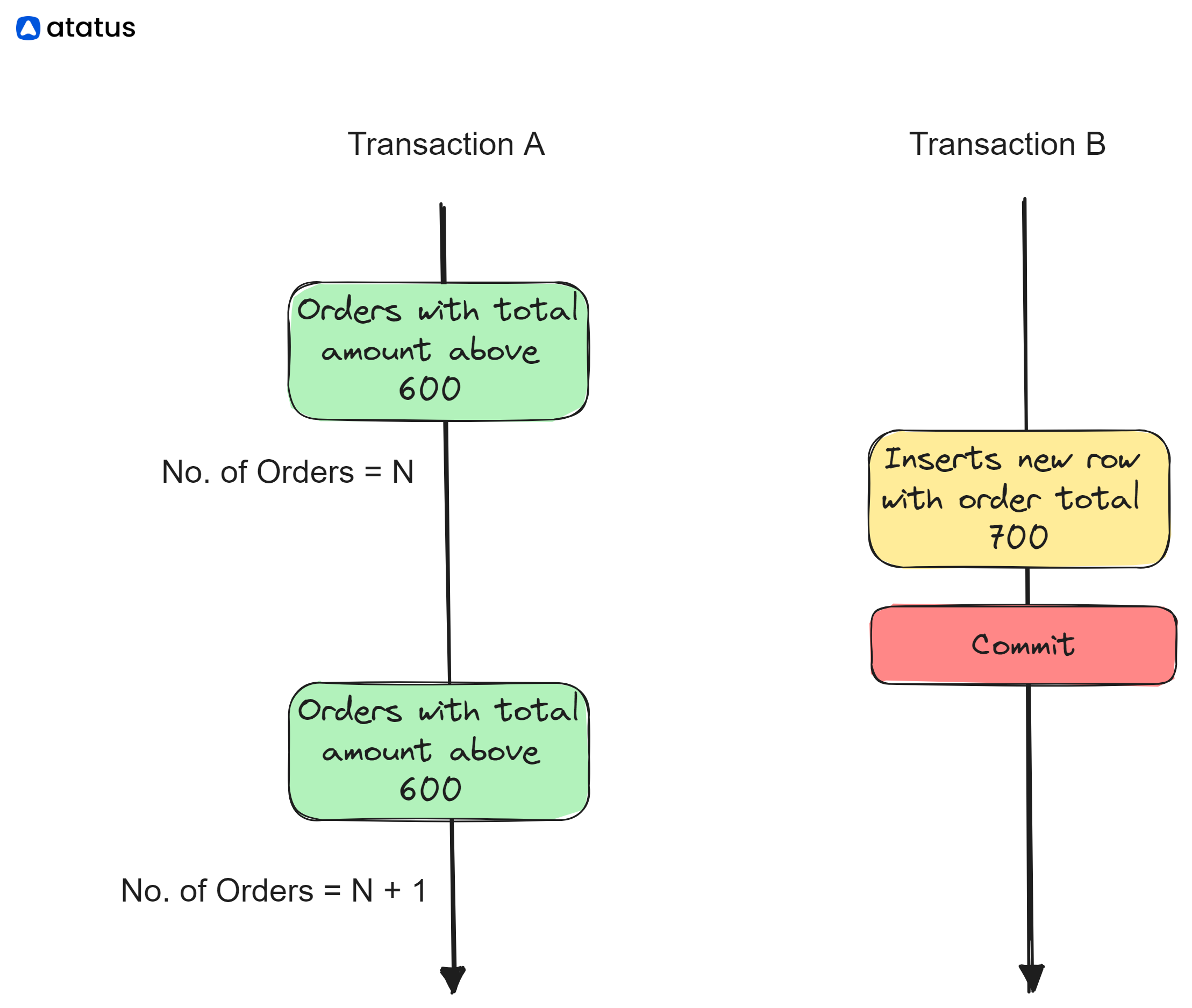
Dirty Reads
Dirty reads occur when a transaction reads uncommitted data from another transaction that hasn't been finalized (committed or rolled back) yet. This can happen under lower isolation levels.
Transaction A:
- Transaction A retrieves the "TotalAmount" of OrderID 1 and obtains the value 500.
Transaction B:
- Transaction B updates the "TotalAmount" of OrderID 1 to 600 but hasn't committed yet.
Transaction A (Continued):
- Transaction A reads the "TotalAmount" of OrderID 1 again and obtains the updated value of 600, which is the uncommitted data from Transaction B.
