A Beginner's Guide to DOM (Document Object Model)

Since the turn of the century, websites have progressed dramatically. What used to be a network of basic text-based pages has developed into a network of carefully created experiences, complete with responsive buttons, parallax scrolling, and tailored information.
These website design aspects don't appear out of anywhere, of course. These strategies can be difficult to execute, and they frequently require the collaboration of multiple files and programming languages in order to create a unified experience.
Your website's files must be able to communicate with one another in order to create well-designed, engaging web pages, and the Document Object Model (or DOM) makes this possible. In this article, I'll explain what the Document Object Model is and how does it work.
- Introduction
- What is DOM?
- DOM Tree and Nodes
- DOM Interfaces
- DOM Implementations
- How to Access Elements In the DOM?
- Document Object Model Methods
- Why Do We Require the DOM?
- Disadvantages of DOM
Introduction
The Document Object Model (DOM) is a document programming API for HTML and XML. It defines how documents are accessed and edited, as well as their logical structure.
The term "document" is used in the DOM specification in a broad sense; XML is rapidly being used to represent many different kinds of information that may be kept in various systems, and most of this would traditionally be considered data rather than documents. XML, on the other hand, provides this information as documents, and the DOM may be used to manipulate it.
Programmers can utilise the DOM to build and create documents, as well as browse their structure and add, update, and delete elements and data.
With a few exceptions, the Document Object Model can read, alter, delete, or add anything found in an HTML or XML document, with the exception that the DOM interfaces for the internal and external subsets have not yet been described.
One of the main goals of the Document Object Model as a W3C definition is to provide a common programming interface that can be utilised in a wide range of environments and applications. The Document Object Model can be used in any programming language.
What is DOM?
A website is made up of HTML documents at its most basic level. The browser you're using to access the website is a program that decodes HTML and CSS and renders the style, content, and structure into the page you see.
The browser builds a representation of the document known as the Document Object Model in addition to processing the style and structure of the HTML and CSS. This paradigm allows JavaScript to access the website document's text content and elements as objects.
