Mastering Kubernetes Pod Restarts with kubectl

Managing containerized applications efficiently in the dynamic realm of Kubernetes is essential for smooth deployments and optimal performance.
Kubernetes empowers us with powerful orchestration capabilities, enabling seamless scaling and deployment of applications.
However, in real-world scenarios, there are situations that necessitate the restarting of Pods, whether to apply configuration changes, recover from failures, or address misbehaving applications.
In this blog, we will explore the art of restarting Kubernetes Pods using the versatile kubectl command-line tool. As a core component of Kubernetes, Pods play a vital role in running containers and must continue to function until gracefully replaced.
We'll learn how to effectively use kubectl to handle Pod restarts in various scenarios, ensuring the continuous operation of your containerized workloads.
Let's dive into the world of Kubernetes Pod restarts and master the techniques to overcome unexpected challenges with kubectl's powerful functionalities.
- Instances Requiring Kubernetes Pod Restart
- Kubernetes Pod States
- Kubernetes Pod Restart Policy
- Restarting Kubernetes Pods with kubectl
Instances Requiring Kubernetes Pod Restart
A pod may also contain one or more containers, one of which is the application container. The other two containers are the init container and the sidecar container, which are attached to the primary application container and stop running when they have finished their tasks or the application container is prepared to perform its function.
A failed entry does not always result in a container or pod leaving. You will need to specifically restart your Kubernetes Pod in situations like this.
There are a number of circumstances where you might need to restore a pod:
- Unexpected errors like
"Pods trapped in an inactive state"(e.g., pending),"Out of Memory"(occurs when pods attempt to use more memory than is allowed by the manifest file you are using), etc. - If you earlier set the
PodSpec imagePullPolicytoAlways, you can quickly upgrade a Pod with a freshly-pushed container image.to change secrets and configurations. - When an application operating in a pod has a corrupted internal state that needs to be cleared, you should restart the pod.
- You've now seen some situations where restarting a Pod might be necessary. You will then discover how to use kubectl to restore Pods.
Kubernetes Pod States
There are five potential states for a pod:
- Pending: This status indicates that at least one pod object has not yet been generated.
- Running: The module has been connected to a Node, and all containers have been generated. The containers are currently operating, starting, or restarting.
- Succeeded: All of the pod's containers have been ended properly and won't be restarted.
- Failed: At least one container has failed, and all containers have been stopped. There is a non-zero condition for the unsuccessful container.
- Unknown: It is impossible to learn the pod's condition.
The pod resume policy, which is a component of the Kubernetes pod template, will be discussed. Following that, we'll demonstrate how to directly restart a pod using kubectl.
Kubernetes Pod Restart Policy
In Kubernetes, the lifecycle of a Pod progresses through several stages, starting from "pending" when it is being scheduled and transitioning to "running" once the main containers are successfully started. Depending on the success or failure of the containers, the Pod moves to the "succeeded" or "failed" state.
The kubelet, the Kubernetes node agent, has the ability to automatically restart each container within a running Pod to address specific issues. Kubernetes continuously monitors the status of containers within Pods and takes appropriate actions to restore the node's health.
However, a Pod cannot heal itself in certain situations, such as when the node hosting it fails or during node maintenance or evictions due to resource constraints. In these cases, Kubernetes may remove the Pod.
To control the restart behavior of containers within a Pod, the restartPolicy property is used in the Pod specification. There are three possible settings for this policy:
Always: The default setting. The Pod should always remain active, so whenever a container terminates, Kubernetes starts a new one automatically.OnFailure: The container is only restarted if it exits with a non-zero return value, indicating a failure. Successful exits with a return value of 0 do not trigger a restart.Never: The container is never restarted automatically, even if it terminates.
To demonstrate the restartPolicy in action, consider the following example:
apiVersion: batch/v1
kind: Job
metadata:
name: demo-restartPolicy-job
spec:
backoffLimit: 2
template:
metadata:
name: demo-restartPolicy-pod
spec:
restartPolicy: OnFailure
containers:
- name: demo
image: sonarsource/sonar-scanner-cliIn this example, the demo container will be restarted only if it fails (i.e., returns a non-zero exit status) due to the specified restartPolicy of OnFailure.
Restarting Kubernetes Pods with kubectl
By design, there is no straight instruction in kubectl for restarting pods. Due to this, you must use one of the following techniques to resume Pods with kubectl:
- Scaling Replicas to Trigger Pod Restart
- Rolling Update Restart
- Automatically Restarting Kubernetes Pods
- Delete and Let Replicas Create New Pods
Prerequisites
Make sure you have the following requirements before learning how to use each of the aforementioned techniques:
- A single node kubernetes cluster called minikube was used for the demonstration in this essay.
- The command-line utility
kubectlis set up to talk to the network.
