Optimize Data Processing with Vector Databases
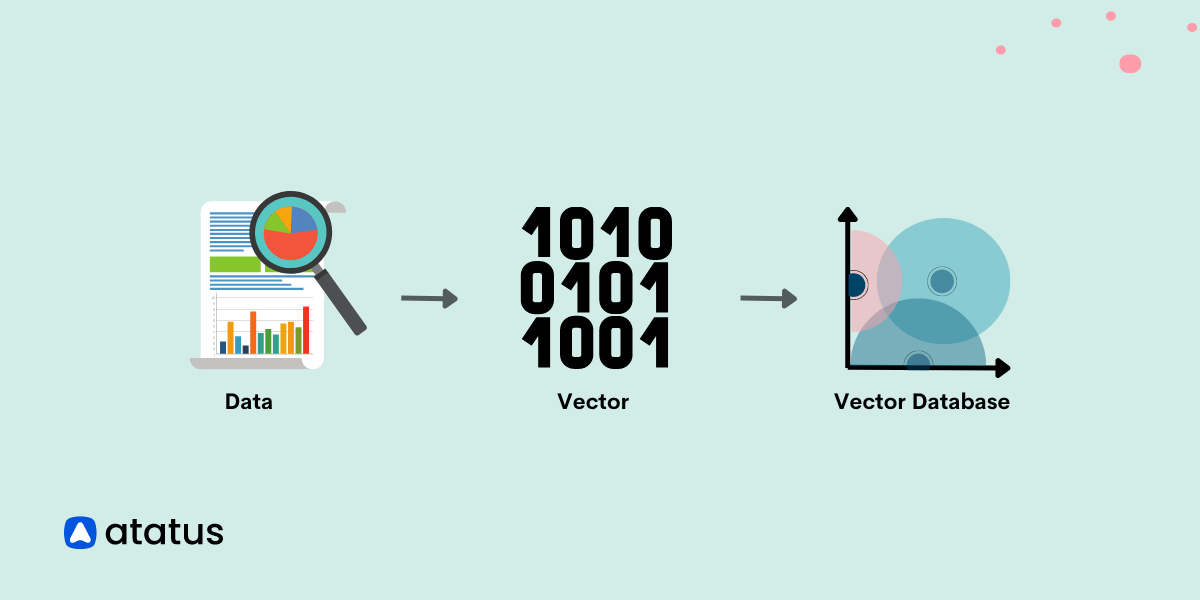
Welcome to the world of vector databases, where data storage and retrieval take on a whole new dimension!
Let's start with the basics. In a vector database, data points are represented as multi-dimensional vectors, where each dimension captures a specific feature or attribute of the data.
These vectors encode the essence of the data, allowing for efficient analysis, comparison, and retrieval. They form the building blocks for a wide range of applications, from image recognition to natural language understanding.
In this blog, we'll dive into the practical aspects of vector databases and explore how they are transforming the landscape of artificial intelligence and machine learning.
Table of Contents
- Introduction to Vector Databases
- What are Vector Embeddings?
- Vector Representation
- How a Vector Database Works?
- Scalability and Performance
- Popular Vector Databases
- Milvus Example - Vector Database
- Benefits of Vector Databases in AI and ML
Introduction to Vector Databases
Vector Database generally refers to a database specifically designed for storing and managing high-dimensional vector representations of data used in artificial intelligence applications. Vectors, in this context, are numerical representations of objects or data points in a multi-dimensional space, with each dimension representing a distinct attribute or feature of the object.
Vector databases in AI are used to store and retrieve vector representations of various data elements, such as words, images, documents, or user preferences. Vector databases differ from other usual databases that organize data in tabulated lists by organizing data using high-dimensional vectors.
Similarity search entails finding objects in a database that closely resemble a given query object based on their vector representations.