The Document Object Model (DOM) is a document-specific programming API. The structure of the object model closely resembles that of the documents it represents. Consider the following table:
<TABLE>
<ROWS>
<TR>
<TD>Atatus</TD>
<TD>APM</TD>
</TR>
<TR>
<TD>LeadMine</TD>
<TD>Lead Generator</TD>
</TR>
</ROWS>
</TABLE>This table is represented in the Document Object Model as follows:
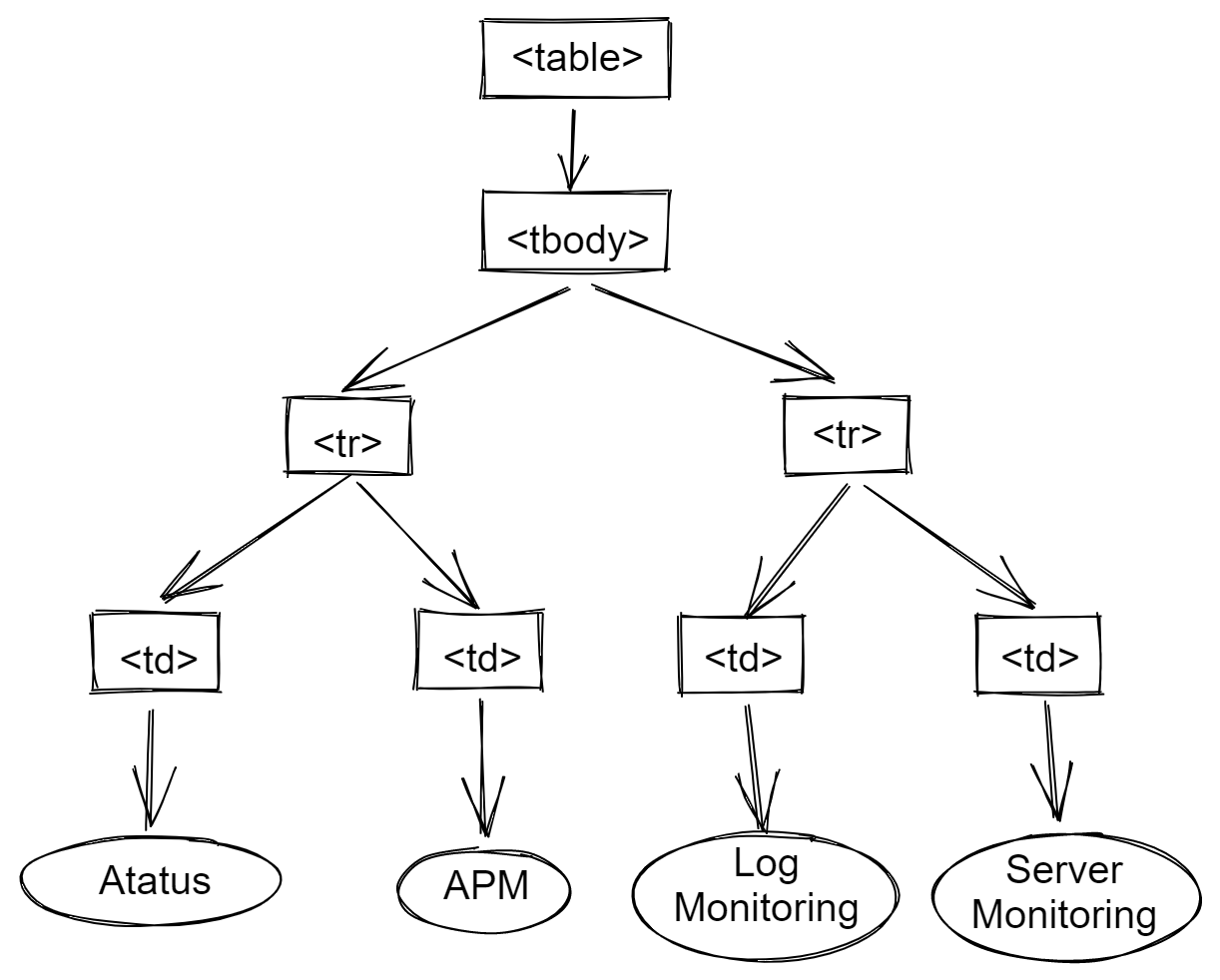
Documents in the Document Object Model have a logical structure that resembles a tree.
To be more exact, it resembles a "forest" that can contain multiple trees. Documents do not need to be implemented as a tree or grove, and object relationships do not need to be declared in any form.
In other words, the object model describes the conceptual model for the programming interface, which may be implemented in any way that a given implementation deems appropriate. We use the term structure model to describe a document's tree-like representation in this specification.
Structural isomorphism is an important property of DOM structure models: if two Document Object Model implementations are used to construct a representation of the same document, they will produce the same structure model, with the exact same objects and relationships.
The term "Document Object Model" was chosen because it is an "object model" in the classic sense: documents are defined using objects, and the model incorporates not just a document's structure, but also its behaviour and the objects that make it up.
To put it another way, the nodes in the diagram above are objects with functions and identities, rather than data structures. The Document Object Model specifies the following as an object model:
- The objects and interfaces that are used to represent and manipulate a document
- The semantics of these objects and interfaces, which includes both behaviour and properties
- The connections and collaborations that exist between these interfaces and objects
An abstract data model, not an object model, has typically been used to depict the structure of SGML documents. In an abstract data model, the data is at the heart of the model. The data is contained in objects in object-oriented programming languages, which hide the data and protect it from direct external alteration. The object model includes the functions associated with these objects, which dictate how they can be manipulated.
DOM Core and DOM HTML are the two parts of the Document Object Model at the moment. The DOM Core is the foundation for DOM HTML and represents the functionality used in XML documents.