Create a httpd-deployment.yaml file for demonstration reasons in any preferred directory with replicas set to 2 using the YAML settings below:
apiVersion: apps/v1
kind: Deployment
metadata:
name: httpd-deployment
labels:
app: httpd
spec:
replicas: 2
selector:
matchLabels:
app: httpd
template:
metadata:
labels:
app: httpd
spec:
containers:
- name: httpd-pod
image: httpd:latest
Run the following commands in your console after navigating to the distribution file's storage location.
kubectl apply -f httpd-deployment.yamlTwo pods will be created for the httpd rollout by the aforementioned instruction. Use the kubectl get pods command to check the amount of Pods.
The httpd deployment's pods are currently operating. The Kubernetes pods will then be restarted using each of the aforementioned techniques.
1. Scaling Replicas to Trigger Pod Restart
When you scale down the replicas of a deployment to zero, it effectively deletes all the Pods associated with that deployment. When you subsequently scale up the replicas, Kubernetes creates new Pods with the updated configuration, effectively restarting the Pods.
Setting the number of replicas to zero will lead to the termination of all existing Pods, causing downtime or application delay. This approach is generally used for planned maintenance or when you need to start fresh Pods with updated configurations.
Use the kubectl scale command to scale back the httpd distribution copies you made:
kubectl scale deployment httpd-deployment --replicas=0This command scales down the httpd-deployment to zero replicas, effectively stopping and terminating all the Pods.
After executing the kubectl scale command to set the replicas to zero, running kubectl get pods will show that there are no Pods running in the default namespace since all the Pods were terminated.
Run the same version of kubectl scale, but this time, specify --replicas=2 to scale up the replicas.
kubectl scale deployment httpd-deployment --replicas=2This command scales up the httpd-deployment to two replicas, creating two new Pods with the updated configuration.
Run the following command after executing the one above to confirm the number of active pods:
kubectl get podsAfter scaling up to two replicas, running kubectl get pods will show that there are two active Pods, and they should be running and operational.
2. Rolling Update Restart
It's important to note that scaling the number of copies to zero is not a recommended approach to restore Pods. Scaling replicas to zero means deleting all the Pods, which can lead to service downtime and interruption. This approach is generally not used for restoring Pods.
Instead, the "Rollout Restart" technique provides a better approach for restarting Pods without service interruption.
Use the kubectl rollout restart command to resume without any interruption or downtime, which restarts the Pods one at a time without affecting the service distribution.
Run this command to apply the rollout restart to your httpd deployment:
kubectl rollout restart deployment httpd-deploymentThe kubectl rollout restart command triggers a rolling update for the specified deployment. It gracefully restarts Pods one at a time, ensuring that the service remains available during the restart process.
Run this command to see the Pods restarting.
kubectl get podsWhen you execute the kubectl rollout restart command, you can use kubectl get pods to observe the rolling update process in action.
During a rolling update, Kubernetes creates new Pods with the updated configuration and waits for them to reach the "Running" state before terminating the old Pods. This strategy ensures that the service remains available throughout the update process, and there is no significant downtime or delay.
3. Automatically Restarting Kubernetes Pods
You've now learned how to restart Pods in Kubernetes using two different methods: rolling updates and scaling replicas. Although both methods result in functioning pods, they achieve the restart process in different ways.
To demonstrate an example of how pods can be restarted by updating environment variables, we can use the following steps:
Step:1 - Run the following command to change the Pods' environment settings for your httpd deployment:
kubectl set env deployment httpd-deployment DATE=2023-08-03
Step:2 - Run kubectl get pods after executing the aforementioned command to observe the current status of the pods. However, please note that changing the environment variable alone will not immediately trigger pod restarts.
Step:3 - If the application inside the pods uses the updated DATE environment variable and detects the change, it may decide to restart automatically. Otherwise, the pods will continue running without a restart.
Step:4 - To check the environment variables of a specific pod, you can use the kubectl describe pod <pod_name> command:
kubectl describe pod my-podStep:5 - Observe the output of the kubectl describe pod command to verify that the DATE environment variable has been updated to the desired value.
Keep in mind that the pod restart behavior depends on how the application inside the pod handles environment variable changes and whether it supports dynamic reloading or restarts upon variable updates.
4. Delete and Let Replicas Create New Pods
When a Pod is deleted, either intentionally or due to a failure, the ReplicaSet or Deployment controller notices that the actual number of pods no longer matches the desired replica count. It then takes corrective action by creating a new Pod to maintain the desired replica count.
When the number of container instances falls below the desired replica count, the ReplicaSet will become aware that the Pod is no longer accessible.
Use the following command to delete a Pod:
kubectl delete pod <pod_name>The above command will delete the specified pod, and the ReplicaSet or Deployment controller will automatically create a new Pod to replace the deleted one and maintain the desired number of replicas.
While deleting pods is a quick way to restart individual pods or address issues with misbehaving pods, it is not recommended for routine restarts or scaling purposes. For routine restarts or changing settings, it's better to use kubectl scale to adjust the replica count or kubectl rollout for controlled updates.
Use the following command to eliminate all unsuccessful Pods for this restart method:
kubectl delete pods --field-selector=status.phase=FailedThis command will delete all pods that are in the "Failed" status. Deleting failed pods can be a troubleshooting step to remove problematic pods from the cluster.