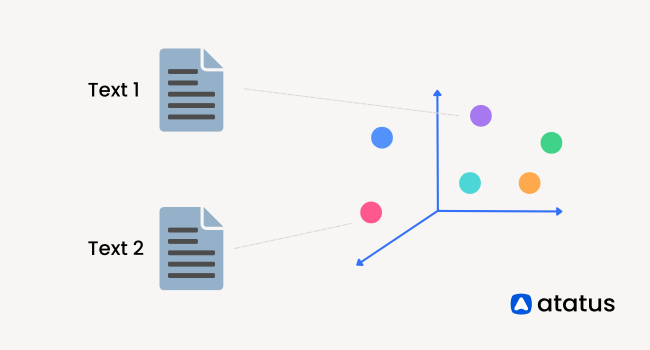
The significance of vector databases stems from their capability to handle large-scale high-dimensional data sets and perform rapid similarity searches. Traditional relational databases are ill-suited for this type of data due to their inflexible structure and lack of specialized indexing techniques tailored for similarity search.
In contrast, vector databases employ a range of indexing structures and algorithms specifically designed to efficiently handle high-dimensional data and enable swift nearest neighbour searches.
Vector Database Example
Let's consider a database for an e-commerce platform that sells products. Each product will have various attributes such as name, price, category, and rating. We can represent each product as a vector with these attributes.
Here's a sample structure for the vector database:
| Product Name | Price | Category | Rating |
|---|---|---|---|
| Laptop | 12 | Electronics | 4.2 |
| Tshirts | 20 | Clothing | 4.3 |
| Headphones | 15 | Electronics | 4.0 |
| Books | 50 | Books | 4.7 |
In this example, each row represents a product, and the columns represent the attributes of the product (name, price, category, and rating). The values in each cell represent the specific attribute value for that product.
To access a specific product in the vector database, you can use an index. For example, if you want to retrieve the information about the second product (T-shirt), you can use the index "2" to access the corresponding row.
Using the index, you can retrieve the vector for the T-shirt product, which would be:
| Product Name | Price | Category | Rating |
|---|---|---|---|
| Tshirts | 20 | Clothing | 4.3 |
This example demonstrates how you can store and retrieve information about products using vectors in a database. With such a database, you can perform various operations like filtering products based on price, category, or rating, sorting products, or performing complex queries to find relevant products based on user preferences.
What are Vector Embeddings?
Vector Embeddings, also known as vector representations, are numerical representations of objects or entities in a high-dimensional vector space. When it comes to representing data numerically, there are two important concepts:
- Two-dimensional vectors
- Three-dimensional vectors
A two-dimensional vector exists in a two-dimensional space, usually represented using an x-y coordinate system. Geometrically, a two-dimensional vector can be visualized as an arrow starting from the origin (0, 0) and extending to a specific point (x, y) in the x-y plane. These vectors are commonly used to represent positions, displacements, velocities, or forces in physics, as well as data points in applications like computer graphics or machine learning.
On the other hand, a three-dimensional vector exists in a three-dimensional space, often represented using an x-y-z coordinate system. Geometrically, a three-dimensional vector can be visualized as an arrow starting from the origin (0, 0, 0) and extending to a specific point (x, y, z) in 3D space. Three-dimensional vectors are widely used in fields such as physics, computer graphics, robotics, and simulations to represent positions, orientations, velocities, forces, or spatial relationships between objects.
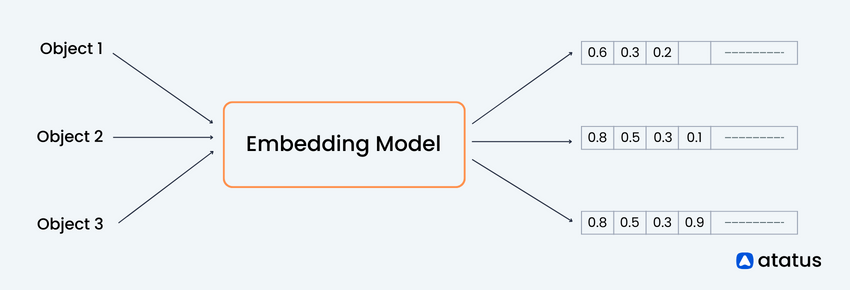
Vector embeddings play a crucial role in enabling AI systems to process and understand complex data. By representing data in a high-dimensional vector space, vector embeddings provide a compact and meaningful representation that facilitates effective computation and comparison of complex data structures, enabling AI systems to process and understand information more efficiently.
