Web Scraping in Node.js using Puppeteer
In this digital era, data plays a vital role in every process. From sales to machine learning, the functionality of every process is data-centric. Various types of data namely text, image, audio, and video are used depending on the process.
Collecting these types of data from various resources for a particular process is called data collection. Nowadays data collection is done via the internet manually or programmatically depending upon the process.
For a small data process manual data collection is enough but for a large data process such as training an AI bot requires a huge amount of data, in this case, manual data collection will be a very difficult and more time-consuming process.
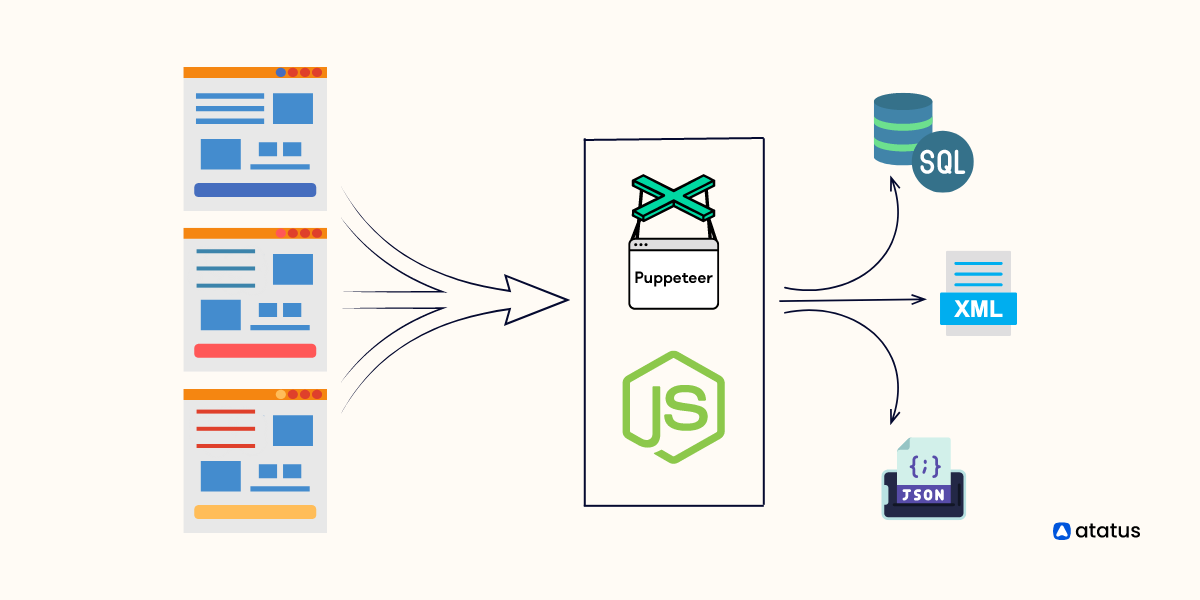
To avoid these hurdles we use programmatically data collection called web scraping for gathering a large amount of data from the world wide web using programming languages such as Node.js.
Let's learn some fundamentals, before diving into the topic.
- What is Web Scraping?
- What is a Web Crawler?
- Use of web scraping with Node.js
- Web Scraping in Node.js using Puppeteer
- Node.js and Puppeteer Configuration
- Build an Amazon Price Scraper with Node.js
- Pros and Cons of Web Scraping
- Use cases of web scraping
What is Web Scraping?
Web scraping is an automation software which assists users to extract various data such as text, audio, image, and video using scripts from various resources such as URLs, websites, webpages, etc., on the internet for a different kind of data-centric process. It is also known as web harvesting, and web data extraction.
For example, the following data are collected from the internet by assisting web scraping.
- Emails collected for marketing and sales process.
- Retrieving product details such as price, features, etc., from e-commerce portals.
- Collecting audio and text files of human languages for Natural Language Processing in AI.
Web scraping is generally deployed when the required websites don’t want to reveal the API for data collection. The web scraping software may directly approach the World Wide Web via the Hypertext Transfer Protocol(HTTP) or a web browser.
What is a Web crawler?
