
A distributed coordination service to handle a large number of hosts is called ZooKeeper. In a distributed environment, maintaining and coordinating a service is a challenging task. ZooKeeper's simple architecture and API address this problem. Because of ZooKeeper, developers can concentrate on the essential logic of their applications rather than worrying about how distributed they are.
We will cover the following:
- What is ZooKeeper?
- Why is Zookeeper Important?
- Types of Zookeeper Nodes
- Architecture of Zookeeper
- How does Zookeeper Works?
- Benefits of Zookeeper
What is ZooKeeper?
An open-source distributed coordination service called Apache Zookeeper helps in the management of numerous hosts. In a dispersed environment, management and coordination may be difficult.
Zookeeper automates this procedure so that developers can concentrate on creating new features rather than worrying about the scattered nature of their work.
Maintaining configuration data, name conventions, and group services for distributed systems are made easier by Zookeeper. To prevent the application from implementing on its own, it implements various protocols on the cluster. It provides a consistent, coherent view of various machines.
A Zookeeper is a central data repository where distributed applications can store and retrieve data. With the help of its synchronization, serialization, and coordination objectives, it keeps the dispersed system operating as a single unit.
For simplicity, Zookeeper can be compared to a file system where data is stored on znodes rather than in files or directories. A tool used by Hadoop admins to manage the jobs in the cluster is called Zookeeper.
As an example, HBase makes use of Apache ZooKeeper to monitor the progress of distributed data.
Simply said, Zookeeper is one of the best cluster coordination systems that make use of the most durable synchronization methods to maintain the cluster's nodes' flawless connectivity.
The management of a distributed environment is solved by Apache Zookeeper due to its simple architecture and API.
Why is Zookeeper Important?
Due to the significant increase in error risk brought on by the large number of machines connected to the network, distributed applications are challenging to coordinate and operate. Deadlocks and race conditions are frequent issues when implementing distributed applications because of the number of machines involved.
When a machine tries to carry out two or more operations at once, a race condition results, however, this can be avoided by using ZooKeeper's serialization attribute. When two or more machines attempt to access the same shared resource at the same time, a deadlock occurs.
More specifically, they attempt to use each other's resources, which causes a system lock because no system is releasing the resource; instead, they are all waiting for the other system to release it.
In Zookeeper, synchronization facilitates breaking the impasse. Partially failing processes in remote applications might result in inconsistent data, which is still another serious problem.
This is handled by Zookeeper using atomicity, which guarantees that either the entire process will succeed or nothing will continue after failure. As a result, Zookeeper is a crucial component that handles these small but crucial concerns so that developers may concentrate more on the functionality of the application.
Types of Zookeeper Nodes
Znodes or Zookeeper nodes can be classified as persistent, ephemeral, or sequential.

1) Persistent
Such a znode is stored in the zookeeper until it is destroyed. This is the znode's standard type.
These kinds of znodes help preserve configuration data, which must endure even if some machines fail. For instance, if a client node fails, its individual information, such as the tasks it is working on, must be preserved so that other workers can use it.
2) Ephemeral
The ephemeral node is eliminated if the session in which it was created has ended. Other users can still see it even though it is associated with the client's session.
These kinds of znodes are useful when we need to maintain track of the currently active machines in our cluster. When a computer associated with a znode ceases to be active, the znode is erased, signifying the machine's absence.
This prompts the required action to be taken and increases the system's availability. For example, another machine may be activated or brought into service as a backup.
3) Sequential
We frequently need to generate sequential numbers, such as ids. In these cases, we use consecutive nodes.
Znodes are created with the given name attached and in numerical order. This number increases monotonically as new nodes are added inside of each existing node. Any node's first consecutive child node receives the suffix 0000000000.
