
You've arrived early today and need to get ready for an important meeting. However, the printer is not working. Once again, there is a paper jam. If not handled effectively, these kinds of situations can cause major disruptions in your company's key operations. That is, however, the purpose of Incident Management. It assists you in resolving issues so that you and your organization's other callers receive the assistance they require as quickly as feasible.
We will go over the following:
- What is an Incident?
- What is Incident Management?
- Types of Incidents
- Incident Management Process
- Benefits of Incident Management
- Why Incident Management is Important?
What is an Incident?
An incident is a single occurrence in which one of your company's services fails to perform as expected. Internal services are also included. For example, a malfunctioning printer or a computer that won't load up. After an incident has been reported, employees must register it according to ITIL principles. The status of open incidents is tracked until they are resolved and/or closed. Standard solutions can be used in some ITSM applications to swiftly resolve repeated incidents.
Problem vs. Incident
An incident occurs when something breaks or stops working, causing normal service to be disturbed, whereas a problem is a collection of incidents with an unexplained root cause. Problem management is more proactive than incident management, which is usually a reactive procedure. The goal of an incident management system is to swiftly restore services, whereas the goal of a problem management system is to find a long-term solution.
What is Incident Management?
The end-to-end business process of dealing with an outage, service disruption, or other large incidents from its inception to completion is known as incident management. While this definition may appear straightforward, the lifecycle management process is extremely complex, requiring cross-team collaboration, disparate technologies, and distributed systems in order to resolve issues quickly without jeopardizing the customer experience, brand reputation, or, most importantly, the company's bottom line.
When considering how to prioritize presently open incidents, most service organizations additionally consider urgency and impact. For example, a high level of urgency and impact results in a high level of severity. These high-priority problems should be handled as quickly as possible. If an incident is little in intensity, it may be overlooked in favour of more serious incidents.
In a nutshell, Incident Management is an IT Service Management (ITSM) procedure. This procedure is designed to get your organization's services back to normal as quickly as possible. In a way that has little or no negative influence on your primary business, ideally. As a result, problems may rely on temporary solutions while the root cause of the incident is investigated.
Types of Incidents
Incidents that occur in a specific IT environment can be classified and identified in a variety of ways. Some incidents are classified according to their severity or commercial impact, while others are classified according to the reason for the outage. For example, an incident could be as simple as network slowness caused by excessive traffic, or as complex as coping with a container failure for a mission-critical, customer-facing service, which could result in widespread disruptions.
In many commercial situations, incidents are classified according to their severity degree and will look something like this:
- Sev1
- Sev2
- Sev3
- P1
- P2
- P3
Incident Management Process
While incident management can get extremely complicated, the steps can be broken down into the following five steps:
Step 1: Incident Identification
It may seem obvious, but identifying an incident is the first step in incident management. To do so, you'll need to figure out what defines an event in your team's eyes. When your service suffers an unexpected interruption or deterioration in quality, it is referred to as an incident. Since each organization, as well as its infrastructure and applications, is unique, it's critical to think about the various types of issues you can encounter. If your major service is an online store, for example, a potential problem you might see is slower page speeds due to increased site traffic - possibly during a huge sale.
Step 2: Incident Logging
The next step is to properly log and track the incident after it has been detected. Your service desk will most likely handle this. Tickets should include the user's name and contact information, a description of the incident, and the date and time of the incident (needed for SLA clearance).
Step 3: Incident Categorization
After an incident has been recorded, it must be classified. This is critical because every incident should have at least one category (such as "Network") and subcategory (such as "Network Outage") assigned to it. Instead of having to dig through a sea of uncategorized tickets, your service desk will be able to effortlessly navigate through all incidents based on their categories and subcategories. Correct event classification can also aid in identifying patterns, tracking how often similar occurrences occur, and diagnosing larger issues and areas that may require extra training.
