Traffic Distribution and Backend Health Execution Insights
Understand routing behavior, failover triggers, and connection pressure across HAProxy-managed services.
Monitor HAProxy logs to troubleshoot load balancing and traffic routing issues
Analyze request routing logs
Inspect HAProxy logs to understand frontend to backend routing decisions and request handling flow.
Track backend server health
Monitor HAProxy log entries related to backend server failures, health check errors, and server state changes.
Detect timeout and retry issues
Capture HAProxy logs indicating connection timeouts, retries, and queue overflows affecting traffic.
Monitor connection limits
Analyze logs for max connection breaches and queue saturation during traffic surges.
Track SSL termination errors
Inspect HAProxy SSL log entries for certificate issues and handshake failures.
Observe load balancing behavior
Analyze HAProxy logs to understand server selection and balancing algorithms in action.
Detect malformed requests
Identify invalid or incomplete requests captured by HAProxy during traffic processing.
Correlate proxy and service logs
Link HAProxy logs with backend service logs to trace traffic-related failures.
Traffic Routing and Request Handling
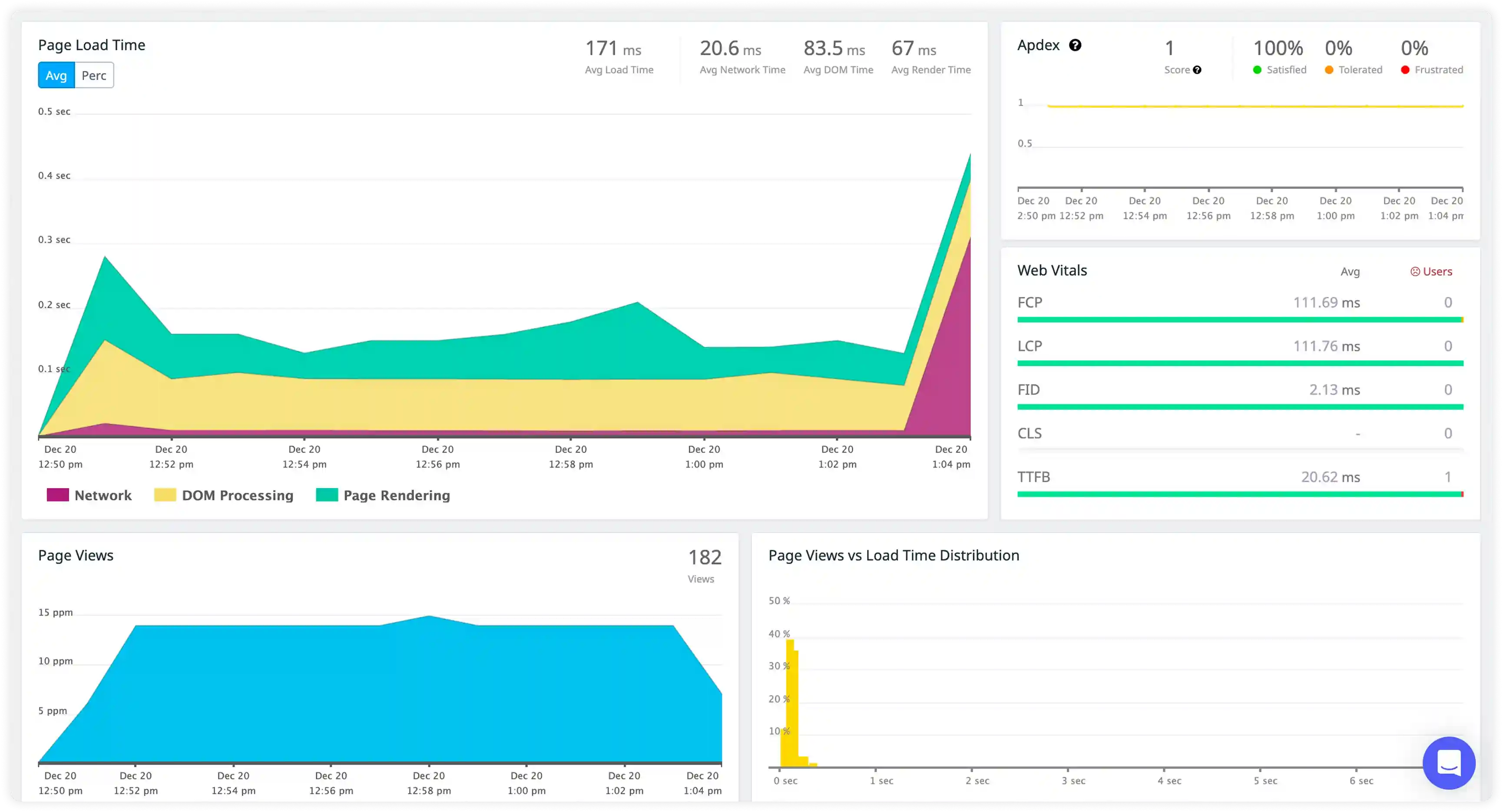
- Monitor HAProxy logs capturing frontend requests, backend routing decisions, HTTP status codes, and session details to understand how traffic is distributed across services.