All DOM implementations must provide the "basic" interfaces indicated in the Core standard; XML implementations must also support the "extended" interfaces listed in the Core specification. Additional capability for HTML pages is defined in the Level 1 DOM HTML specification.
DOM Tree and Nodes
In the DOM, all items are defined as nodes. There are many different sorts of nodes, however, we mostly work with three of them:
- Element nodes
- Text nodes
- Comment nodes
An element node is a name given to an HTML element that is a DOM entity. A text node is any lone text outside of an element, and a comment node is an HTML comment. The document is a document node, which is the root of all other nodes, in addition to these three-node kinds.
The DOM is made up of nested nodes that form a tree structure known as the DOM tree. An ancestral family tree, which includes parents, children, and siblings, maybe recognisable to you. Depending on their relation to other nodes, nodes in the DOM are referred to as parents, children, or siblings.
Create a nodes.html file to demonstrate. Text, comment, and element nodes will be added.
<!DOCTYPE html>
<html>
<head>
<title>Learning About Nodes</title>
</head>
<body>
<h1>An element node</h1>
<!-- a comment node -->A text node. </body>
</html>The parent node is the HTML element node. HTML's children, head and body, are siblings. The body has three child nodes, all of which are siblings – the type of node has no bearing on the nested level.
DOM Interfaces
There are a number of points where understanding how these functions can be difficult. The HTMLFormElement interface, for example, provides the name property of an object representing an HTML form element, while the HTMLElement interface provides the className property. The property you're looking for is in that form object in both circumstances.
However, because the relationship between objects and the DOM interfaces that they implement can be confusing, this section tries to describe the DOM specification's actual interfaces and how they are made available.
Interfaces and Objects
Many objects use interfaces from a variety of sources. For example, the table object implements the HTMLTableElement interface, which has methods like createCaption and insertRow. Table, on the other hand, implements the Element interface mentioned in the DOM Element Reference chapter because it's also an HTML element.
Finally, the table object implements the more fundamental Node interface, from which Element derives, because an HTML element is actually a node in the tree of nodes that make up the object model for an HTML or XML page as far as the DOM is concerned.
When you get a reference to a table object, as in the example below, you probably utilise all three of these interfaces on the object without even realising it.
const table = document.getElementById("table");
const tableAttrs = table.attributes; // Node/Element interface
for (let i = 0; i < tableAttrs.length; i++) {
// HTMLTableElement interface: border attribute
if (tableAttrs[i].nodeName.toLowerCase() === "border") {
table.border = "1";
}
}
// HTMLTableElement interface: summary attribute
table.summary = "note: increased border";Core Interfaces in the DOM
This section contains a list of some of the most often used DOM interfaces. The goal here isn't to explain what these APIs do, but to give you a concept of the types of methods and attributes you'll encounter frequently when you work with the DOM.
In DOM programming, the document and window objects are the objects whose interfaces you utilise the most. In simple terms, the window object represents a browser, whereas the document object represents the document's root.
The generic Node interface is inherited by Element, and these two interfaces together provide many of the methods and properties you use on specific elements. These elements may also have unique interfaces for dealing with the type of data they hold.
DOM Implementations
The Document Object Model (DOM) defines interfaces for managing XML and HTML documents. It's crucial to remember that these interfaces are just that: Abstractions. They're a way of establishing a way to access and control an application's internal representation of a document, much like "abstract base classes" in C++.
Interfaces, in particular, do not entail a certain implementation. As long as the Interfaces shown in this specification are maintained, each DOM application is allowed to retain documents in any suitable representation.
Existing programs that use the DOM interfaces to access software built before the DOM specification existed will make up some of the DOM implementations. As a result, the DOM is built to avoid implementation dependencies; specifically,
- Attributes declared in the IDL do not imply concrete objects with specific data members; they are translated to a pair of get()/set() functions rather than a data member in the language bindings.
- While DOM applications can include other interfaces and objects not covered by this specification, they must nonetheless be DOM compatible.
