Getting Started with Elasticsearch Aggregations
Let's say you log into your amazon or eBay account and start searching for a gift clothing. First you would filter out gender-specific collections, then you might fix a particular color or even a set of colors of your choice, and following that, you can fix a price range. When you apply these filters one by one, you can see the aggregate products displayed each time varies (their total number changing according to the availability of aggregates).
This is exactly what aggregations do. On the basis of a search request, aggregation frameworks like Elasticsearch give you summarized information. It further checks in deep to provide optimum analysis to give out best results.
Table Of Contents
- Elasticsearch Aggregations: An Overview
- Types of Aggregations in Elasticsearch
- How do Aggregations work in Elasticsearch?
- Performance considerations for Elasticsearch aggregations
- ElasticSearch Aggregation Example
Elasticsearch Aggregations: An Overview
Elasticsearch is an open-source search and analytics engine that is designed to handle large amounts of data and provide real-time search results. It is built on top of the Apache Lucene library, which is a high-performance, full-text search engine.
Elasticsearch is a distributed system, which means that it can scale horizontally across multiple servers and handle large amounts of data. It is used for a variety of applications, including search, log analysis, and analytics.
In Elasticsearch, aggregations are used to perform data analysis and generate summary statistics based on the search results. Aggregations are similar to SQL GROUP BY queries, but they offer a more flexible and powerful way of analyzing data.
Aggregations can be used to generate various types of summary statistics, such as count, sum, average, minimum, maximum, and statistical distributions. Aggregations can also be nested, allowing you to generate more complex summary statistics.
Aggregations are composed of three main components:
- Aggregation type: The type of aggregation to be performed, such as terms, range, date histogram, and more.
- Aggregation field: The field or property of the documents to be used for the aggregation.
- Aggregation options: Additional options that modify the behavior of the aggregation, such as size, order, and filtering.
Here's an example of terms aggregation, which groups documents by a specific field and returns the top N most frequent values:
{
"aggs": {
"top_genres": {
"terms": {
"field": "genre.keyword",
"size": 5
}
}
}
}
This aggregation groups the documents by the genre.keyword field and returns the top 5 most frequent values. Other types of aggregations, such as range, date histogram, and nested, can be used to generate more complex summary statistics.
Types of Aggregations in Elasticsearch
The three broad types of aggregations in Elasticsearch are:
i.) Bucket Aggregations
These are aggregations that group documents into buckets based on a specified criteria. Bucket aggregations can be used to group documents by field values, ranges, time intervals, nested objects, and more.
Some common examples of bucket aggregations include terms, range, date histogram, nested, and geospatial aggregations.
Here's an example of bucket aggregations in Elasticsearch:
Let's say we have a dataset of e-commerce transactions that includes the following fields: product_name, category, price, and timestamp.
We want to create a histogram of the number of transactions per category, with each bucket representing a range of prices. We can achieve this using bucket aggregations in Elasticsearch.
Here's an example query:
GET /transactions/_search
{
"size": 0,
"aggs": {
"price_ranges": {
"histogram": {
"field": "price",
"interval": 50
},
"aggs": {
"categories": {
"terms": {
"field": "category"
}
}
}
}
}
}In this query, we first specify that we don't want any search results ("size": 0). Then we define a price_ranges aggregation, which is a histogram that buckets transactions based on their price field, with an interval of 50. Inside the price_ranges aggregation, we define a categories sub-aggregation that buckets transactions by their category field.
The resulting aggregation will have multiple buckets, each representing a range of prices, and each bucket will contain a sub-aggregation with the number of transactions per category within that price range.
ii.) Metrics Aggregations
These are aggregations that calculate summary statistics for a specified field or set of fields. Metrics aggregations can be used to calculate the count, sum, average, minimum, maximum, and statistical distributions of numeric or date fields.
Some common examples of metrics aggregations include sum, avg, min, max, extended stats, and percentile ranks.