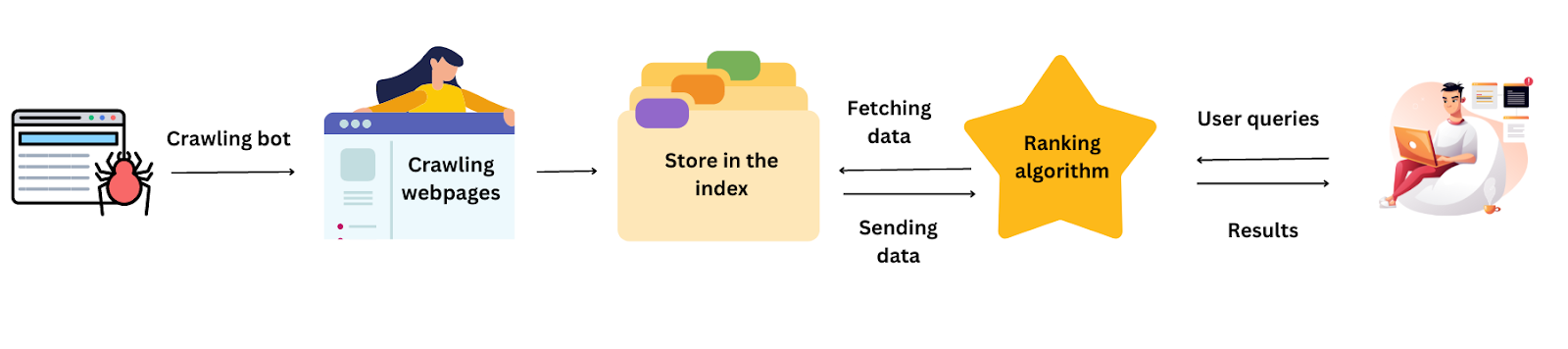
A Web crawler, also known as a robot or spider bot, is an internet bot that automatically searches and scans websites and is often assisted by search engines (like Google or Bing) to gather all the data from a website and index it.
Web crawlers assist you in collecting data from public websites, finding information, and indexing online pages. Moreover, crawlers examine the links between URLs on a website to determine the structure of how these pages are related to one another.
Crawling - deployed when we want to search for information on the internet.
Scraping - deployed when we want to extract that information from the internet.
Use of web scraping with Node.js
- Node. js can be effectively used to perform web scraping even if other languages and frameworks are more popular for web scraping.
- Node. js is the preferred solution for data-intensive, real-time IoT devices and applications because it is quick and scalable. Node. js functions well for encoding and broadcasting video and audio, uploading numerous files, and data streaming because of its non-blocking architecture.
- For projects that need intensive data processing and analysis, Node.js is a better bet. It can manage many concurrent connections without lagging or freezing due to its asynchronous nature. Hence, Node.js is something to think about if you're searching for a solid platform to conduct your data science projects.
- Node. js has a paradigm-shifting technology. Using this, developers can turn JavaScript into a server and client application and developers can automatically communicate and synchronise their data between these two locations by saving their time and effort.
- For data processing, Node.js consumes less time compared with other languages.
- Node.js can act as a proxy server. It can be a result of the services having varying response times or due to their collection of data from multiple resources. This could be a result of a lack of infrastructure where you’ll have to deal with server-side software. The software may manage resources owned by third parties, compile data from various sources, or save videos or photos.
- With the following example, this might be made simpler: Assuming a server-side programme that communicates with external resources. It compiles information from several sources and saves photographs, videos, or both. Node.JS can be used as a proxy in this case if the organisation does not currently have a proxy infrastructure in place or has to develop this solution locally.
Web Scraping in Node.js using Puppeteer
There are more varieties of JS libraries are available in Node.js for web scraping. In this article, we will discuss Puppeteer, one of the most utilised and featured JS modules in Node.js.
Puppeteer
Puppeteer is a simple and famous JS module in Node.js for web scraping. It has a lot of methods to make simple the process of web scraping and web automation.
A high-level API for controlling the Chromium or Chrome browser over the DevTools Protocol is offered by the Node library puppeteer. The default setting is headless, although full operation is also possible (non-headless). It was developed by Google.
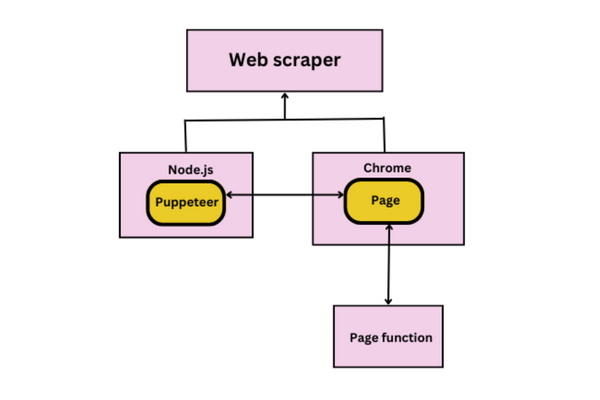
Features of Puppeteer
- It is used to retrieve the text content of the scraped elements.