- The DOM cannot know which constructors to call for implementation since we specify interfaces rather than the actual objects to be produced. DOM users construct document structures by calling the Document class's createXXX() methods, and DOM implementations create their own internal representations of these structures in their implementations of the createXXX() functions.
How to Access Elements In the DOM?
It is required to have a working grasp of CSS selectors, syntax, and terminology, as well as an understanding of HTML elements, in order to be proficient at accessing elements in the DOM.
#1 Accessing Elements by ID
The most convenient approach to access a single element in the DOM is using its unique ID. The getElementById() method of the document object can be used to fetch an element by ID.
document.getElementById();The HTML element must have an id property in order to be accessed by ID. A div element with the ID demo exists.
<div id="demo">Access me by ID</div>Getting an element in the DOM by ID is a quick and efficient approach to get it. However, because an ID must always be unique to the page, the getElementById() method can only be used to access a single element at a time. If you were to add a function to a lot of different components on the page, your code would become repetitive rapidly.
#2 Accessing Elements by Class
The class attribute allows you to access one or more specified DOM elements. The getElementsByClassName() method returns all elements with a given class name.
document.getElementsByClassName();Now we need to access numerous elements, and we have two elements with the demo class in our example.
<div class="demo">Access me by class (1)</div>
<div class="demo">Access me by class (2)</div>#3 Accessing Elements by Tag
The HTML tag name is a less specific way to access numerous elements on the page. The getElementsByTagName() method allows us to access an element by its tag name.
document.getElementsByTagName();We'll use article elements in our tag example.
<article>Access me by tag (1)</article>
<article>Access me by tag (2)</article>#4 Query Selectors
If you've used the jQuery API before, you're presumably familiar with the way jQuery accesses the DOM using CSS selectors.
$('#demo'); // returns the demo ID element in jQueryThe querySelector() and querySelectorAll() methods in plain JavaScript can perform the same thing.
document.querySelector();
document.querySelectorAll();The querySelector() method will be used to access a single element. We have a demo-query element in our HTML file.
<div id="demo-query">Access me by query</div>The hash symbol (#) is used as an id attribute selector. The demoQuery variable can be assigned to the element with the demo-query id.
Document Object Model Methods
Let's look at a few popular ones:
1) querySelectorAll() method
This method is used to access one or more DOM components that match one or more CSS selectors:
<div> first div </div>
<p> first paragraph </p>
<div> second div </div>
<p> second paragraph </p>
<div> another div </div>var paragraphs = document.querySelectorAll('p');
paragraphs.forEach(paragraph => paragraph.display = 'none')
createElement() methodThis method is used to construct and insert a specific element into the DOM:
<div> first div </div>
<p> first paragraph </p>
<div> second div </div>
<p> second paragraph </p>
<div> another div </div>var thirdParagraph = document.createElement('p');2) getElementById() method
This method is used to retrieve an element from a document based on its unique id attribute:
<div id='first'> first div </div>
<p> first paragraph </p>
<div> second div </div>
<p> second paragraph </p>
<div> another div </div>var firstDiv = getElementById("first")3) getElementsByTagname() method
This method is used to get to one or more elements based on their HTML tag names:
<div> first div </div>
<p> first paragraph </p>
<div> second div </div>
<p> second paragraph </p>
<div> another div </div>divs = document.getElementByTagname("div");4) appendChild() element
This element is used to get to one or more elements by their HTML tag names. It adds an element to the HTML element that calls this method the last child.
A newly created element or an existing element can be used as the child to be placed. It will be moved from its previous position to the place of the last child if it already exists.
<div>
<h1> Mangoes </h1>
</div>var p = document.createElement('p');
var h2 = document.querySelector('h2');
var div = document.querySelector('div');
h1.textContent = 'Mangoes are great...'
div.appendChild('p');5) setAttribute() method
This method is used to set or alter the value of an attribute on an element.
Assume we have a property called "id" with the value "favourite."