Here's an example of metrics aggregations in Elasticsearch:
Let's say we have a dataset of customer orders that includes the following fields: customer_name, order_date, order_total, and shipping_cost.
We want to calculate the average order total and shipping cost per customer. We can achieve this using metrics aggregations in Elasticsearch.
Here's an example query:
GET /orders/_search
{
"size": 0,
"aggs": {
"customers": {
"terms": {
"field": "customer_name"
},
"aggs": {
"avg_order_total": {
"avg": {
"field": "order_total"
}
},
"avg_shipping_cost": {
"avg": {
"field": "shipping_cost"
}
}
}
}
}
}In this query, we first specify that we don't want any search results ("size": 0). Then we define a customers aggregation that buckets orders by their customer_name field. Inside the customers aggregation, we define two sub-aggregations: avg_order_total and avg_shipping_cost.
The avg_order_total sub-aggregation calculates the average order total for each customer, and the avg_shipping_cost sub-aggregation calculates the average shipping cost for each customer.
The resulting aggregation will have multiple buckets, each representing a different customer, and each bucket will contain the average order total and average shipping cost for that customer.
iii.) Pipeline Aggregations
These are aggregations that perform calculations on the output of other aggregations. Pipeline aggregations can be used to calculate ratios, differences, and other derived metrics based on the results of bucket or metrics aggregations.
Some common examples of pipeline aggregations include bucket script, cumulative sum, moving average, and derivative.
Here's an example of pipeline aggregations in Elasticsearch:
Let's say we have a dataset of web server logs that includes the following fields: timestamp, response_time, and status_code.
We want to calculate the average response time for successful requests (status code 200) and failed requests (status codes 400 and above), and then calculate the ratio of failed requests to successful requests.
We can achieve this using pipeline aggregations in Elasticsearch. Here's an example query:
GET /logs/_search
{
"size": 0,
"aggs": {
"response_times": {
"filter": {
"range": {
"status_code": {
"gte": 200,
"lt": 400
}
}
},
"aggs": {
"avg_success": {
"avg": {
"field": "response_time"
}
},
"failed": {
"filter": {
"range": {
"status_code": {
"gte": 400
}
}
},
"aggs": {
"avg_failed": {
"avg": {
"field": "response_time"
}
}
}
}
}
},
"failed_ratio": {
"bucket_script": {
"buckets_path": {
"failed": "response_times>failed>avg_failed",
"success": "response_times>avg_success"
},
"script": "params.failed / (params.success + params.failed)"
}
}
}
}In this query, we first specify that we don't want any search results ("size": 0). Then we define a response_times aggregation that filters logs based on their status_code field, with a range of 200 to 399 for successful requests. Inside the response_times aggregation, we define two sub-aggregations: avg_success calculates the average response time for successful requests, and failed filters logs with a status code of 400 or above and contains a sub-aggregation avg_failed which calculates the average response time for failed requests.
The failed_ratio aggregation is a pipeline aggregation that uses a bucket script to calculate the ratio of failed requests to successful requests. It takes the failed and success sub-aggregations from the response_times aggregation as inputs and uses a simple formula to calculate the ratio.
The resulting aggregation will have a single bucket that contains the average response time for successful requests, the average response time for failed requests, and the ratio of failed requests to successful requests.
By combining these three broad aggregations, you can generate complex and meaningful summary statistics from your Elasticsearch data.
How do Aggregations work in Elasticsearch?
When you run an aggregation query in Elasticsearch, the query is broken down into two phases: the query phase and the aggregation phase.
- Query phase: In the query phase, Elasticsearch performs the search query to find the relevant documents that match your search criteria. This can include filtering by date range, text matching, or other search criteria.
- Aggregation phase: Once Elasticsearch has identified the relevant documents, it applies the specified aggregation(s) to those documents to compute summary statistics. Each aggregation works differently depending on its type. For example, a terms aggregation will group documents based on the values of a specified field, while a date histogram aggregation will group documents by date ranges.
