Ways to Reduce IT Costs with Observability

Imagine you are driving a car with no dashboard. You can't see the speed, fuel level, or engine temperature. You are flying blind, hoping everything is okay until something goes wrong. This is what it's like to manage complex IT systems without observability.
Observability is the key to understanding the internal state of a system. It is crucial for detecting and resolving issues efficiently, reducing downtime and costs. By monitoring logs, metrics, and traces, observability helps you understand system behaviour and performance.
In this blog, we'll discuss how observability can reduce IT costs by providing real-time insights, streamlining troubleshooting, optimizing resource allocation, and improving system reliability.
Lets get started!
- Use Unified Monitoring Platform
- Optimize Data Storage Costs
- Lowering MTTR and MTBF in IT Operations
- Preventive Measures
- Build an Agile Development Culture
- Personnel Costs
- Proactive Root Cause Analysis
Introduction to Observability
Observability refers to the ability to understand and monitor the internal state of a complex system, such as a computer network, based on its external outputs or behaviour. In simpler terms, it's about being able to see what's happening inside a system by observing its external behaviour.
Logs, metrics, and traces are three key components of observability in IT systems.
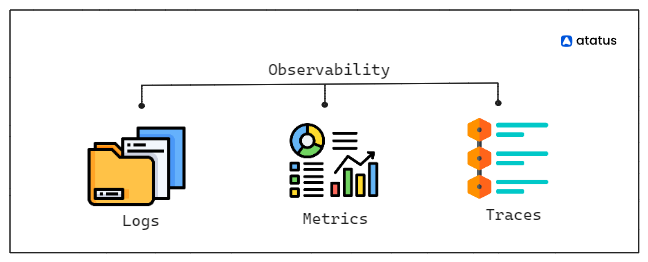
Logs
- Logs are records of events or actions that occur within a system, typically in a text format.
- They are useful for troubleshooting issues, as they provide a detailed history of what happened leading up to a problem.
Metrics
- Metrics are numerical measurements that provide insight into the performance, health, and behaviour of a system.
- They are useful for monitoring the overall health and performance of a system, as they provide a high-level view of how the system is performing.
Traces
Traces are records of the execution path of a request or transaction as it moves through a system.
- They are useful for understanding the performance and behavior of a system at a more granular level, as they provide a detailed view of how individual requests or transactions are processed.
The Role of Observability in Cost Reduction
By using observability tools, organizations can detect issues early, allocate resources efficiently, optimize performance, enhance security, and make informed decisions. Ultimately reducing IT costs and improving overall system reliability.
Let’s see how observability helps in reducing IT costs
1. Use Unified Monitoring Platform
Observability is the ability to understand the internal state of a system based on its external outputs. This is crucial for detecting and resolving issues efficiently. However, having too many observability tools can be costly and complex.
A solution to this is to adopt a single, comprehensive observability tool that can monitor multiple aspects of a system, such as logs, metrics, and traces. By consolidating observability tools, organizations can reduce costs associated with purchasing, maintaining, and training on multiple tools.
Additionally, a unified tool can provide a more holistic view of system health, making it easier to identify and resolve issues.
Atatus, an all-in-one observability platform provides comprehensive full-stack monitoring, delivering immediate, actionable insights for diagnosing and resolving issues in your applications.