Architecture of Zookeeper
Client-Server architecture is used by Apache Zookeeper. The five components that make up the Zookeeper architecture are as follows:
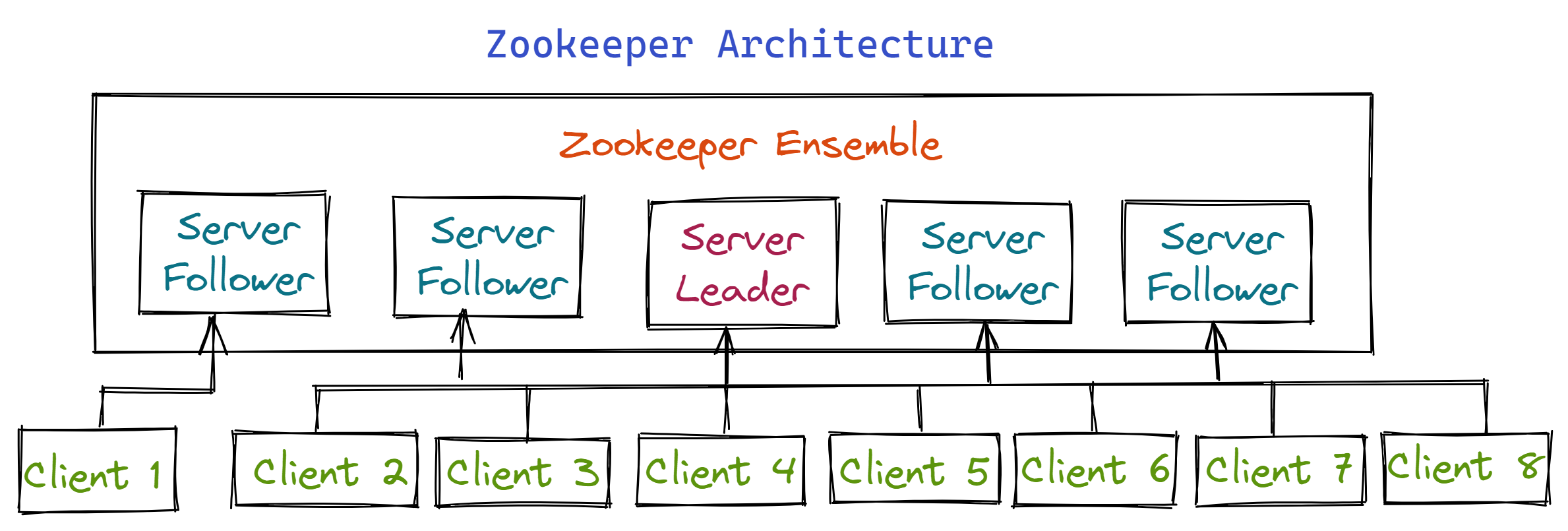
- Server
When any client connects, the server sends an acknowledgment. The client will automatically forward the message to another server if the connected server doesn't respond. - Client
One of the nodes in the distributed application cluster is called Client. You can access server-side data more easily as a result. Each client notifies the server that it is still alive regularly with a message. - Leader
A Leader server is chosen from the group of servers. The client is informed that the server is still live and is given access to all the data. If any of the connected nodes failed, automatic recovery would be carried out. - Follower
A follower is a server node that complies with the instructions of the leader. Client read requests are handled by the associated Zookeeper server. The Zookeeper leader responds to client write requests. - Ensemble/Cluster
a cluster or ensemble is a group of Zookeeper servers. When running Apache, you can use ZooKeeper infrastructure in cluster mode to keep the system functioning at its best. - ZooKeeper WebUI
You must utilize WebUI if you wish to deal with ZooKeeper resource management. Instead of utilizing the command line, it enables using the web user interface to interact with ZooKeeper. It allows for a quick and efficient connection with the ZooKeeper application.
How does Zookeeper Works?
Hadoop ZooKeeper is a distributed application that uses a simple client-server architecture, with clients acting as service-using nodes and servers as service-providing nodes. The ZooKeeper ensemble is the collective name for several server nodes.
One ZooKeeper client is connected to at least one ZooKeeper server at any one time. Because a master node is dynamically selected by the ensemble in consensus, an ensemble of Zookeeper is often an odd number, ensuring a majority vote.
If the master node fails, a new master is quickly selected and replaces the failed master. In addition to the master and slaves, Zookeeper also has watchers.
Scaling was a problem, therefore observers were brought in. The performance of writing will be impacted by the addition of slaves because voting is an expensive procedure. Therefore, observers are slaves who perform similar tasks to other slaves but do not participate in voting.
Writes in Zookeeper
All writes in Zookeeper pass through the Master node. All writes are sequential as a result. Each of the servers connected to that client and performing the write operation in Zookeeper persists data alongside the master.
This updates the data on all the servers. We are unable to do concurrent writes as a result. If we use Zookeeper for the majority of the writing effort, the guarantee for linear writing may become a concern.
In Hadoop, Zookeeper is used to coordinate message exchanges between clients that primarily involve reads rather than writes. Hadoop's zookeeper is useful for data sharing.
Zookeeper, however, may get in the way of the application and impose strict ordering of the actions if the application involves concurrent data writing.
Reads in Zookeeper
The best reader is the zookeeper. Concurrent reading is possible. Concurrent reads happen in Zookeeper because every client is connected to a different server and can read data from those servers all at once.
The client might occasionally hold an outmoded opinion. Within a short period, this is updated.
Benefits of Zookeeper
Here are several benefits of utilizing ZooKeeper:
- Atomicity
No data transfer is partial; it either succeeds completely or fails. - Reliability
If a single node or a small number of systems die, the entire system does not collapse. - Transparency
It presents itself as a single unit or application while concealing the system's overall complexity. - Scalability
By adding more machines and making small adjustments to the application settings as needed, we can effectively enhance performance without experiencing any downtime. - Serialization
Data should be encoded using precise guidelines. Make sure your application functions consistently. This method can be applied to MapReduce to synchronize the execution of running threads from the queue. - Synchronization
Collaboration and mutual exclusion between server processes. This procedure helps Apache HBase in managing configuration.