Aggregations can be nested within each other, allowing you to perform complex data analysis on your data. For example, you could use a terms aggregation to group documents by a specific field, and then use a metrics aggregation to compute the average value of another field within each group.
Once the aggregation phase is complete, Elasticsearch returns the aggregated data as a structured JSON response. You can then use this data to generate reports, visualizations, or other forms of data analysis.
To give you a clear idea, let's discuss how aggregations work with the help on an example.
Here we will be taking an example of shirts of different sizes produced by 4 different makers. This is the sample data on which we will be performing aggregations.
{
"_index": "shirts",
"_type": "_doc",
"_id": "1",
"_score": 1.0,
"_source": {
"manufacturer": "zara",
"size": "38",
"price": 3900,
"sold_date": "2020-03-10"
}
},
{
"_index": "shirts",
"_type": "_doc",
"_id": "2",
"_score": 1.0,
"_source": {
"manufacturer": "hnm",
"size": "40",
"price": 5800,
"sold_date": "2020-07-18"
}
},
{
"_index": "shirts",
"_type": "_doc",
"_id": "3",
"_score": 1.0,
"_source": {
"manufacturer": "zara",
"size": "42",
"price": 6500,
"sold_date": "2020-05-28"
}
},
{
"_index": "shirts",
"_type": "_doc",
"_id": "4",
"_score": 1.0,
"_source": {
"manufacturer": "zara",
"size": "44",
"price": 1490,
"sold_date": "2020-06-10"
}
},
{
"_index": "shirts",
"_type": "_doc",
"_id": "5",
"_score": 1.0,
"_source": {
"manufacturer": "hnm",
"size": "46",
"price": 4200,
"sold_date": "2020-05-26"
}
},
{
"_index": "shirts",
"_type": "_doc",
"_id": "6",
"_score": 1.0,
"_source": {
"manufacturer": "hnm",
"size": "48",
"price": 4800,
"sold_date": "2020-07-13"
}
},
{
"_index": "shirts",
"_type": "_doc",
"_id": "7",
"_score": 1.0,
"_source": {
"manufacturer": "saunders",
"size": "36",
"price": 6800,
"sold_date": "2020-05-25"
}
},
{
"_index": "shirts",
"_type": "_doc",
"_id": "8",
"_score": 1.0,
"_source": {
"manufacturer": "clara",
"size": "42",
"price": 6800,
"sold_date": "2020-03-25"
}
},
{
"_index": "shirts",
"_type": "_doc",
"_id": "9",
"_score": 1.0,
"_source": {
"manufacturer": "clara",
"size": "32",
"price": 5200,
"sold_date": "2020-07-25"
}
}
Each document represents a single shirt sale, with the following fields:
- manufacturer: The manufacturer of the shirt (string).
- size: The size of the shirt (string).
- price: The price of the shirt (integer).
- sold_date: The date when the shirt was sold (string in "YYYY-MM-DD" format).
First we query Elasticsearch to filter out products manufactured by Zara and then do an average aggregation on the field price.
Querying:
{
"size": 0,
"query" : {
"match": {
"manufacturer": "zara"
}
},
"aggs": {
"average_price": {
"avg": {
"field": "price"
}
}
}
}
Running average aggregation & its output:
{
"took": 29,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"average_price": {
"value": 3963.333333
}
}
}
We can see from the sample data that we have got the correct estimates. But all the more easier and in an effortless manner.
Performance Considerations for ElasticSearch aggregations
When working with Elasticsearch aggregations, there are several performance considerations to keep in mind to ensure that your queries return results quickly and efficiently. Here are a few tips:
- Use smaller shards: When you create an Elasticsearch index, you can specify the number of shards the index will have. In general, using smaller shards for better performance with aggregations is a good idea. This is because each shard needs to be searched separately, and aggregations that span multiple shards can be slower.
- Cache results: Elasticsearch caches results for frequently used queries to improve performance. You can also configure Elasticsearch to cache aggregation results. This can be helpful if you have frequently accessed aggregations that stay mostly the same.