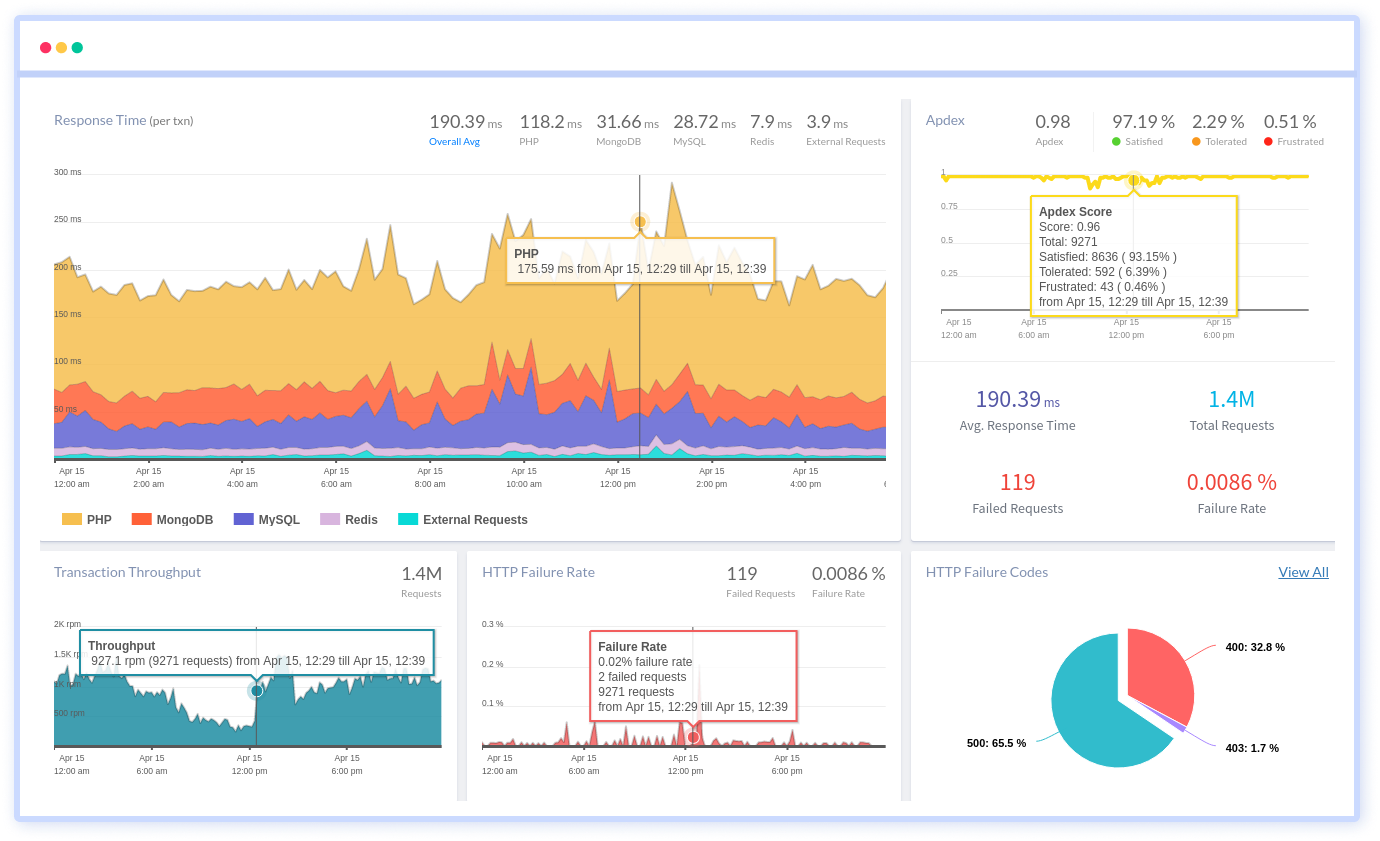
With Atatus, you can utilize unified monitoring system to identify performance bottlenecks and optimize your app, ensuring an optimal digital experience for your users. Atatus also helps you optimize your app by showing you which parts of your code are slowing things down, so you can make improvements and provide an even better experience for your users.
Overall, Atatus is like having a team of experts constantly watching over your website, giving you the information you need to keep your site running smoothly and your customers happy.
2. Optimize Data Storage Costs
Data storage is critical in IT for informed decisions, business continuity, and regulatory compliance. Efficient practices minimize costs and enhance system observability.
Archiving infrequently accessed data optimizes management, reducing expenses and improving performance. Aligning storage with business needs ensures timely access, enhancing efficiency and reducing downtime. Smart storage is crucial for cost savings, operational excellence, and robust performance.
While having observability data is important and a general best practice, it's essential to only store the data that truly matters to you. This can lead to substantial cost reductions.
In short, good data storage practices are essential for saving money, running smoothly, and making sure everything works well.
3. Lowering MTTR and MTBF in IT Operations
Reducing IT costs through observability involves two key metrics: MTTR (Mean Time to Respond) and MTBF (Mean Time Between Failures).
MTTR measures how quickly you can fix a problem when it occurs, while MTBF measures how often problems occur.
By proactively monitoring systems, you can catch problems early, reducing MTTR.