- It can communicate with web pages by filling out forms, clicking on buttons or running searches inside a search bar.
- Using Puppeteer users can scrap and download data from the web.
- With Puppeteer, you may crawl a Single Page Application and produce pre-rendered content.
- It could also be very useful for a variety of other activities that are not related to web crawling, such as UI testing and performance improvement.
- We can create PDFs from web pages and take screenshots using Puppeteer.
- It is used to see web scraping in progress by deploying headless mode. Headless mode or headless browser is a feature to navigate the web via the command line without the graphical user interface which means when you use a headless browser to access websites, you can't see anything, the program only runs in the background.
Let’s have a look at some playground examples for web scraping in Node.js using the Puppeteer module.
This example will show you how to develop a web scraper that extracts the lowest and highest pricing of a product. Let's develop a programme using Puppeteer that pulls the product and price from Amazon.
With NPM, we can install Puppeteer and use it by importing it into the server file.
Node.js and Puppeteer Configuration
Let's first set up the necessary files and folder structure and install the modules before we begin writing the code.
1. Node.js
To ensure Node.js is installed on your system, open a terminal and enter the following command.
node -vIf it returns a version, Node.js is already installed; else, install it from https://nodejs.org/en/.
2. NPM
The Node Packages Manager, or NPM, allows us to install any Node.js module.
NPM for our project will be set up using this command.
mkdir my-scrapper
npm init -y3. Setup Puppeteer
With this command, the puppeteer module will be installed inside our project.
npm install puppeteer4. Source-Code editor
Open the project in the code editor. VS-Code is used in this post, but you may also use other editors like atom, sublime, etc.
5. Create a file
Create the file app.js where you will put the code for scraping, inside the my-scrapper directory.
Build an Amazon Price Scraper with Node.js
Let’s create an Amazon web scraper with the above configuration.
1. Import Puppeteer
Open the app.js folder and import the puppeteer module using the following command:
const puppeteer = require('puppeteer');2. Instantiating Puppeteer
We have launched a new browser instance using the puppeteer.launch() method. It also creates a new page in the browser instance using the browser.newPage() method. Once you have a page, you can use it to navigate to a URL, interact with elements on the page, and extract data.
const browser = await puppeteer.launch({ })
const page = await browser.newPage()
await page.goto(url)The goto() method is used to navigate the page to the specified URL. The await keyword is used again because this is another asynchronous operation that requires time to complete. Once the page has finished loading, it can be used to extract data from the website.
3. Extracting data from Amazon
In this example, the code uses Puppeteer to launch a headless browser, navigates to the Amazon product page to extract the inner text of the price and product title elements based on their respective CSS selectors.
const puppeteer = require('puppeteer');
function getDate() {
let date = new Date();
let fullDate = date.getFullYear() + "-" + date.getMonth() + "-" + date.getDate() + " " + date.getHours() + ":" + date.getMinutes() + ":" + date.getSeconds();
return fullDate;
}
async function webScraper(url) {
const browser = await puppeteer.launch({});
const page = await browser.newPage();
await page.goto(url);
var product = await page.waitForSelector("#productTitle");
var productText = await page.evaluate(product => product.textContent, product);
var price = await page.waitForSelector(".a-price-whole");
var priceText = await page.evaluate(price => price.textContent, price);
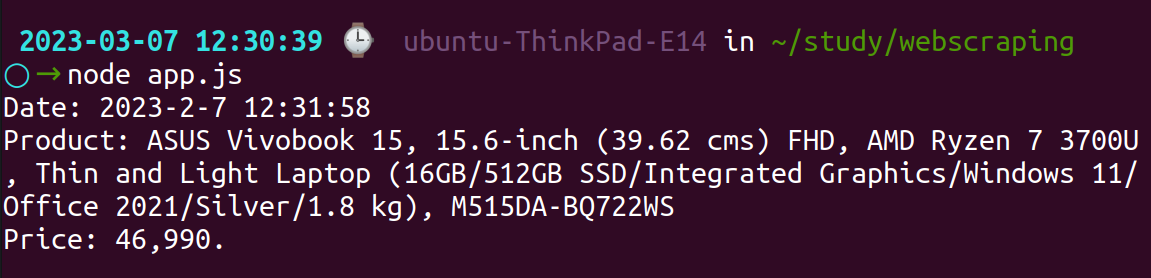
console.log("Date: " + getDate());
console.log("Product: " + productText);
console.log("Price: " + priceText);
browser.close();
};
webScraper('https://www.amazon.in/dp/B09W9MBS1G/ref=cm_sw_r_apa_i_NWPQ1TXATPCD3XBZ0P7W_0');The webScraper function performs the web scraping which takes a URL as input, launches a new Puppeteer browser instance, navigates to the given URL, and extracts the product name and price from the page and the newPage() method of the browser object creates a new tab in the browser instance.