- Use field data sparingly: Elasticsearch stores field data in memory, which can be a performance bottleneck if you have many fields or large amounts of data. Therefore, limit the number of fields you use in aggregations, and consider disabling field data caching for infrequently used fields.
- Use sampling: When you have large datasets, sampling can help improve performance. Elasticsearch provides several different sampling options for aggregations, such as random sampling or using a fixed percentage of the total documents.
- Use the right aggregation type: Elasticsearch provides several types, such as terms, histograms, and date histograms. Each type has different performance characteristics, so choosing the right type for your use case is essential.
- Use pipeline aggregations: Elasticsearch provides pipeline aggregations that can perform multiple aggregations in a single query. This can reduce the number of round trips to the Elasticsearch cluster, improving performance.
ElasticSearch Aggregation Example
Consider an e-commerce website that sells products and wants to analyze the sales data to gain insights into customer behavior. The website tracks the following information for each order: order_id, customer_id, product_id, quantity, price, and order_date.
The website wants to answer the following questions:
- What are the top-selling products by quantity and revenue?
- What are the top customers by number of orders and total spending?
- How does the sales volume and revenue vary by month and product category?
To answer these questions, we can use the following Elasticsearch query:
GET /orders/_search
{
"size": 0,
"aggs": {
"top_products": {
"terms": {
"field": "product_id.keyword",
"size": 10
},
"aggs": {
"total_quantity": {
"sum": {
"field": "quantity"
}
},
"total_revenue": {
"sum": {
"script": {
"source": "doc['quantity'].value * doc['price'].value"
}
}
}
}
},
"top_customers": {
"terms": {
"field": "customer_id.keyword",
"size": 10
},
"aggs": {
"total_orders": {
"cardinality": {
"field": "order_id.keyword"
}
},
"total_spending": {
"sum": {
"script": {
"source": "doc['quantity'].value * doc['price'].value"
}
}
}
}
},
"sales_by_month": {
"date_histogram": {
"field": "order_date",
"calendar_interval": "month"
},
"aggs": {
"sales_by_category": {
"terms": {
"field": "product_category.keyword"
},
"aggs": {
"total_quantity": {
"sum": {
"field": "quantity"
}
},
"total_revenue": {
"sum": {
"script": {
"source": "doc['quantity'].value * doc['price'].value"
}
}
}
}
}
}
}
}
}This query computes the top 10 selling products by quantity and revenue, the top 10 customers by the number of orders and total spending, and the sales volume and revenue by month and product category.
The top_products aggregation groups orders by product_id and computes each product's total quantity and revenue. The top_customers aggregation groups orders by customer_id and computes each customer's total number of orders and spending. The sales_by_month aggregation groups orders by month and product_category and computes each category's total quantity and revenue.
By combining multiple aggregations in a single query, we can gain valuable real-time insights into customer behavior and sales trends. We can also use visualization tools to create charts and graphs based on the aggregation results to make it easier to interpret the data.
Summary
Elasticsearch is widely used in industries such as e-commerce, healthcare, and finance for various use cases, such as improving search relevance, monitoring system logs, and analyzing customer behavior.
Elasticsearch Aggregations are a powerful tool for performing data analysis and generating summary statistics in Elasticsearch.
Each type of aggregation provides a different way to analyze and summarize data, and can be combined to generate more complex summary statistics.
Database Monitoring with Atatus
Atatus provides you an in-depth perspective of your database performance by uncovering slow database queries that occur within your requests, and transaction traces to give you actionable insights. With normalized queries, you can see a list of all slow SQL calls to see which tables and operations have the most impact, know exactly which function was used and when it was performed, and see if your modifications improve performance over time.
