Logging Practices: Know What to Log

Logging is an essential component of many applications. Every application has a different logging technique. You may prefer certain logging implementations, but you must also consider what to log, when to log, how much to log, and how to control logging.
System administrators and developers, particularly the support team, benefit greatly from a well-designed logging system. For both the support team and the developers, logs save a lot of time. The system develops a vault of event information (log entries) for system administrators and the support team as users execute applications on the front end.
We will go over the following:
What Should We Log?

"What questions do we want to answer?" is a good place to start. We can then identify which data needs to be logged in order to effectively answer these questions.
When a question arises, we can only respond with the data and knowledge we have on hand. We can't update the system to log new data to answer inquiries about the current condition of the system in an emergency case like an unplanned system failure.😵
This means we must try to foresee what information we'll need in the future to answer full queries about our system.
These are the log file that should be logged for future reference in case of system failure or any other issues to deal with.
- Application Session Start/Stop
Log statement should be included as early and as late as possible in the execution time of your application. Include additional messages at the beginning and end of these sections if your software has a sophisticated setup or teardown logic. - User Session Start/Stop
There may be multiple user sessions within a single application session for many applications, such as services and web applications. At the start and end of each of these logical sessions, record distinct messages. - Unhandled Exceptions
By default, Atatus logs unhandled exceptions. If you write your own exception handler, make sure to log each one to Atatus, supplying the exception object and the context you're working with. - Handled Exceptions
We strongly advise that you log an exception with an informational severity rather than eating it quietly in all circumstances where an exception is ingested within a catch block. Bonus points if you include what your code will do if this managed exception occurs. - Display Help Requests
From a usability standpoint, every time a user views your help documentation, it's a sign that something in the user interface might be made clearer. - Canceled Actions
When a user starts an action but abandons it before finishing it, it may indicate usability concerns. - Process Entrance and Exit
Log the request every time your code is called from another process or you call out to another process. If the request fails, make a note of it. These assertions help as "reference points" for figuring out why your software worked or didn't operate. These log statements are almost free as compared to the expense of calling another process, especially across a network. - Log Thread Start/Stop
Consider building a helper class to create threads that will automatically log thread start/stop if your application produces background threads. - Asynchronous Request Start/Stop
Most asynchronous queries should be logged at the start and stop, with the exception of high-frequency activities like loading individual web page elements.
These are the few things to log while logging. There are other things to log as well, but in this article, we'll be focused on the core elements.
How do We Know What Data to Log?
We can rely on community expertise and log data to answer similar specific questions presented regularly in the community in the context of systems similar to ours when we don't have precise queries.
If our questions turn out to be commonly asked in the community, this log data will be beneficial. If not, it can still provide useful information and advice on how to enhance the data being logged as well as the system as a whole.
It's critical to be proactive in gathering the data you need, but if we don't have complete coverage, we must be flexible in how we alter and deploy the system.
Core Elements
We'll look at some of the most prevalent elements of modern systems that are worth keeping an eye on based on community expertise. We'll also look at some of the most popular questions about these topics, as well as the data needed to answer them.
A word of caution before we begin.

While collecting additional data may be beneficial, doing so in excess might harm the system's efficiency and, more crucially, raise issues and hazards about user security and privacy. As a result, be cautious when collecting nice-to-have data.
Functional correctness, performance, reliability, and security are the key features of every software system that should be monitored. Scale and privacy are two further domain-specific considerations. Each domain has its own set of questions that need to be addressed.
Detailed Explanation
Assuming we agree that these aspects are generally relevant, we'll dive a little deeper into each one and the questions that go with it.
We will offer ideas in the context of service-based systems in which applications/services serve as the basic compositional units and each request served by an application has a unique id in the following exposition.
#1 Functional Correctness
When it comes to functional correctness, we want an application to perform exactly what it says it will.
More specifically, we're concerned with the operational and data aspects of an application's function. Consider an application that states it will charge $55.34 to credit card XXX.
If the application charges a credit card, it is operationally correct. If the amount involved is $55.34 and the credit card is XXX, the application displays data correctness.

In general, an application is operationally right if it performs the expected actions to service a request, and data correct if it consumes and generates the expected data.
We must monitor both the operational correctness and the data correctness of an application in order to monitor its functional correctness. As a result, we'll need to gather information to answer the following questions.
- Is the application capable of performing the activities required to fulfill a request?
- When responding to a request, does the application consume and output the data expected?
What to log
Since an application may rely on other applications in the system to service a request, monitoring for data and operational correctness boils down to tracking what data was consumed and provided by the application, as well as what operations the application requested to service the request.
Track every action completed and data consumed and delivered to service a request, as applications may rely on other applications to service a request.
To answer the questions above, keep track of each request, its id, and the response it receives. Capture additional data that allows related requests to each other, relating requests to responses, and recreating the global order of requests and responses for the recorded data to be relevant.
Since requests and response payloads may contain sensitive information, ensure that the logging system and any downstream systems manage and process such sensitive information appropriately.
#2 Security
When it comes to security, we want an application to do what it says it will without causing harm.