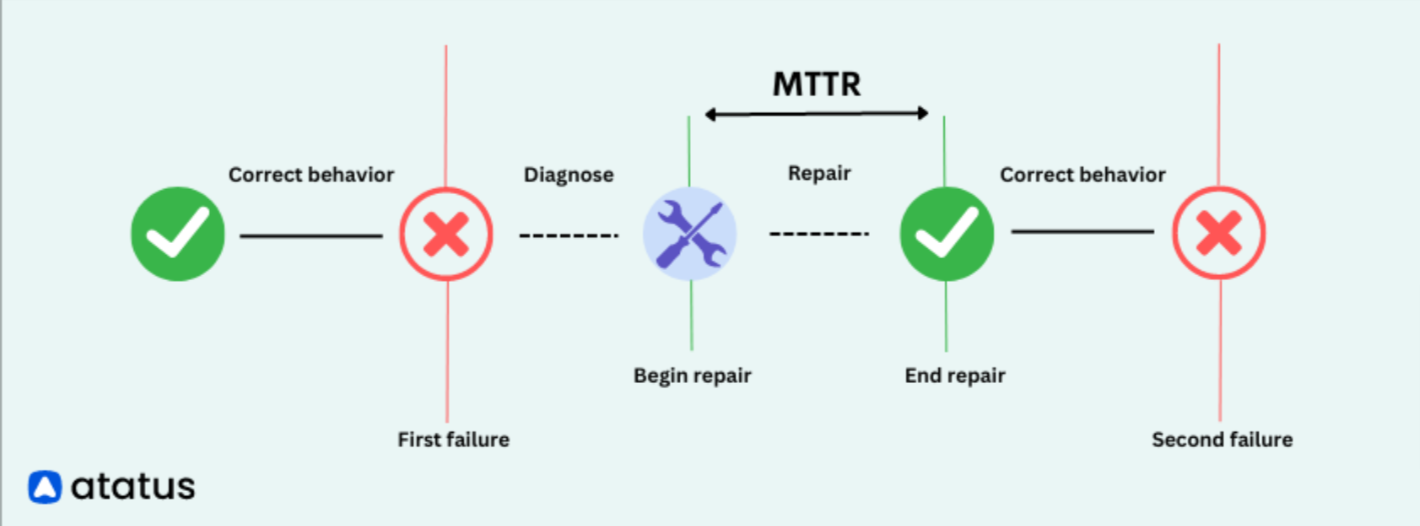
Analysing patterns can help predict and prevent future failures, improving MTBF.
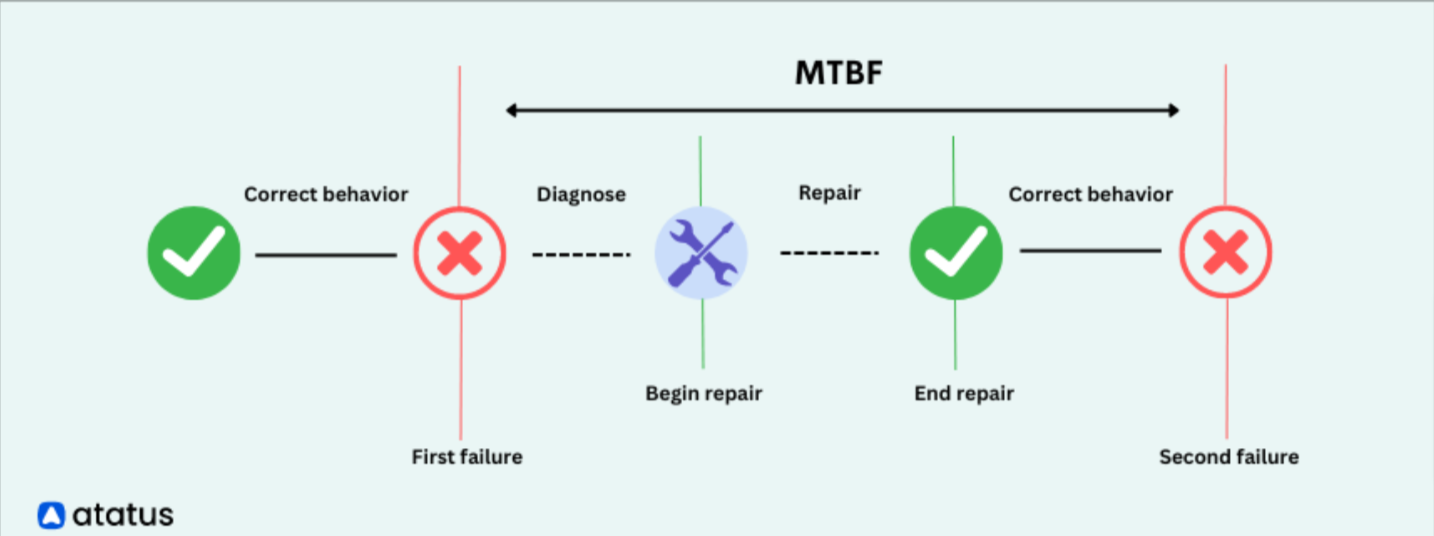
Additionally, automating fixes for common issues reduces manual intervention and shortens MTTR. Investing in reliable infrastructure and best practices in system design can also improve MTBF.
Thus observability helps reduce IT costs by minimizing the time and frequency of system failures, making operations more efficient and reliable.