Vector Representation
Vector representation is a core element of vector databases, where data is transformed into numerical vectors for storage, indexing, and similarity search purposes. This representation enables the efficient handling of high-dimensional data and facilitates various applications that rely on similarity matching. Let's delve into the concept of vector representation in vector databases:
1. Understanding High-Dimensional Vectors
Vectors in vector databases refer to mathematical structures that comprise multiple dimensions or components. Each component corresponds to a specific attribute or feature of the data being represented.
High-dimensional vectors consist of a large number of dimensions, typically ranging from hundreds to thousands or even more. The dimensionality of vectors is determined by the complexity and richness of the data that is being encoded.
2. Components of Vectors
The components of vectors vary based on the type of data being represented. Here are examples for different data types:
- Images: In image recognition applications, images can be represented as vectors where each dimension represents the value of a pixel. The length of the vector corresponds to the total number of pixels in the image, resulting in a high-dimensional vector.
- Text: In natural language processing, text documents can be transformed into vectors using techniques such as word embeddings or bag-of-words. Each dimension of the vector represents a specific word or a statistical characteristic of words within the document.
- Audio: In audio processing, audio signals can be converted into vectors using methods like Mel-Frequency Cepstral Coefficients (MFCCs) or spectrograms. Each dimension of the vector captures an audio feature at a specific time frame.
- User Preferences: In recommendation systems, user preferences can be expressed as vectors, where each dimension represents a particular item or feature that users have preferences for, such as movies, products, or music genres.
3. Vectorization Techniques
The process of converting diverse data types into vector form involves employing specific techniques tailored to each data type. These techniques aim to capture the fundamental characteristics and patterns of the data within the vector representation. Some common techniques include:
- Feature Extraction: Extracting relevant features from raw data to form vector components. This may involve techniques like edge detection, texture analysis, or feature engineering based on domain knowledge.
- Embeddings: Utilizing algorithms like word2vec or GloVe to transform textual data into continuous vector representations, which capture semantic relationships between words.
- Signal Processing: Applying signal processing techniques to audio or sensor data to extract features such as frequencies, energy levels, or statistical properties.
4. Vector Normalization and Standardization
To ensure consistency and comparability, vectors in vector databases often undergo normalization or standardization.
Normalization scales the vector components to a common range (e.g., [0, 1]) or adjusts them to possess a unit norm. Standardization involves centering the data by subtracting the mean and dividing by the standard deviation of each component.
How a Vector Database Works?
The vector database stores the vector embeddings in a structured manner. It assigns a unique identifier or key to each vector for easy referencing and retrieval. The vectors are typically stored in a persistent storage system, such as disk or memory, to ensure durability and long-term availability.
