MTTR Demystified: Mean Time to Recovery, Repair, or Respond
You might have heard of MTTR or MTBF. They are all important factors that make up incident management. Incident management refers to all the managerial processes behind bringing a site back to its uptime when it suddenly encounters any unplanned fault.
Incidents are common events that occur without our notice; they disrupt the usual functioning of the site and bring down its performance. All these slow failures might not seem big until they become big eventful failures of the entire application or website.
And that is precisely why managing them is important. We must keep our site up-to-date so that downtimes are reduced, and customers can access any information with the least wait time.
In this blog, we will look at different meanings of MTTRs, and how to keep them in check. We will look at some related abbreviations commonly used in this same sphere as well.
Table Of Contents:
- Why is Incident Management so Important?
- MTTR: Mean Time to Recovery
- MTTR: Mean Time to Respond
- MTTR: Mean Time to Repair
- MTTF: Mean Time to Failure
- MTBF: Mean Time Between Failure
- MTTA: Mean Time to Acknowledge
Why is Incident Management so Important?
The significance of incident management cannot be overstated in maintaining the reliability, availability, and performance of systems and services within an organization.
Here's why incident management is crucial:
- Minimize Downtime: Effective incident management helps minimize downtime by swiftly detecting and resolving issues, thus reducing the impact on business operations and customer experience.
- Mitigate Business Impact: Timely response to incidents mitigates potential financial, reputational, and operational impacts, ensuring business continuity and stability.
- Ensure Service Reliability: By identifying and addressing underlying issues causing incidents, incident management enhances infrastructure's overall stability and performance.
- Enhance Customer Satisfaction: Prompt resolution of incidents improves customer satisfaction by demonstrating responsiveness, reliability, and commitment to service excellence.
Getting started with incident management involves several key steps:
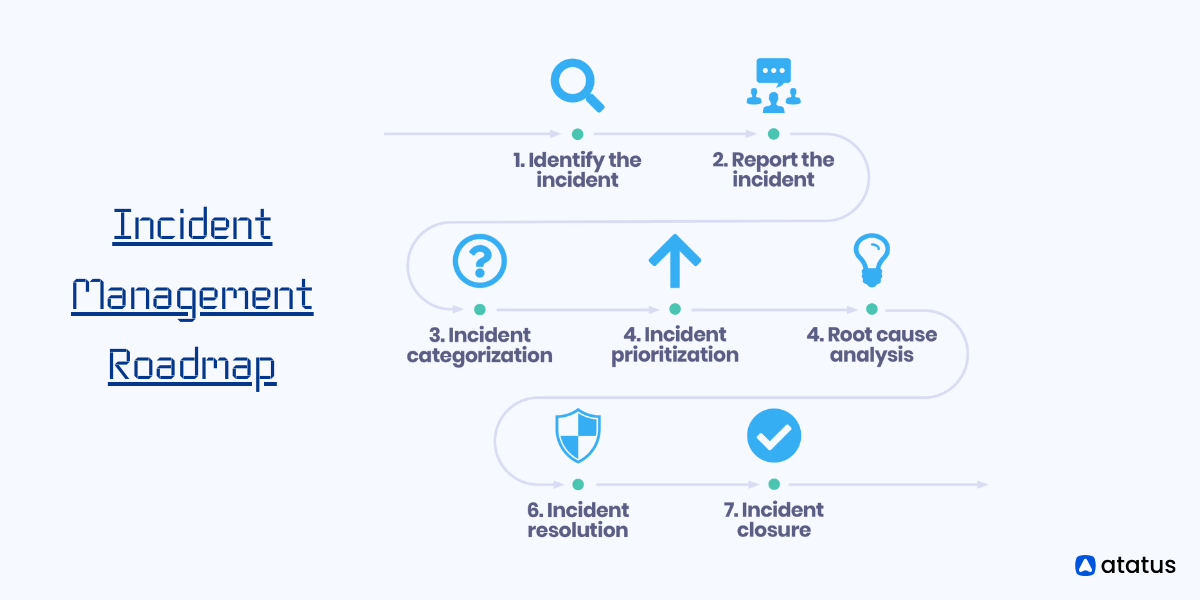
- Define Procedures: Establish clear incident management procedures outlining roles, responsibilities, and escalation paths, along with criteria for identifying, prioritizing, and categorizing incidents.