It's essential to be cautious when deleting pods manually, as it may lead to unexpected issues if not done properly. For routine restarts and scaling operations, it's better to use the appropriate Kubernetes features like scaling replicas or rolling updates. Deleting pods is generally more suitable for addressing specific issues with misbehaving or failed pods.
Finally, clean the environment!
By deleting the deployment with the following instruction, you can finish up the configuration as a whole:
kubectl delete deployment httpd-deploymentNOTE: Your application will stop working if you directly deploy a single pod and then remove it. If only one pod is present in a duplicate group for a service, the service will stop functioning after the pod is deleted.
Conclusion
Pod restarts is vital for ensuring smooth deployments and optimal performance. Throughout this guide, we explored various scenarios where restarting Pods becomes necessary, such as resolving "terminating" stage traps, addressing errors, and applying configuration changes.
Having a range of commands at your disposal allows you to make informed decisions when restarting Pods in Kubernetes (K8S). Depending on factors like your Pod distribution strategy, the need for application uptime, and the urgency of the restart, you can choose the most suitable approach.
Among these methods, the kubectl rollout restart technique, as explained earlier, emerges as the optimal choice, ensuring minimal application downtime during the restart process. It is generally considered the best course of action for Pod restarts in Kubernetes.
Instances of the containers holding a containerized program are created or modified according to instructions provided by a Kubernetes deployment. Deployments can allow the regulated distribution of updated code, expand the number of duplicate modules effectively, or, if required, revert back to a previous deployment version.
Atatus Kubernetes Monitoring
With Atatus Kubernetes Monitoring, users can gain valuable insights into the health and performance of their Kubernetes clusters and the applications running on them. The platform collects and analyzes metrics, logs, and traces from Kubernetes environments, allowing users to detect issues, troubleshoot problems, and optimize application performance.
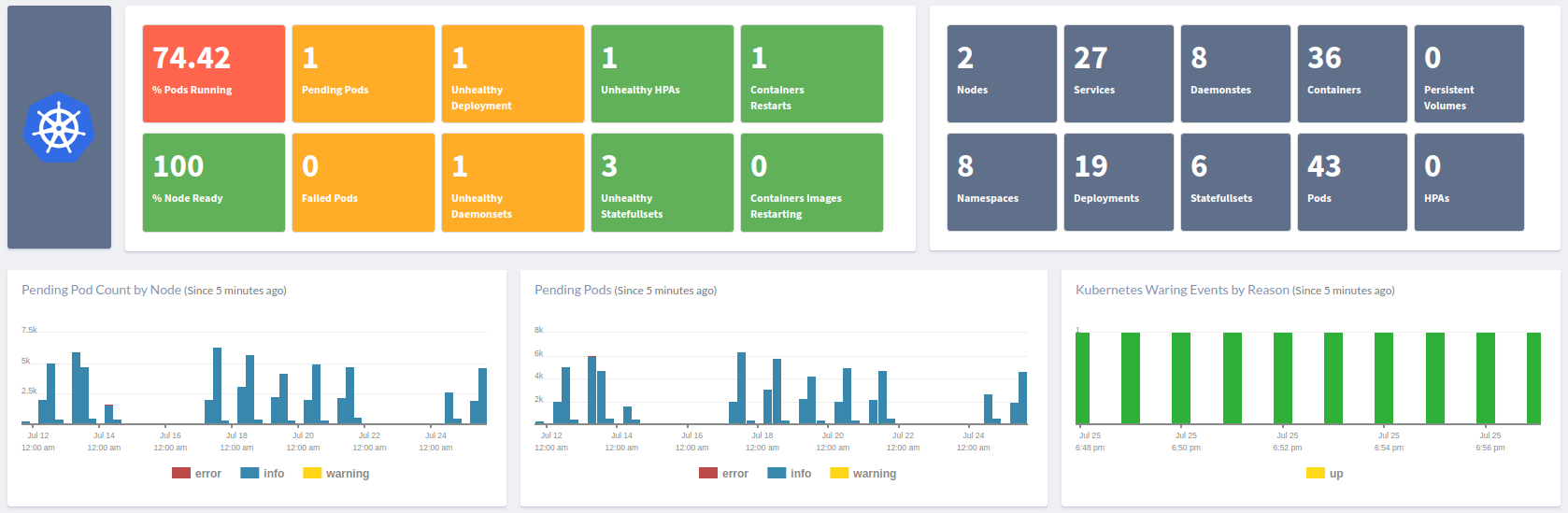
You can easily track the performance of individual Kubernetes containers and pods. This granular level of monitoring helps to pinpoint resource-heavy containers or problematic pods affecting the overall cluster performance.
#1 Solution for Logs, Traces & Metrics
![]() APM
APM
![]() Kubernetes
Kubernetes
![]() Logs
Logs
![]() Synthetics
Synthetics
![]() RUM
RUM
![]() Serverless
Serverless
![]() Security
Security
![]() More
More