To proceed, you must pass the selector #productTitle to the waitForSelector() function, which waits until the product title element appears on the page. Then, using the evaluate() function, we can obtain the text from the title element of the product. Here, the function returns the textContent property of the handle to the product element. You should also extract the price the same way.
After extracting the data, you can process it as desired or write it in a database. Once the data has been extracted, the Puppeteer browser instance should be closed using the close() function which free up the resources.
Output:
Pros and Cons of Web Scraping
Pros
- Web scrapers may automatically extract data from multiple websites at once, saving time and gathering more pertinent data than a single person could manually.
- Web scraping allows you to retrieve and manage data in databases or spreadsheets on your local computer.
- It is possible to schedule web scrapers to run regularly and export data in the preferred format.
- Each data-driven firm needs accurate data to function. Web scraping is the solution if you're seeking a data extraction technique that is accurate, human-free, and hassle-free.
Cons
- Scrapers may malfunction because HTML structures on web pages are continually changing. You should undertake routine maintenance to keep your scrapers clear and functional, whether you use web scraping tools or develop your code.
- Several requests must be made to scrape huge websites. Some websites may ban IP addresses that often make requests.
- Proxy servers are required since many websites block access from specific countries. Free or inexpensive proxies typically don't assist in these circumstances either because they are frequently used and their IPs are already blacklisted.
- A large number of contemporary websites show content while the page loads in the browser. Any effort to view the source code of the page or retrieve it using a simple HTTP request will show the message "You need to allow JavaScript to execute this application". Headless browsers are necessary to scrape such dynamically created websites. Moreover, rendering requires more hardware resources and time for multiple pages.
Use cases of web scraping
Some common use cases of web scraping:
- Market research: Web scraping can extract product data, pricing, and reviews from online marketplaces like Amazon, eBay, and Etsy. This data can analyze market trends and make informed business decisions.
- Lead generation: Web scraping can extract contact information from websites, such as email addresses and phone numbers, which can be used for lead generation and marketing campaigns.
- Price monitoring: Web scraping can track the prices of competitors' products and services. This information can be used to adjust pricing strategies and remain competitive.
- News aggregation: Web scraping can extract news articles and headlines from news websites, which can be aggregated and analyzed for trends and insights.
- Social media analysis: Web scraping can extract data from social media platforms like Facebook and Twitter to monitor public sentiment and analyze social media trends.
- Academic research: Web scraping can be used by researchers to collect data from various sources on the internet, such as online databases and social media, for academic research purposes.
Conclusion
Web scraping is a technique for gathering a variety of publicly accessible data from the internet, including prices, text, photos, contact details, and much more. When trying to gather data that would otherwise take a lot of effort to gather and organise manually, this can be helpful.
Scraping has a lot of benefits on its own. You can keep an eye on suppliers, automate chores, and search for mentions of your brand or other companies. You can also keep an eye on pricing comparisons.
You can stay up to date with new technology and analyse large amounts of data. Using web scraping, you can automate data collection and turn it into insightful information for your company.
A "crawler" is what a basic web scraping software uses to access the internet, browse the web, and collect data from predetermined pages.
Node.js and JS modules are great for data scraping in all parts of the process. The usage of Node.js enables not only the resolution of all scraping-related problems but also the assurance of the security and dependability of data extraction. Moreover, the use of headless browsers will simulate user behaviour.
We can conclude Puppeteer is a potent library for automation, web scraping, screenshotting, saving PDFs, debugging, and it even supports non-headless contexts.
Monitor your Node.js application with Atatus
Atatus keeps track of your Node.js application to give you a complete picture of your clients' end-user experience. You can determine the source of delayed response times, database queries, and other issues by identifying backend performance bottlenecks for each API request.