- Correlate request paths, backend selection, and load-balancing algorithms to trace end-to-end request routing behavior.
- Identify failed routing attempts, retries, and backend response issues impacting service delivery.
- Detect disruptions in traffic flow that affect application availability and request reliability.
Backend Health and Failover Behavior
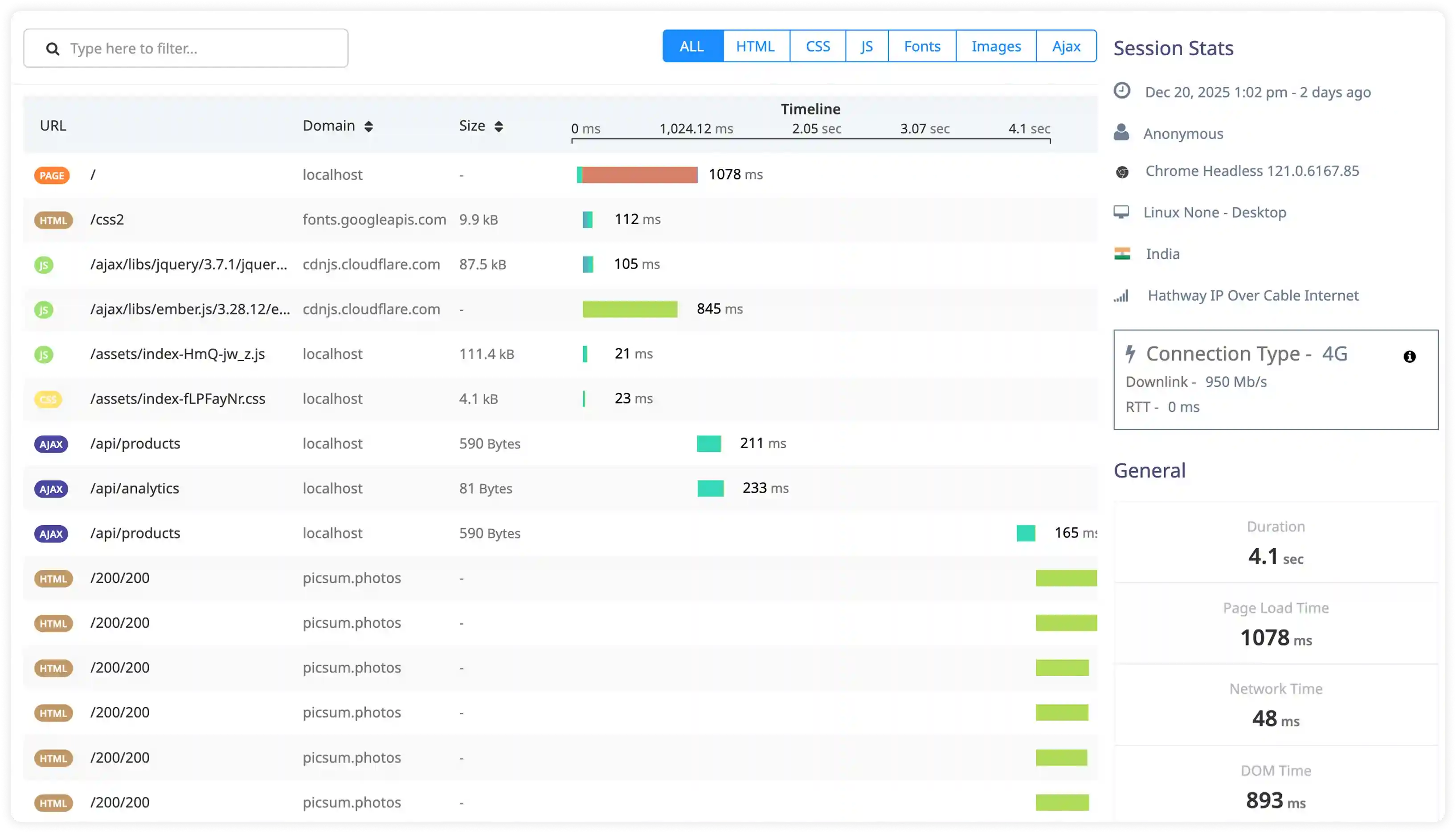
- Capture health check logs, backend state changes, and failover events across HAProxy-managed services.
- Correlate backend availability, response failures, and node health with traffic spikes and infrastructure conditions.
- Identify recurring health check failures and unstable backend nodes reducing load-balancing efficiency.