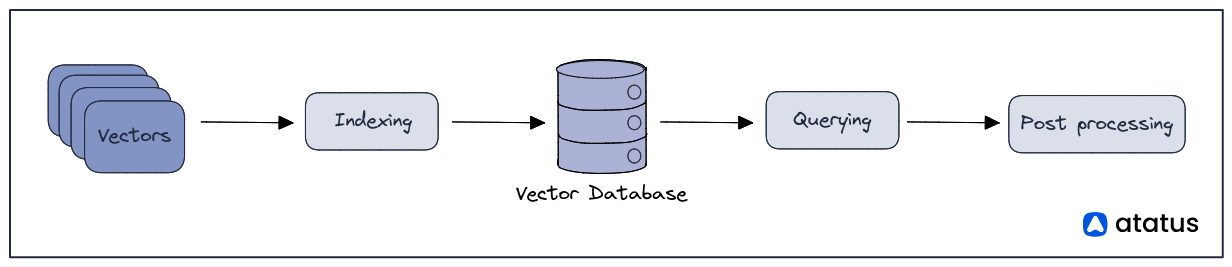
A vector database works by providing a storage and retrieval system for vector embeddings. Here is a general overview of how a vector database works:
- Indexing: To facilitate efficient search operations, the vector database may employ indexing techniques. An index is created to organize the vectors in a way that allows for fast retrieval based on similarity or distance measures. Various indexing methods, such as Approximate Nearest Neighbour (ANN) algorithms, can be used to construct the index. The index helps narrow down the search space and speeds up similarity search operations.
- Querying: When an application sends a query to a vector database, the query needs to pass through the same vector embedding model that was used to generate the vector embeddings stored in the database. The query data is transformed into a query vector using the vector embedding model. The query vector is compared to stored vector embeddings in the vector database to find the most similar matches. The top-ranked matching vectors or their metadata are returned as query results to the application.
- Post-processing: Post-processing in a vector database involves refining the initial query results by ranking, filtering, and aggregating the retrieved vectors. It may also incorporate contextual information, generate visualizations, or perform application-specific operations for enhanced analysis or presentation.
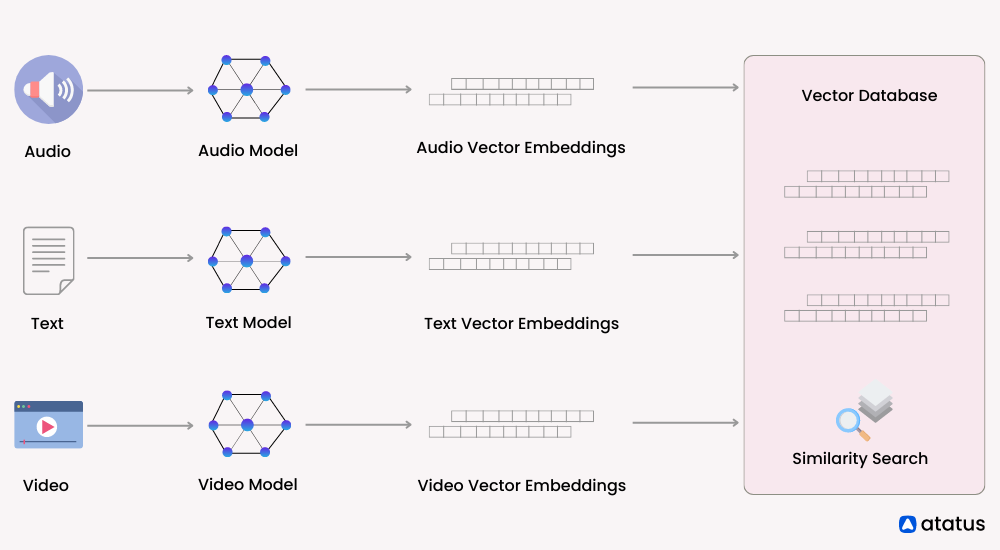
Scalability and Performance
When scaling vector databases to handle substantial amounts of high-dimensional data, several challenges need to be addressed. To ensure scalability and optimal performance, techniques such as data distribution, parallel processing, and load balancing are employed. Here is a rephrased discussion on these topics:
1. Dealing with Large Data Volumes
- Storage: Traditional storage systems may not suffice as data volumes increase. To handle this, distributed file systems or cloud storage solutions can be utilized, allowing data to be stored across multiple nodes or servers for improved scalability and fault tolerance.
- Indexing: As the number of vectors grows, the indexing structures must efficiently handle the increased dataset. Tree-based structures (e.g., k-d trees) or hash-based indexing techniques can be utilized. Additionally, approximate nearest neighbour search algorithms can be employed to reduce the complexity of search operations for large datasets.