Step 4: Incident Prioritization
Prioritization is crucial in any activity or to-do list. Prioritizing incidents based on their severity will clearly distinguish between large incidents that must be resolved immediately and lesser incidents that have a much longer resolution period. The extent of the impact on users and their ability to use the service will determine the priority and urgency of an incident. Your team can automate how certain incident categories and subcategories should be prioritized now that all occurrences have been classified.
In most cases, incidents are prioritized as follows:
- Low-priority Incidents – There are no service interruptions for users.
- Medium-priority Incidents – Some internal employees have been impacted. However, users have had little to no downtime.
- High-priority Incidents – A large number of users are experiencing service interruptions and quality reductions. High-priority incidents frequently have unfavourable financial consequences for the company.
Step 5: Incident Response
It's time to respond to an incident after it's been identified, logged, categorized, and prioritized.
First, your service desk will need to make an initial diagnostic, which will include a detailed description of the problem and answers to troubleshooting questions. Your service desk will evaluate whether or not an incident escalation is required once the situation has been diagnosed. When advanced assistance is required to resolve an issue, an escalation is initiated, and the incident is allocated to the relevant team.
The incident will then be investigated and diagnosed by the appointed team. After confirming the initial event hypothesis, this is usually done during the troubleshooting phase. Your team will apply the necessary fix, such as a software patch, a change in settings, new hardware, and so on, once a diagnosis has been determined. Finally, once an incident has been resolved, your team can close it.
Benefits of Incident Management
The benefits of Incident Management include:
- Increased Productivity and Efficiency
Each incident is handled in the same way by your IT team. This eliminates any uncertainty. - High Service Quality
Your employees will never again misplace tickets in a mailbox or a stack of post-its. They can also quickly prioritize tickets so that the most serious issues are dealt with first. Customers to your company will have higher confidence in the continuance of your (IT) services as a result of this. - More Information about Service Quality
All incidents are actively registered in your Incident Management software. As a result of the monitoring and reporting, your company obtains vital information. - More Transparency and Visibility
Users will know what is occurring with their tickets and when if incidents are handled according to this approach. - Meeting SLAs
The Ticketing Management method allows you to gain a better understanding of your SLAs. And whether you're going to meet them. This allows you to take action where it is required.
Why Incident Management is Important?
One of the most important processes that a company must master is incident management. Service outages may be costly to a company, so teams need a quick and effective means to respond to and repair them.
According to Gartner, several companies estimate downtime costs of more than $300,000 per hour. That number can be much greater for some web-based services.
Teams want a dependable approach for prioritizing events, resolving them faster, and providing better support to users.
When teams are confronted with an incident, they require a plan that allows them to:
- They'll be able to recover quickly if you respond quickly.
- Customers, stakeholders, service owners, and others in the company should all receive clear communication.
- Collaborate efficiently as a team to solve the problem faster and remove the obstacles that are preventing them from resolving the problem.
- Continuously develop in order to learn from these outages and utilize what they've learned to improve service and refine their method in the future.
Conclusion
The team is responsible for supporting reliable applications and infrastructure, from product managers to release managers, customer support to front-end developers. Better collaboration, transparency, and automation throughout the software delivery and incident response process can help you improve your incident management process over time, making customers and employees happy while accelerating business value.
Monitor API Failures with Atatus
Monitoring API failures in production is very hard. You'll need tools like Atatus to figure out which APIs are failing, how often they're failing, and why they're failing.
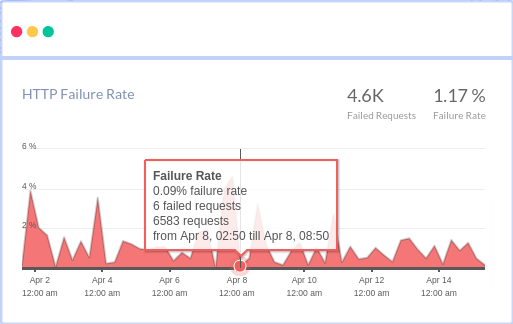
You can see the most common HTTP failures and get detailed information about each request, as well as custom data, to figure out what's causing the failures. You may also view how API failures are broken down by HTTP Status Codes and which end-users have the most impact.