- Detect operational risks impacting failover readiness and overall service continuity.
Performance and Connection Insights
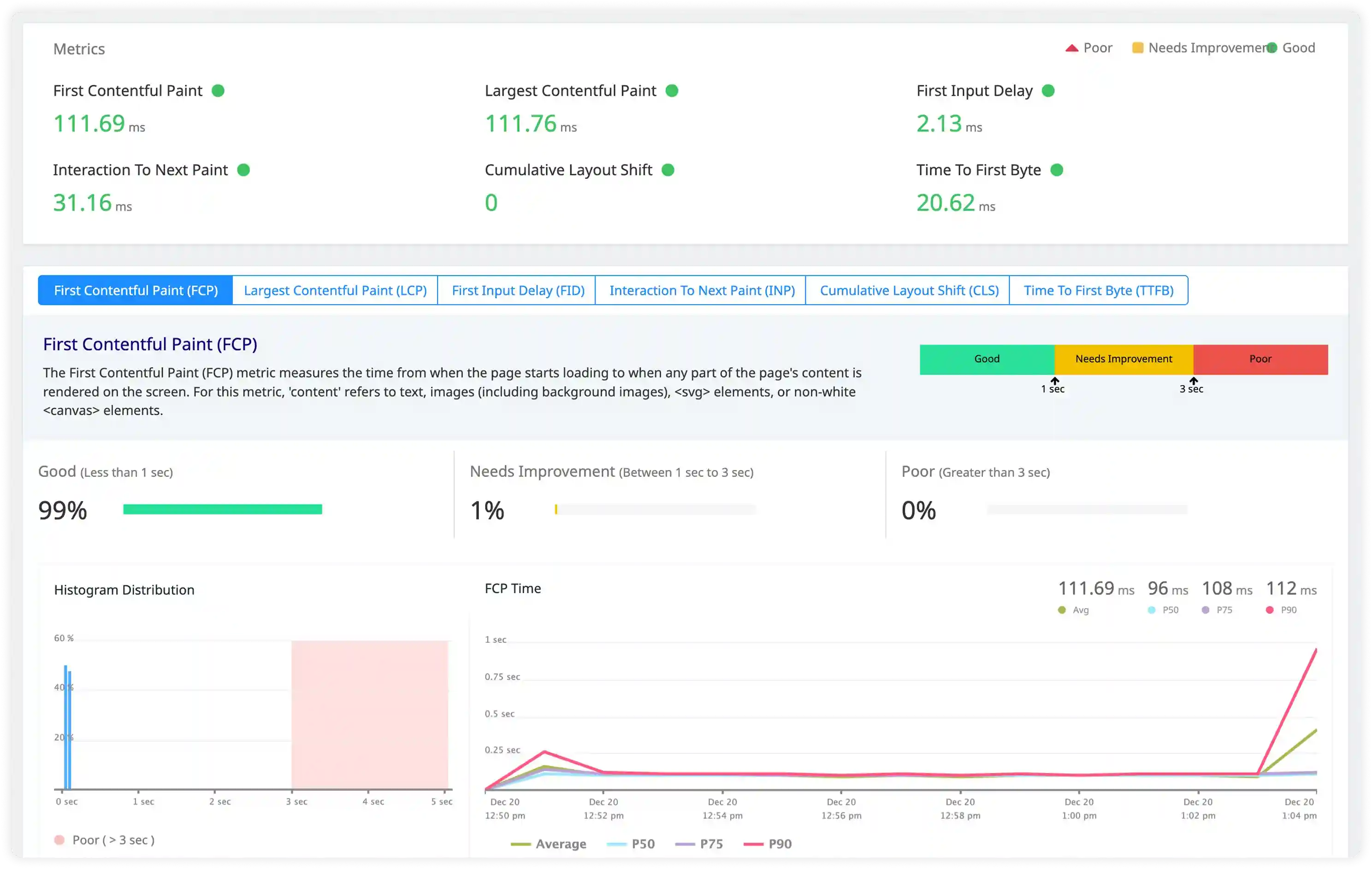
- Analyze connection timing logs, queue wait times, and session duration metrics influencing HAProxy performance.
- Correlate request rates, concurrent connections, and backend processing times with observed latency patterns.
- Identify connection saturation, slow backends, and queue buildup that increase response delays.
- Detect performance degradation through abnormal timing metrics and traffic imbalance.