2. Distributed Data Storage and Parallel Processing
- Data Distribution: To accommodate large-scale datasets, data can be distributed across multiple nodes or servers. Techniques like sharding, partitioning, or replication can be used to divide the data among nodes, ensuring load balancing and fault tolerance. Each node becomes responsible for storing and processing a subset of the vectors.
- Parallel Processing: By leveraging parallel processing techniques, distributed vector databases can enhance query performance. Queries can be executed simultaneously on multiple nodes, enabling faster retrieval of results. Techniques such as parallel indexing, parallel query execution, or distributed computing frameworks can facilitate efficient parallelism.
3. Data Partitioning and Load Balancing
- Data Partitioning: Efficient data partitioning is crucial for optimized data access and storage. Partitioning can be based on criteria such as data range, key-based partitioning, or hashing of vector identifiers. Each node is then responsible for managing a specific subset of the data, allowing for parallel processing and minimizing network overhead during queries.
- Load Balancing: Proper workload distribution across nodes is essential to prevent performance bottlenecks. Load balancing techniques evenly distribute query requests among nodes, ensuring efficient resource utilization and minimal response times. Load balancing algorithms consider factors such as node capacity, query load, or network latency to achieve an optimal distribution.
4. Caching and Memory Optimization
- Caching: Caching mechanisms can significantly improve query performance by storing frequently accessed vectors or query results in memory. This reduces disk access and accelerates response times. Techniques like LRU (Least Recently Used) or LFU (Least Frequently Used) caching can be employed to manage the cache effectively.
- Memory Optimization: High-dimensional vector data can consume substantial memory resources. To address this, dimensionality reduction techniques like principal component analysis (PCA) or locality-sensitive hashing (LSH) can be applied. These techniques compress the vectors while preserving similarity relationships, enabling efficient storage and retrieval.
Popular Vector Databases
Vector databases play a crucial role in various domains of artificial intelligence (AI) and machine learning (ML). They are particularly useful when dealing with complex data types like text, images, audio, and video, where representing data as vectors allows for efficient analysis and comparison.
The choice of a vector database depends on factors like scalability, performance, ease of integration, and specific requirements of the application.
Here's a short introduction to some popular vector databases:
1. Pinecone
Pinecone makes it easy to provide long-term memory for high-performance AI applications. It’s a managed, cloud-native vector database with a simple API and no infrastructure hassles. Pinecone serves fresh, filtered query results with low latency at the scale of billions of vectors.

2. Milvus
Milvus is an open-source vector database designed for storing and searching high-dimensional vectors. It offers efficient indexing techniques, supports GPU acceleration, and provides compatibility with popular machine learning frameworks.
3. Weaviate
Weaviate is an open-source vector database that focuses on the efficient storage, retrieval, and exploration of high-dimensional vector data. It is designed to support real-time applications and offers native support for vector embeddings. Weaviate enables advanced similarity search, recommendation systems, and knowledge graph applications.