However, we would like to alter the value to "worst." Here's how you can accomplish that using code:
<div>
<h1 id='favourite'>Mangoes</h1>
</div>var h1 = document.querySelector('h1');
h1.setAttribute(div, 'worst');6) Node Method
A node is a term used to describe every element on an HTML page.
The node object has the following properties that can be used to access any element:
- node.childNodes – accesses the child nodes of a parent that has been chosen
- node.firstChild – obtains the first child of a particular parent
- node.lastChild – obtains the last child of a particular parent
- node.parentNode – accesses the parent of a child node that has been chosen
- node.nextSibling – accesses a specified element's next subsequent element (sibling)
- node.previousSibling – accesses a selected element's previous element (sibling)
<ul id-“list”>
<li><a href=” about.html”class=” list_one”> About </a></li>
<li><a href=” policy.html”> Policy </a></ li>
<li><a href=” map.html”> Map </a></ li>
<li><a href=” Refund.html”> Refund </a></li>
</ul>var list = document.getElementsById(“site - list”)
var firstItem = list.childNodes[0].childNodes[0];7) InnerHTML Property
This property is used to get at an element's text content.
addEventListener() property
An event listener is attached to your element using this property. It accepts a callback that will be executed when the event occurs.
<button>Click to submit</button>var btn = document.querySelector('button');
btn.addEventListener('click', foo);
function foo() {
alert('submitted!');
btn.innerHTML = '';
}replaceChild() property
This property swaps out one child element for another, either new or existing. It will be moved from its previous position to the place of the last child if it already exists.
<div>
<h1>Mangoes</h1>
</div>var h2 = document.createElement('h2');
var h1 = document.querySelector('h1');
var div = document.querySelector('div');
h2.textContent = 'Apple';
div.insertBefore(h1, h2);Why Do We Require the DOM?
In our case, the <html> tag represents the uppermost "home." We have our <head> and <body> tags, which are like rooms in our HTML "home." Finally, <title>, <h1>, <h2>, <p>, <img>, and <button> are the most specific elements.
Consider them similar to room-specific objects such as a bed and a lamp.
For the same reason that objects are structured, this is how elements in an HTML document are structured: A hierarchical structure facilitates computer programs in reading and analysing data. Your web browser is the program in the case of HTML, whereas scripting languages like JavaScript edit and modify the HTML code.
But there's a catch. HTML documents are not objects in and of themselves. Without any type of file-to-object translation, JavaScript will not be able to read them. This is when the DOM enters the picture.
An entire HTML document is represented by the DOM as a single object. The DOM is created when a web browser reads an HTML file and extracts all of its components, from the root element to the smallest tags, as an object that JavaScript can understand.
The DOM isn't a duplicate of the HTML file; rather, it's a distinct way for the web browser to organise HTML data.
The DOM is created in the same way that a browser builds a web page. You view the browser's visual representation of the underlying HTML when you access any page in your browser. You're looking at the same content, but it's structured into a page that your brain can understand.
The Document Object Model (DOM) is another method your browser represents HTML. The HTML is arranged in the DOM into an object that JavaScript can understand.