Conclusion
Simply put, Apache ZooKeeper is a distributed coordination service for overseeing a sizable number of servers. The management of a distributed environment is solved by Apache Zookeeper due to its simple architecture and API.
The comprehensive mechanism for solving every difficulty faced by distributed applications is provided by the ZooKeeper framework. It provides several services, including configuration management and naming services.
Also Read:
Infrastructure Management (IM)
Atatus API Monitoring and Observability
Atatus provides Powerful API Observability to help you debug and prevent API issues. It monitors the user experience and be notified when abnormalities or issues arise. You can deeply understand who is using your APIs, how they are used, and the payloads they are sending.
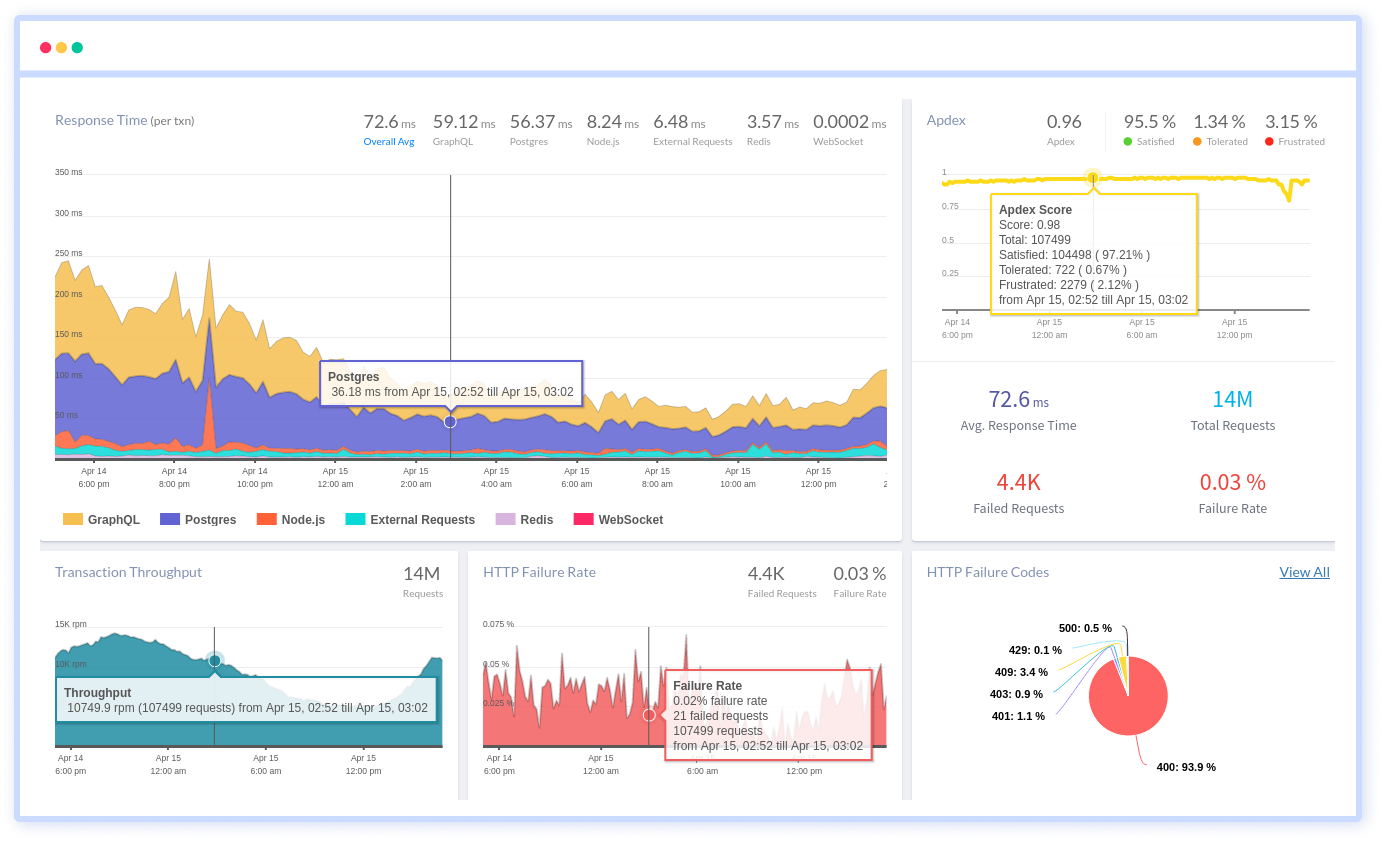
Atatus's user-centric API observability monitors the functionality, availability, and performance of your internal, external, and third-party APIs to see how your actual users interact with the API in your application. It also validates rest APIs and keeps track of metrics like latency, response time, and other performance indicators to ensure your application runs smoothly. Customers can easily get metrics on their quota usage, SLAs, and more.