4. Preventive Measures
In IT, teams often find themselves spending a significant amount of time on tasks that don't directly contribute to the overall success of their projects. However, observability tools present a solution to this challenge by providing real-time insights into the performance and availability of systems.
These tools enable teams to identify and address potential issues before they escalate into significant problems, ultimately saving time and effort.
- Preventive Maintenance: Fix things before they break, which avoids the need for extensive troubleshooting and repair, saving both time and money.
- Outage Prevention: Outages can be costly in terms of lost productivity, revenue, and customer trust. By proactively addressing potential problems, you can prevent system downtime.
- Avoid Unplanned Work: Unplanned work, such as emergency fixes and reactive maintenance, can be expensive due to the need for immediate attention and potential disruption to planned activities.
5. Build an Agile Development Culture
Observability tools help software companies monitor their systems and quickly respond to issues. They detect problems like high CPU usage, which can be caused by inefficient code or algorithms, and help fix them.
These tools also track the system's behaviour without needing code changes, making it easier to find and fix issues after a crash. They can also help track the time it takes for each request, making it easier to find and fix issues with specific parts of the system.
Imagine you have a web application that allows users to upload images. You notice that sometimes, when many users are uploading images at once, the application slows down.
You use an observability tool to monitor the application's performance in real-time. The tool shows you that the CPU usage of the server hosting the application spikes to 100% during these slowdowns.
You investigate further and find that the image processing algorithm used by the application is inefficient and causes the CPU to work harder than necessary. Thus, observability tools help companies keep their systems running smoothly and efficiently.
6. Personnel Costs
In any organization, personnel costs are a significant part of the IT budget. IT personnel are essential for maintaining and managing complex IT systems, but they can also be a significant expense. However, observability tools can help reduce personnel costs by automating routine tasks and streamlining IT operations.
7. Proactive Root Cause Analysis
This approach involves monitoring systems for potential issues, analyzing patterns, and taking preventive measures to ensure continuous uptime. By doing so, you can avoid the need for reactive fixes and minimize the impact of potential problems on your operations.
Suppose you have a network that experiences intermittent slowdowns and connectivity issues. Using observability tools, you identify that the root cause is a misconfigured switch that is causing network congestion during peak hours.
To address this issue proactively, you can reconfigure the switch to optimize network traffic flow and prevent congestion. This proactive approach helps in saving costs by avoiding the need for reactive troubleshooting and repair, minimizing downtime, and optimizing resource allocation.
Conclusion
By leveraging observability tools like Atatus, organizations can streamline troubleshooting, optimize resource allocation, and enhance system reliability. This leads to substantial cost reductions in IT operations.
One of the primary benefits of observability is its ability to simplify IT monitoring through a unified platform. This consolidation reduces costs associated with purchasing, maintaining, and training on multiple tools.
Moreover, a comprehensive observability tool provides a holistic view of system health, facilitating efficient issue identification and resolution. Furthermore, observability aids in cost reduction by optimizing data storage practices. Archiving infrequently accessed data minimizes expenses and enhances system performance.
Aligning storage with business needs ensures timely access, improving efficiency and reducing downtime. Additionally, observability helps lower Mean Time to Respond (MTTR) and Mean Time Between Failures (MTBF) in IT operations. Proactive monitoring and analysis of system patterns enable early issue detection, reducing MTTR. This, coupled with reliable infrastructure and best practices, improves MTBF, making operations more efficient and reliable.
Thus, observability is a key factor in reducing IT costs. It simplifies monitoring, optimizes data storage, and improves system reliability, ultimately leading to significant cost savings.
Monitor Your Entire Application with Atatus
Atatus is a Full Stack Observability Platform that lets you review problems as if they happened in your application. Instead of guessing why errors happen or asking users for screenshots and log dumps, Atatus lets you replay the session to quickly understand what went wrong.
We offer Application Performance Monitoring, Real User Monitoring, Server Monitoring, Logs Monitoring, Synthetic Monitoring, Uptime Monitoring and API Analytics. It works perfectly with any application, regardless of framework, and has plugins.
Atatus can be beneficial to your business, which provides a comprehensive view of your application, including how it works, where performance bottlenecks exist, which users are most impacted, and which errors break your code for your frontend, backend, and infrastructure.
If you are not yet a Atatus customer, you can sign up for a 14-day free trial .
#1 Solution for Logs, Traces & Metrics
![]() APM
APM
![]() Kubernetes
Kubernetes
![]() Logs
Logs
![]() Synthetics
Synthetics
![]() RUM
RUM
![]() Serverless
Serverless
![]() Security
Security
![]() More
More