Here, Transaction A reads the uncommitted data modified by Transaction B before Transaction B has committed. This represents a dirty read since the data being read might not be finalized or consistent.
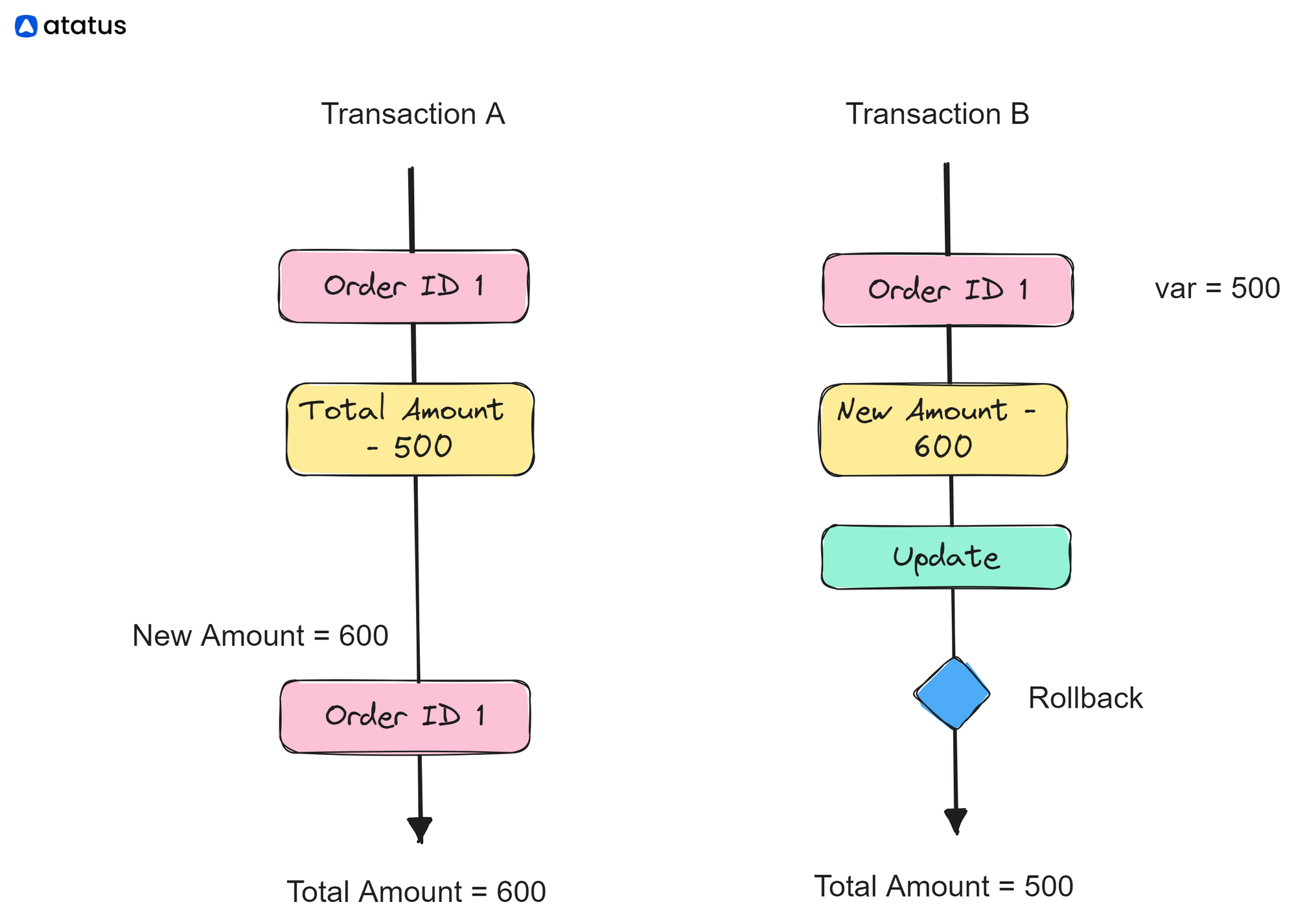
Conclusion
The exploration of indexes and transactions has emphasized the importance of these concepts in relational databases.
Armed with a deeper understanding of these fundamental components, database administrators, developers, and technology enthusiasts can make informed decisions in designing, implementing, and maintaining robust database systems that meet the ever-growing demands of today's data-driven world.