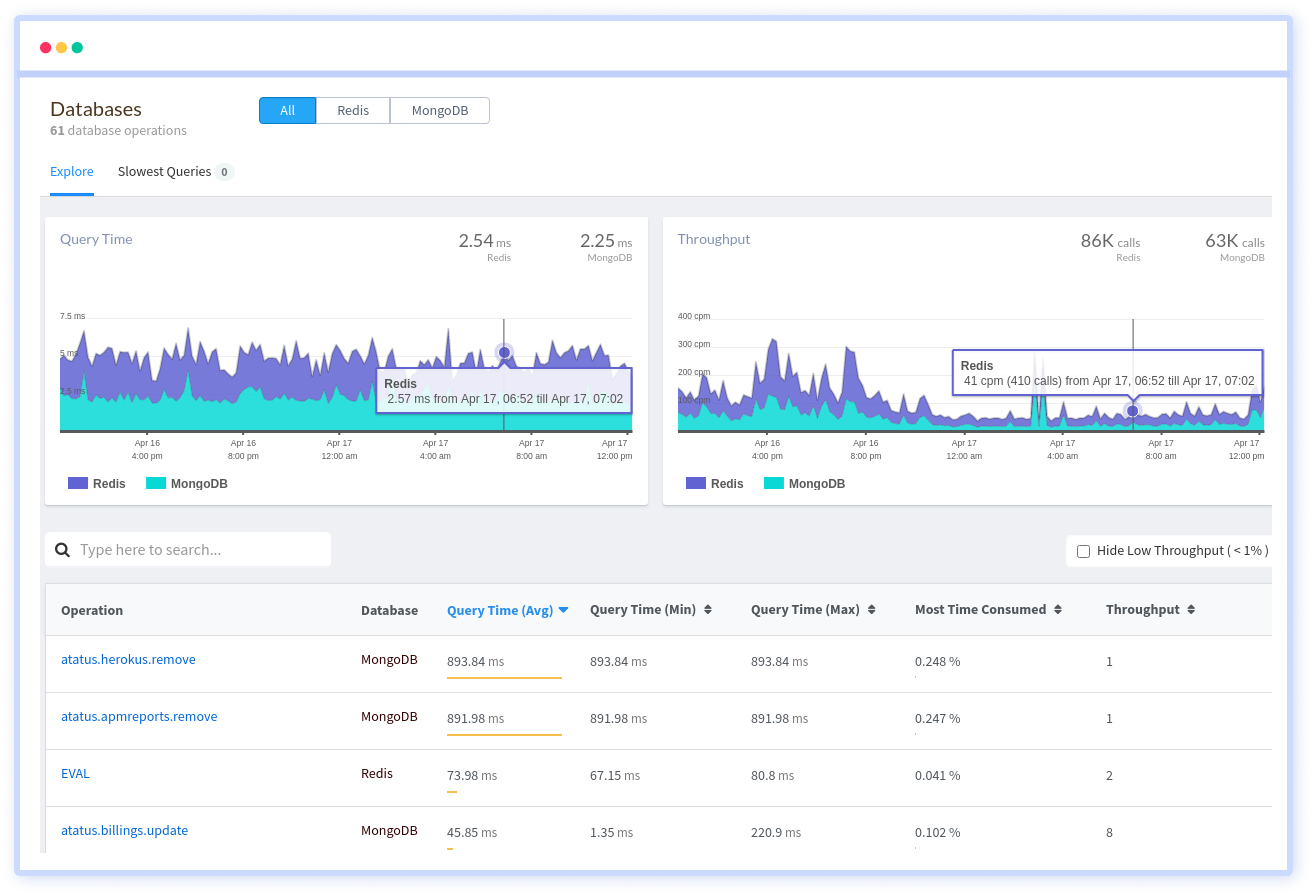
Atatus benefit your business, providing a comprehensive view of your application, including how it works, where performance bottlenecks exist, which users are most impacted, and which errors break your code for your frontend, backend, and infrastructure.
#1 Solution for Logs, Traces & Metrics
![]() APM
APM
![]() Kubernetes
Kubernetes
![]() Logs
Logs
![]() Synthetics
Synthetics
![]() RUM
RUM
![]() Serverless
Serverless
![]() Security
Security
![]() More
More
