Observability Platform for Developer to Debug Faster
Real-time insights into errors, distributed traces, and performance bottlenecks. Unified in one workflow to diagnose production issues with clarity.
68%
Faster mean time to resolution
4x
Reduction in debugging time
92%
Fewer missed production issues
5mins
Average time to first insight
Know exactly what your deploy broke instantly
Atatus pins every deployment directly to your error rates, latency, and service health. The moment code hits production, you see its impact, not 20 minutes later when support tickets arrive.
Unclear Error Origins Your PR passed all tests, deployed clean, then customers hit a 500 error you've never seen before. No stack trace, no breadcrumb, no clue where it started.
Tool Sprawl Errors in Sentry, logs in CloudWatch, traces in Jaeger, metrics in Grafana. You're not debugging, you're tab managing across four dashboards simultaneously.
Distributed System Debugging A request hits your API gateway, travels through 4 microservices, then fails somewhere in the middle. Tracing that manually across services takes hours, not minutes.
Zero Production Visibility By the time you find out something is broken, the error's been live for 20 minutes and users have already opened support tickets. You're always reacting, never anticipating.
Ship fast. Break nothing. Know instantly.
Atatus plugs into your local environment and CI/CD pipeline, so issues surface before users ever see them, not after.
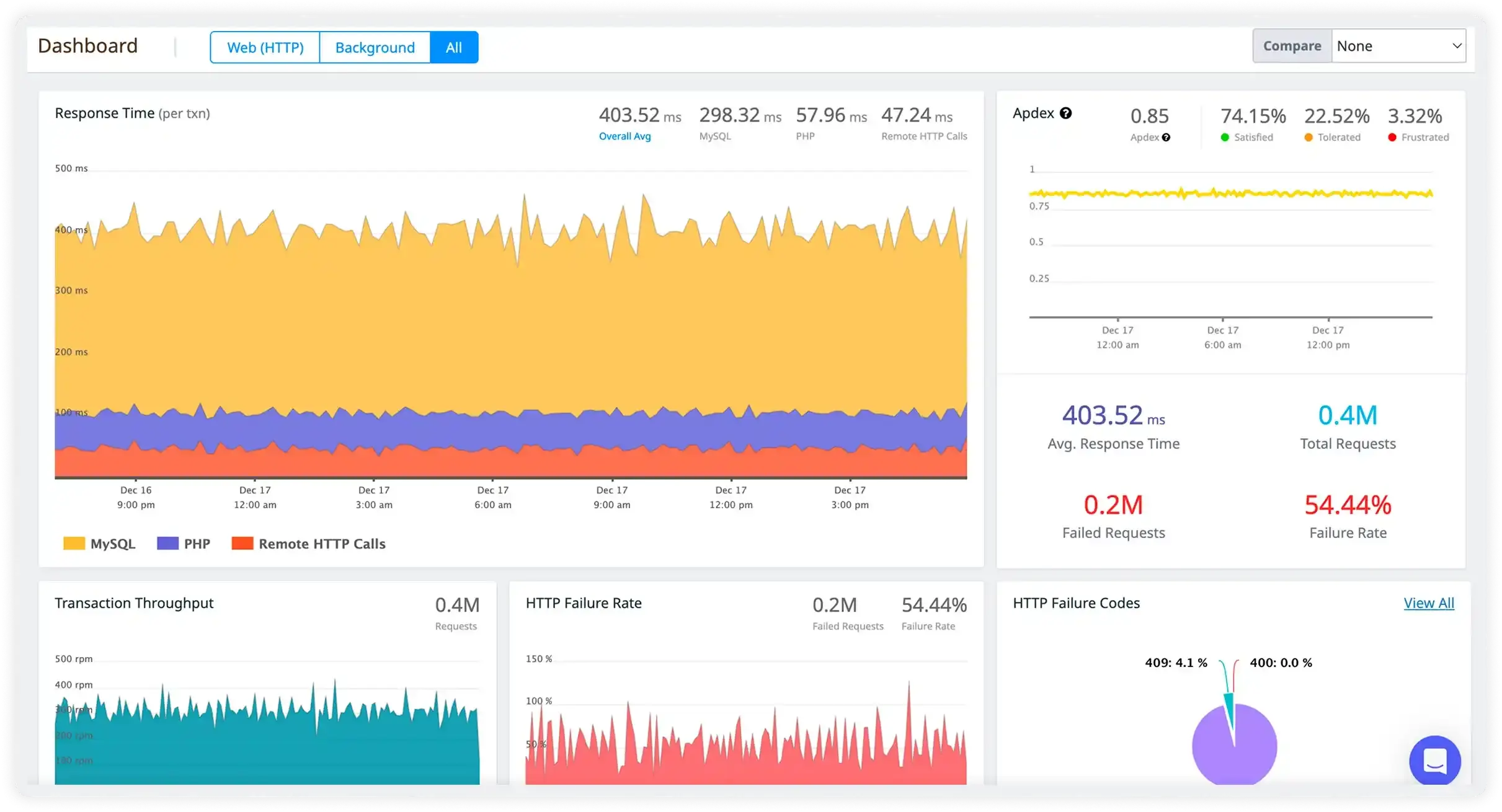
One platform for your entire debugging workflow
Atatus correlates each deployment with live error rates, latency, and Apdex the moment code hits production. No more waiting for support tickets to know if something broke.