Milvus Example - Vector Database
Here's a sample code using the Milvus vector database for an image recognition system:
import milvus
import numpy as np
from PIL import Image
# Connect to Milvus server
client = milvus.Milvus()
# Set Milvus server address and port
milvus_server_addr = "127.0.0.1"
milvus_server_port = 19530
client.connect(host=milvus_server_addr, port=milvus_server_port)
# Create a collection to store image vectors
collection_name = "image_collection"
collection_param = {
"fields": [
{"name": "embedding", "type": milvus.DataType.FLOAT_VECTOR, "params": {"dim": 2048}}
]
}
client.create_collection(collection_name, collection_param)
# Load an image and extract image features
image_path = "path_to_image.jpg"
image = Image.open(image_path).convert("RGB")
# Perform image processing and feature extraction using your preferred method
image_features = np.random.rand(2048).tolist() # Random features as a placeholder
# Insert image features into Milvus collection
entities = [
{"embedding": image_features}
]
client.insert(collection_name, entities)
# Flush data to disk (optional but recommended)
client.flush([collection_name])
# Search for similar images
query_features = np.random.rand(2048).tolist() # Random query features as a placeholder
query_embedding = {"embedding": query_features}
search_param = {
"collection_name": collection_name,
"query": query_embedding,
"top_k": 5
}
results = client.search(search_param)
# Retrieve similar images
similar_image_ids = [result.id for result in results[0]]
similar_images = [image for image in client.get_entity_by_id(collection_name, similar_image_ids)]
# Print similar image IDs
print("Similar image IDs:")
for image_id in similar_image_ids:
print(image_id)
# Close the connection to Milvus server
client.disconnect()In this example, we first connect to the Milvus server using the milvus.Milvus() class. Then we create a collection named image_collection to store image vectors. We load an image, perform image processing and feature extraction (you'll need to replace the placeholder code with your actual image processing and feature extraction code), and insert the image features into the collection.
Next, we flush the data to disk for persistence (optional but recommended). Then we perform a search for similar images by providing a query image feature vector. In this example, we use random query features as a placeholder, but you should replace it with your actual query features.
Finally, we retrieve the IDs of the similar images and print them. You can further process or display the retrieved images based on your requirements.
Remember to replace path_to_image.jpg with the actual path to the image you want to insert and search for. Additionally, ensure that you have Milvus and the necessary dependencies installed before running this code.
Benefits of Vector Databases in AI and ML
- Efficient Storage and Retrieval: Vector databases are specifically designed to store and retrieve high-dimensional vectors efficiently. They optimize storage and indexing mechanisms, enabling fast and scalable operations on vector embeddings.
- Fast Similarity Search: Vector databases excel in similarity search tasks, allowing for efficient retrieval of similar vectors. This benefits applications like recommendation systems, content-based filtering, and personalized search, where finding similar items or user preferences is crucial.
- Advanced Image and Video Analysis: With vector embeddings, image and video recognition tasks are accelerated. Vector databases enable applications such as object detection, image clustering, facial recognition, video content analysis, and multimedia indexing.
- Anomaly Detection and Fraud Prevention: Vector databases contribute to anomaly detection and fraud prevention by identifying abnormal patterns. By comparing vectors representing normal behaviour, they assist in detecting outliers and identifying fraudulent activities in domains like finance, cybersecurity, and network monitoring.
- Personalized Recommendations: Vector databases support personalized recommendation systems by capturing user preferences and item characteristics. They enable accurate recommendations in e-commerce, content streaming, and social media platforms, improving user engagement and satisfaction.
Conclusion
Vector databases have emerged as a game-changer in the field of artificial intelligence and machine learning, offering efficient storage, retrieval, and analysis of high-dimensional data. The ability of vector databases to handle complex data types, such as images, audio, and graphs, opens up new avenues for innovation and insights.
They empower applications like personalized recommendations, content filtering, image recognition, and graph analysis, revolutionizing various industries and driving data-driven decision-making.
With vector databases, organizations can unlock the true potential of their data, unravel hidden patterns, and gain a competitive edge. They offer scalability, performance, and flexibility to handle large-scale datasets and real-time applications.
Database Monitoring with Atatus
Atatus provides you an in-depth perspective of your database performance by uncovering slow database queries that occur within your requests, and transaction traces to give you actionable insights. With normalized queries, you can see a list of all slow SQL calls to see which tables and operations have the most impact, know exactly which function was used and when it was performed, and see if your modifications improve performance over time.