Security and Access Monitoring
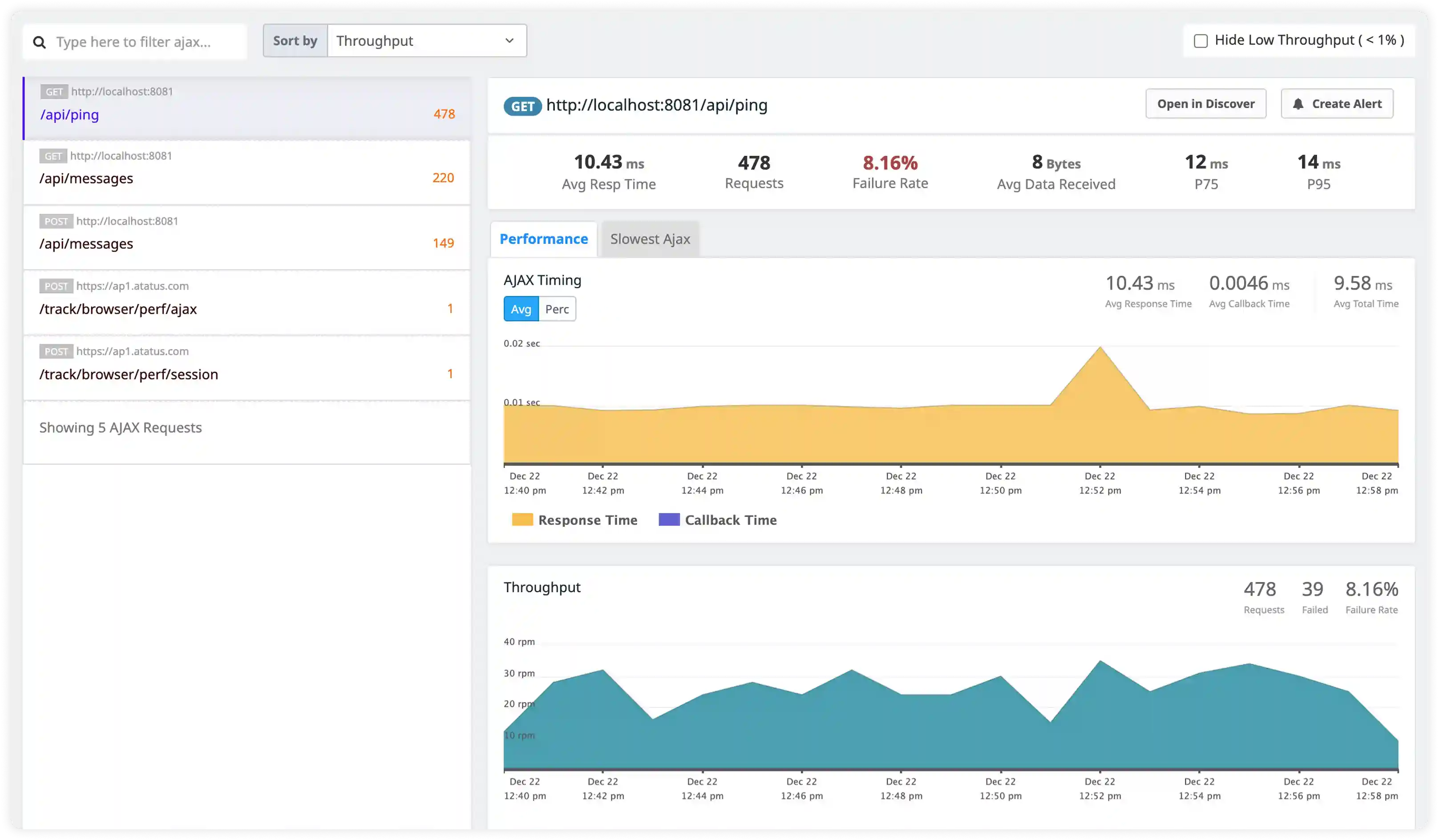
- Track unusual connection patterns, denied requests, and suspicious client behavior captured in HAProxy logs.
- Identify misuse attempts, malformed requests, and unauthorized traffic impacting service integrity.
- Correlate access activity with application and infrastructure events for security incident investigation.
- Detect operational and security risks affecting HAProxy deployments.
Why teams choose Atatus for HAProxy logs monitoring
HAProxy-native parsing
Atatus interprets HAProxy access and error logs with frontend, backend, and timing details.
Load balancer visibility
Atatus centralizes logs across HAProxy instances to monitor traffic distribution and health.
Failure pattern detection
Atatus identifies backend failures, connection errors, and timeout spikes quickly.
Real-time alerting
Atatus triggers alerts on abnormal status codes, retries, and service degradation.
Service correlation
Atatus links HAProxy events with application and infrastructure logs for full request tracing.
High-volume ingestion
Atatus reliably processes HAProxy logs during traffic surges and scaling events.
Unified Observability for Every Engineering Team
Atatus adapts to how engineering teams work across development, operations, and reliability.
Developers
Trace requests, debug errors, and identify performance issues at the code level with clear context.
DevOps
Track deployments, monitor infrastructure impact, and understand how releases affect application stability.
Release Engineer
Measure service health, latency, and error rates to maintain reliability and reduce production risk.