As a JavaScript-friendly object, the DOM would represent our simple HTML file as follows:
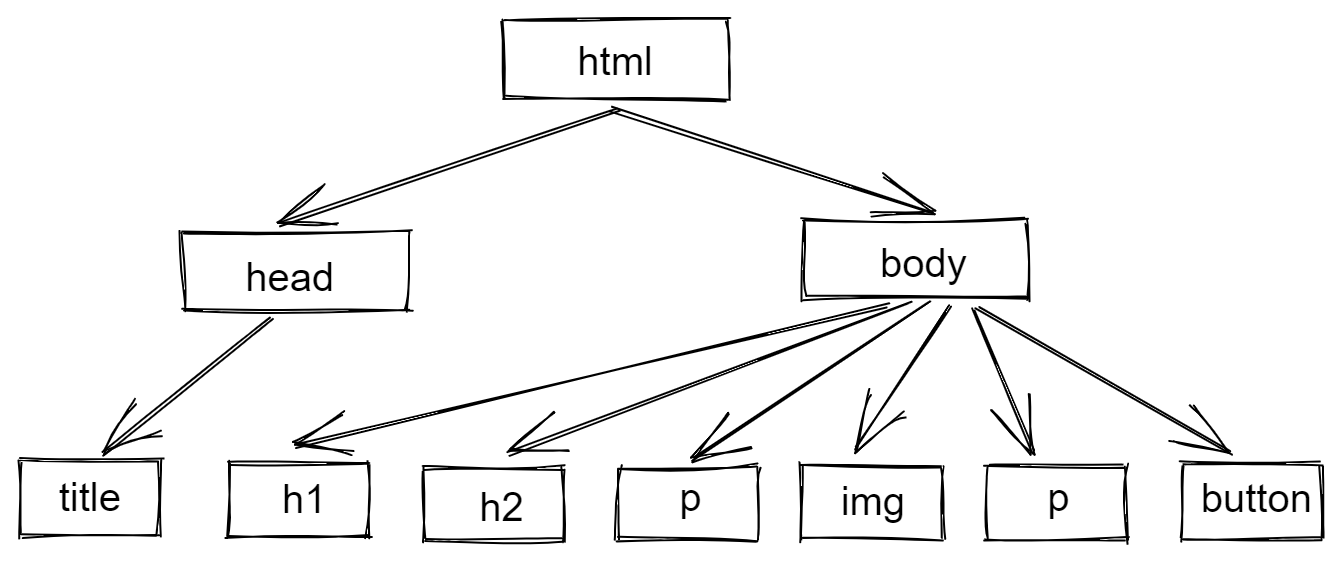
The DOM isn't just for JavaScript. The DOM can be used to edit web pages in any programming language (e.g., Python, C++). However, because JavaScript affects the majority of web pages, it's the sole programming language you'll need to comprehend the DOM.
Disadvantages of DOM
The greatest issue with DOM is that it uses a lot of memory. The whole HTML/XML is processed and a DOM tree is built and returned when utilising the DOM interface. The user can then navigate the tree to access data in the document nodes once the data has been parsed.
The DOM interface is simple and versatile to use, but it comes with the cost of parsing all of the HTML/XML before you can utilise it. As a result, when the document size is huge, the memory demand is significant, as well as the initial document loading time. DOM parsing may be an expense for small devices with limited onboard memory.
Another document parsing technique is SAX (Simple API for XML), which does not read the complete content. When the XML is parsed, events are triggered.
- tagStarted event is triggered when it meets a tag start (e.g.< tag>)
- tagEnded is triggered when the tag's end (< /tag>) is seen
As a result, it is more memory efficient for demanding applications.
The DOM standard was not widely accepted by many browsers in the past, however that incompatibility issue no longer exists.
Conclusion
The Document Object Model (DOM) is a representation of all the elements that make up a web page from the top down. It's the means by which your script interacts with your HTML. You can access information about the DOM and alter it using a variety of properties and methods.
Atatus API Monitoring and Observability
Atatus provide Powerful API Observability to help you debug and prevent API issues. It monitors the consumer experience and be notified when abnormalities or issues arise. You can deeply understand who is using your APIs, how they are used, and the payloads they are sending.
Atatus's user-centric API observability tracks how your actual customers experience your APIs and applications. Customers may easily get metrics on their quota usage, SLAs, and more.
It monitors the functionality, availability, and performance data of your internal, external, and third-party APIs to see how your actual users interact with the API in your application. It also validates rest APIs and keeps track of metrics like latency, response time, and other performance indicators to ensure your application runs smoothly.
#1 Solution for Logs, Traces & Metrics
![]() APM
APM
![]() Kubernetes
Kubernetes
![]() Logs
Logs
![]() Synthetics
Synthetics
![]() RUM
RUM
![]() Serverless
Serverless
![]() Security
Security
![]() More
More