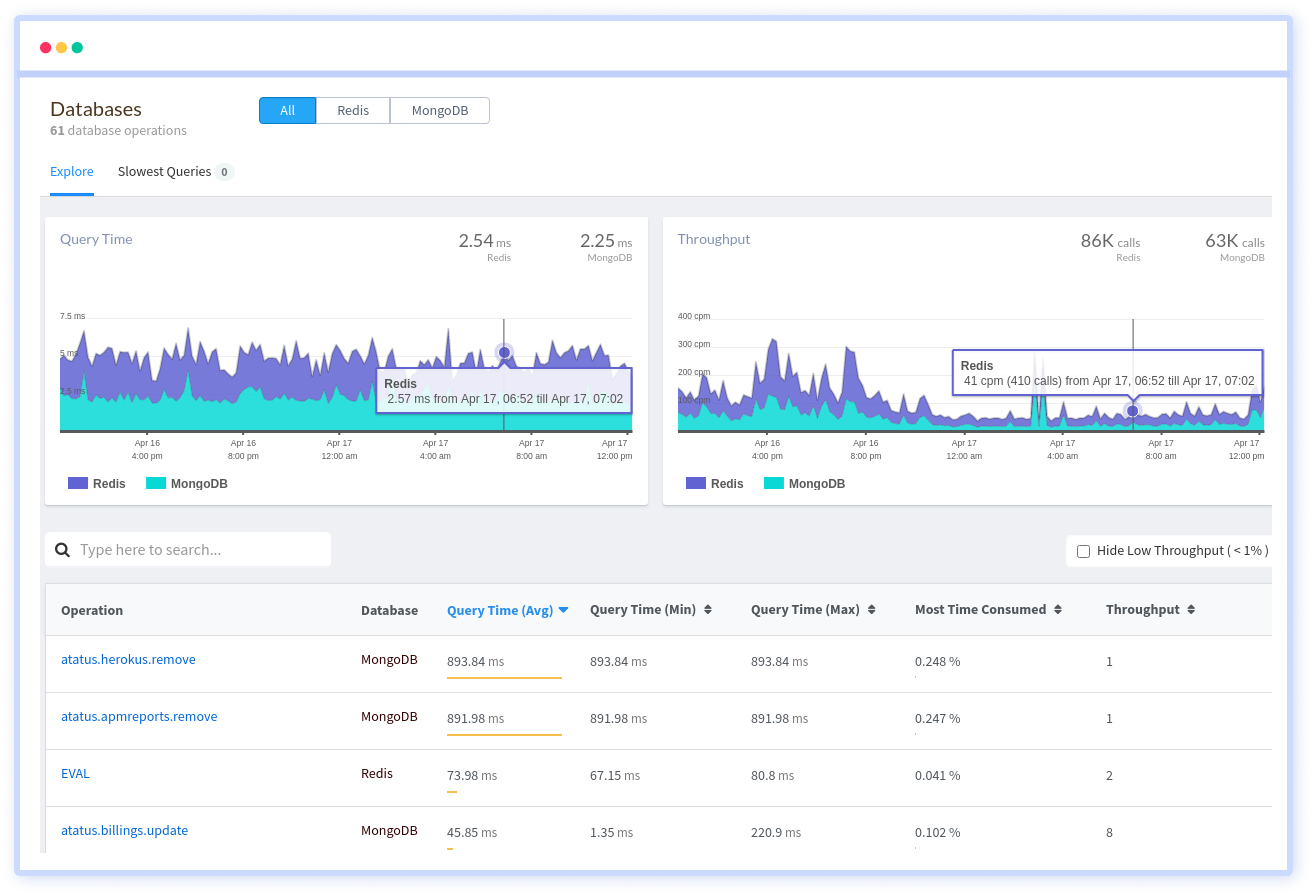
Atatus benefit your business, providing a comprehensive view of your application, including how it works, where performance bottlenecks exist, which users are most impacted, and which errors break your code for your frontend, backend, and infrastructure.
#1 Solution for Logs, Traces & Metrics
![]() APM
APM
![]() Kubernetes
Kubernetes
![]() Logs
Logs
![]() Synthetics
Synthetics
![]() RUM
RUM
![]() Serverless
Serverless
![]() Security
Security
![]() More
More