The domain and system in which application functions are frequently intertwined in the notion of harm. In the context of financial systems, theft of funds, for example, would be harmful. In the context of medical systems, however, the loss or erroneous manipulation of medical records would be harmful.
Despite this, practically all domains that rely largely on software and automation have a security framework consisting of requirements (standards) and processes (certifications, inspections, and audits) to protect themselves against harm.
With such frameworks, we can look at security from a broader perspective, such as whether an application is consistent with the domain's security framework. As a result, we've come up with the following security-related questions.
- Are the operations carried out in the application and supported by it compliant with security requirements?
- Are the data that the application accesses and provides compatible with security requirements?
What to log
To answer the aforementioned questions, log the request, the time it was accepted and serviced, the authorization and authentication information connected with the request, and the data associated with it for every request that may have cybersecurity consequences. Additionally, log additional data to establish compliance with the domain of the application's requirements.
If an application service requests to edit sensitive records, it should log the modifier's authorization and authentication factor, the record's modified parts (pointers to them), the modifications (points to them), the request's source of origin, and the request's time. Even if the request for change is completed without adjustments, the same information should be recorded (due to errors or no modifications).
Capture extra data, as with previous elements, to reconstruct the relationship and ordering between requests. Ensure that sensitive data is handled properly during logging; this may include logging merely a pointer to the data rather than to the entire data.
#3 Performance
When it comes to performance, we're looking for an application that can deliver on its promises quickly enough.
This feature has two facets in the context of service-based systems: latency and throughput. The time it takes an application to service a request, or the delay between accepting and replying to a request is known as latency. The number of requests serviced by an application in a second is known as throughput.
We need to collect data to answer the following questions in order to monitor the performance of an application.
- How long does it take the application to respond to a request?
- How many requests does an application service?
What to log
Latency and throughput, unlike functional correctness, are application-specific, meaning they may be examined independently of other applications involved in the application's function. However, since an application can rely on other applications to fulfill a request, we must analyze these qualities of the other applications to see if and how they affect the dependent application's characters.
To answer the questions above, keep track of each request's id, the time it was received, and the time the associated response was delivered.
Capture additional data that aids in the relationship between requests and their dependent requests, just as you would for functional correctness. This information will be used to determine how the latency of one request impacts other requests in the system, either directly or indirectly.
#4 Reliability
We're interested in the prospect of an application failing to deliver what it promised to do in ways that affect dependent applications when it comes to reliability.
Functional correctness and reliability are two sides of the same coin.