- Deploy markers pinned automatically to every metric and trace timeline
- Monitor staging, preview, and production environments side by side
- Instant rollback signal, know within 60 seconds if error rate spikes
Get to the root cause before users do
Other tools tell you something broke. Atatus shows you what broke, which deploy caused it, and where in your code to fix it without switching tabs.
Quick setup, zero config
Get started in minutes with auto-instrumentation for your stack. No manual setup, no complex configs. Install the SDK and start seeing data right away.
<1% performance overhead
Built to be lightweight in production. Collect the data you need without impacting application performance or increasing latency.
Smart anomaly detection
Detect spikes in errors, latency, and throughput automatically. Alerts are based on real patterns, so you're notified when something actually needs attention.
Predictable, fair pricing
Transparent pricing with clear usage limits. No hidden charges or surprise bills as your usage grows.
Everything in one tab. Nothing left to correlate manually
Real-Time Error Tracking
Catch every exception the moment it happens. Full stack traces, user context, environment metadata, and smart grouping out of the box.
Distributed Tracing
Follow a request across every service, database call, and external API. Visualize latency waterfalls and pinpoint exactly where time is lost.
Performance Monitoring
Track response times, throughput, and error rates across every endpoint. P95/P99 latencies, apdex scores, and slow transaction profiling.
Logs Correlation
Logs aren't isolated anymore. Every log line is correlated with the trace and error that generated it. Search, filter, and stream in real time.
Release Tracking
Every deployment is marked on your performance timeline. See exactly which release introduced a regression before customers do.
Smart Alerting
Anomaly-based alerts that learn your baseline. Get paged when it matters, not every time a metric twitches. Slack, PagerDuty, and webhooks built in.
Works with your entire stack
Built for every developer workflow
Fix Production Issues Faster
Get alerted instantly with full context. Error message, stack trace, affected users, related deployments, and correlated logs in one view. No more Slack ping archaeology.
Improve Code Quality Continuously
Track error rates, performance regressions, and new issues per release. Understand which PRs introduce problems and measure quality trends over time.
Cut Debugging Time in Half
Stop the context-switching tax. Everything you need to understand what happened is already correlated. From alert to fix in minutes, not hours.
Ship Releases with Confidence
Watch your release roll out in real time. Canary deployments, error rate comparisons between versions, and automated rollback triggers if things go wrong.
Unified Observability for Every Engineering Team
Atatus adapts to how engineering teams work across development, operations, and reliability.
Developers
Trace requests, debug errors, and identify performance issues at the code level with clear context.
DevOps
Track deployments, monitor infrastructure impact, and understand how releases affect application stability.
Release Engineer
Measure service health, latency, and error rates to maintain reliability and reduce production risk.
Powering better performance
for modern teams
Feedback from teams improving monitoring and debugging workflows
"Solid Product even better support", The integration path is incredibly simple/easy and the overall interface is very intuitive. That said, I had a handful of odd use cases that the support team was incredibly responsive in helping me work through.

Wes D
Site Reliability Engineer