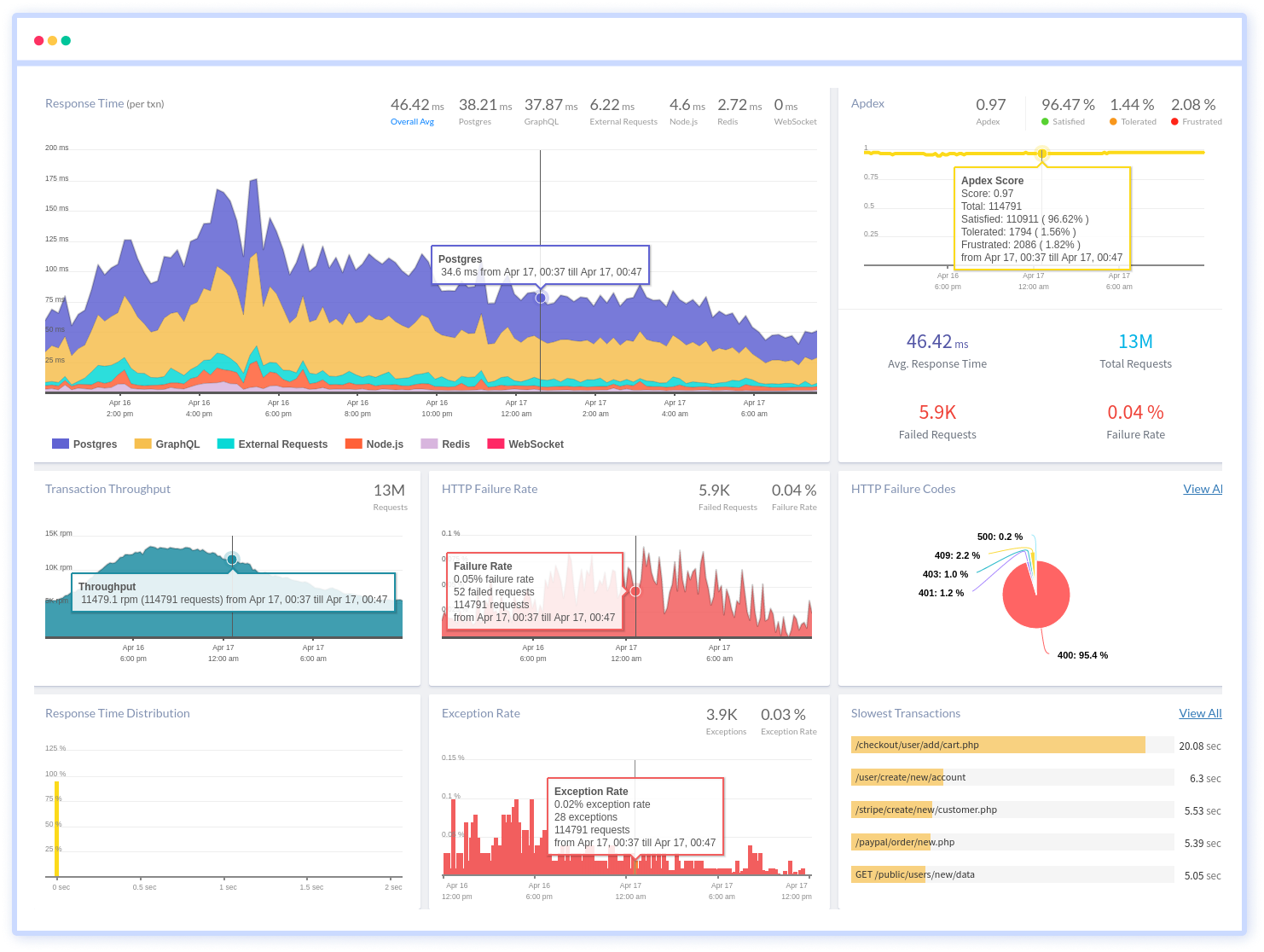
Node.js performance monitoring made bug fixing easier, every Node.js error is captured with a full stack trace and the specific line of source code marked. To assist you in resolving the Node.js error, look at the user activities, console logs, and all Node.js requests that occurred at the moment. Error and exception alerts can be sent by email, Slack, PagerDuty, or webhooks.
#1 Solution for Logs, Traces & Metrics
![]() APM
APM
![]() Kubernetes
Kubernetes
![]() Logs
Logs
![]() Synthetics
Synthetics
![]() RUM
RUM
![]() Serverless
Serverless
![]() Security
Security
![]() More
More