While functional correctness refers to what occurs when an application successfully responds to a request (for example, by returning an error code), reliability refers to what happens when an application fails to answer a request (for example, crashed before responding).
Given the focus on an application's fallibility, we're looking for questions that can help us analyze and address failures, as well as design a strategy to mitigate and prevent future failures. Specifically,
- How frequently does an application fail to meet a request's requirements?
- Is the failure pattern consistent or sporadic?
- What was the failure path through the system?
What to log
To answer the questions above, log the request's id, the time it was received, if the application failed to serve it, and the time the service failure was noticed for each request.
To answer the first two questions, the logged data is sufficient. To answer the third question, log additional data because an application's failure could be caused by other applications failing, the request the application received, the status of the application, or the condition of the application's execution environment. This additional information will be unique to the request, the application, and the context in which it is being executed.
When logging more data, be cautious.🧐
Specifically, verify that sensitive data is handled properly. Also, strike a balance between the amount of data required to analyze failures and the amount of log data available. To explain failures, being clever about how to log data is processed and stored can help reduce the volume of log data.
What Not to Log?
There are a few things that are not considered to be logged.
- Simple Routine Actions
While smart logging can be incredibly beneficial, do not log every method entry/exit without exception. Use your best judgment and only insert logging where it can assist you to understand the application flow. - Avoid Logging in Tight Loops
Avoid logging in tight loops that are repeated hundreds of times per second. While Atatus can readily log over 1000 messages per second, such large logs are inconvenient. With a few well-placed log messages, you can get an excellent feel of what an application is doing. Later on, you and your support personnel will be grateful. - Consider Your Options When Dealing with Sensitive Data
When adding log messages to your application, be mindful of privacy and intellectual property concerns. Passwords and sensitive information like social security numbers, for example, should never be logged.
Summary
Logging data in a proactive manner will always lead to the following actions and questions that need to be addressed. However, it's crucial to remember to be cautious when collecting data, especially a large amount of information, because worries and hazards about user security and privacy can arise. Keep the major features of the software systems in mind as you progress at a comfortable and efficient pace.
Atatus Logs Monitoring and Management
Atatus offers a Logs Monitoring solution which is delivered as a fully managed cloud service with minimal setup at any scale that requires no maintenance. It monitors logs from all of your systems and applications into a centralized and easy-to-navigate user interface, allowing you to troubleshoot faster.
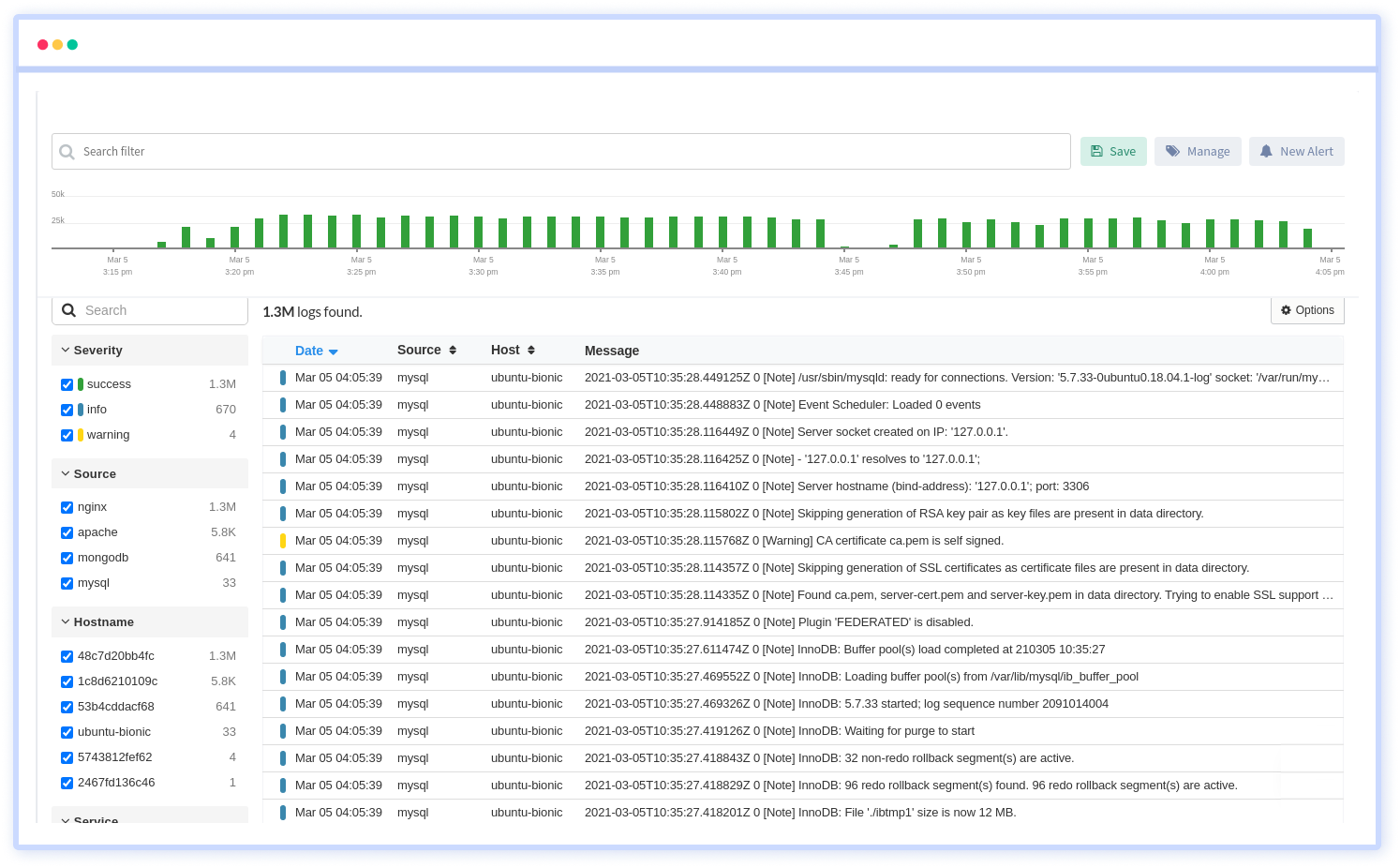
We give a cost-effective, scalable method to centralized logging, so you can obtain total insight across your complex architecture. To cut through the noise and focus on the key events that matter, you can search the logs by hostname, service, source, messages, and more. When you can correlate log events with APM slow traces and errors, troubleshooting becomes easy.
#1 Solution for Logs, Traces & Metrics
![]() APM
APM
![]() Kubernetes
Kubernetes
![]() Logs
Logs
![]() Synthetics
Synthetics
![]() RUM
RUM
![]() Serverless
Serverless
![]() Security
Security
![]() More
More

![New Relic vs Splunk - In-depth Comparison [2026]](/blog/content/images/size/w960/2024/10/Datadog-vs-sentry--19-.png)