Database Monitoring with Atatus
Atatus provides you an in-depth perspective of your database performance by uncovering slow database queries that occur within your requests, and transaction traces to give you actionable insights. With normalized queries, you can see a list of all slow SQL calls to see which tables and operations have the most impact, know exactly which function was used and when it was performed, and see if your modifications improve performance over time.
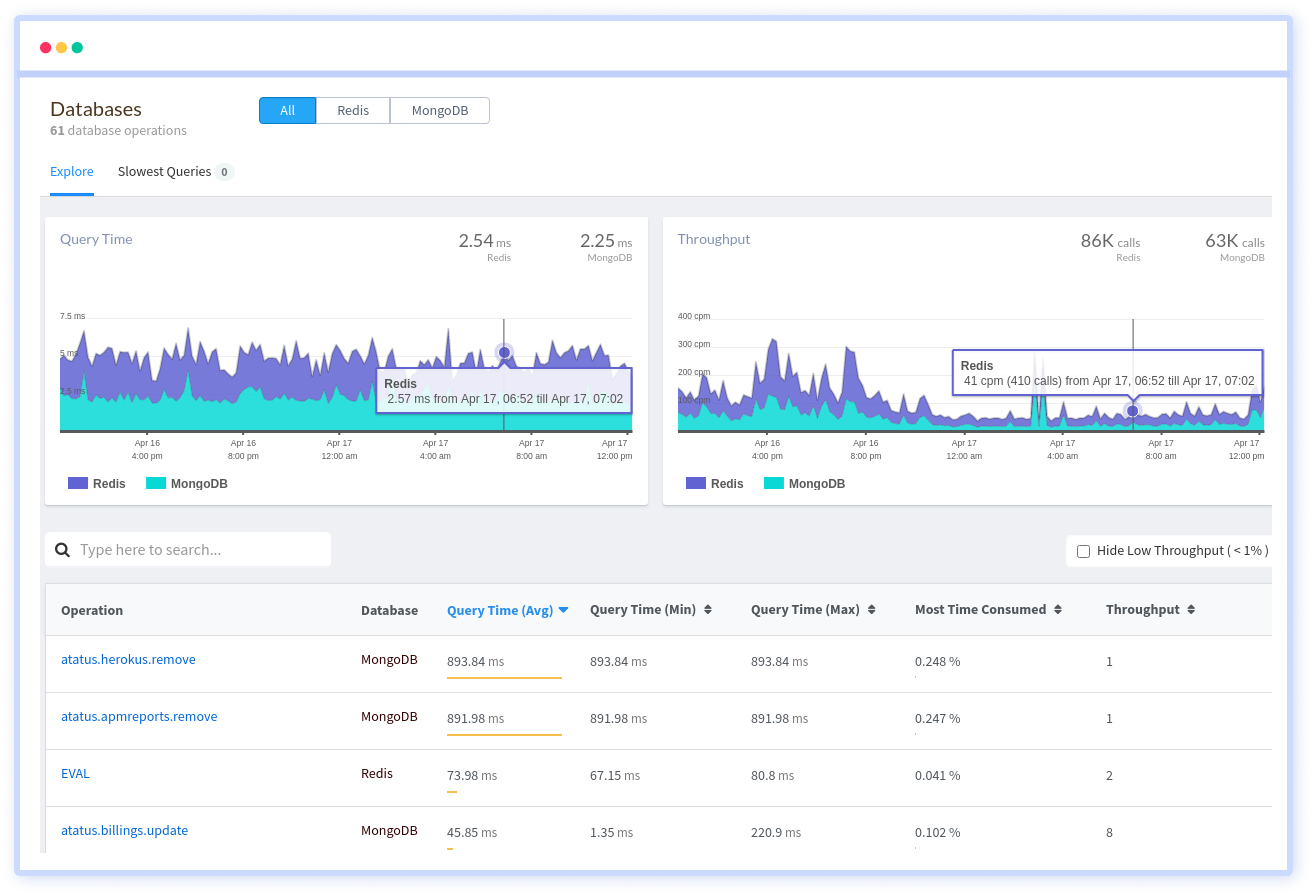
Atatus benefit your business, providing a comprehensive view of your application, including how it works, where performance bottlenecks exist, which users are most impacted, and which errors break your code for your frontend, backend, and infrastructure.
#1 Solution for Logs, Traces & Metrics
![]() APM
APM
![]() Kubernetes
Kubernetes
![]() Logs
Logs
![]() Synthetics
Synthetics
![]() RUM
RUM
![]() Serverless
Serverless
![]() Security
Security
![]() More
More