- Implement Detection and Alerting: Set up systems and tools for real-time incident detection and alerting, including monitoring solutions to track key performance indicators and system health parameters.
- Create Response Team: Form a dedicated incident response team with the necessary skills and expertise to provide training and resources to ensure effective incident response.
- Develop Communication Channels: Establish communication channels and protocols for incident reporting, stakeholder notification, and response coordination, ensuring clear lines of communication between responders and stakeholders.
- Practice Response: Conduct regular drills and simulations to practice incident response procedures, identify areas for improvement, and refine processes based on lessons learned from past incidents.
- Continuous Improvement: Monitor and evaluate incident management processes regularly, collecting feedback from stakeholders and responders to identify opportunities for improvement and enhance incident management capabilities over time.
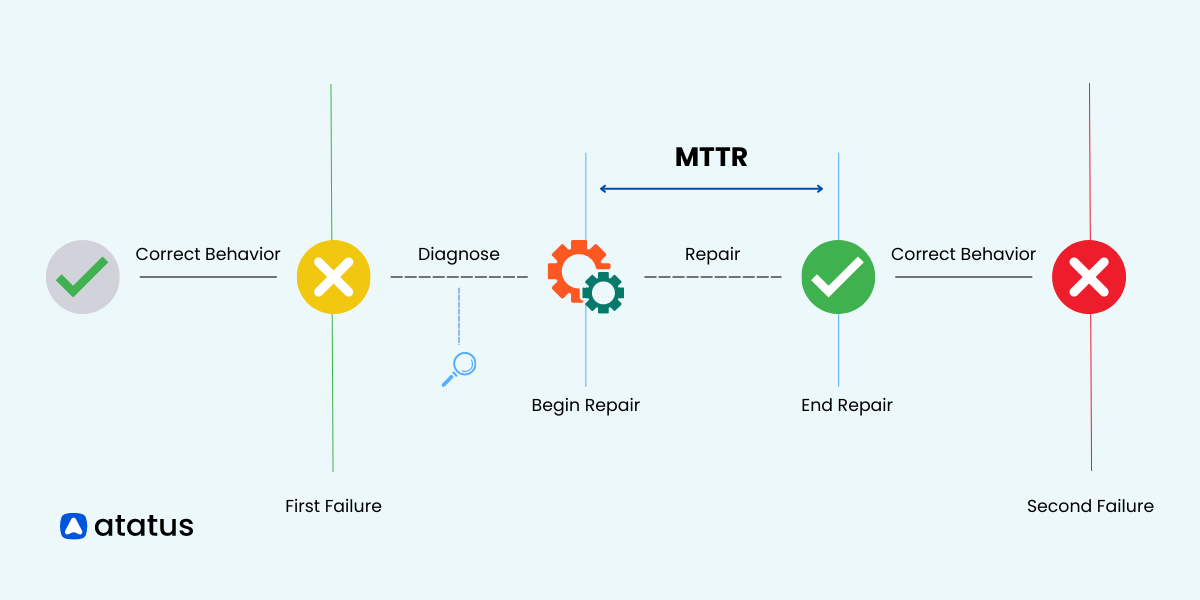
MTTR: Mean Time to Recovery
Mean Time to Recovery (one of the MTTR definition) is the measure of the time a site is taking to go from “down” to “available” from a user’s perspective. The system went through the “down” phase due to a product or system failure.
How to calculate MTTR?
“Mean Time to” measures averages of all the downtimes. It is the cumulative time required for a system to go from Downtime to Uptime. For example, if a system went down for a cumulative time of 60 seconds in 3 separate incidents, then the mean time to recovery would be 20 seconds for each incident.
The formula goes like this:

MTTR sounds impressive and easy, too, as a measure of the downtime recovery period. But there are some inherent lacuna in this metric. For example, it doesn’t tell where the incident occurred or which incident took the longest time to recover. That way, it is difficult for sysadmins to pinpoint and work on the fault.
It also falls short of segregating time into each factor - like, was it the alert settings that took a lot of time to be set, or was it the incident itself that was hard to repair?
This is where other such metrics come into play. Let's take a look at other MTTRs, MTBF and MTTA.
MTTR: Mean Time to Respond
Another one of the MTTRs is the Mean Time to Respond.
MTTR represents the average time a team or individual takes to respond to an incident after it has been detected or reported.
It includes the time to acknowledge the incident, assess the situation, and initiate the necessary steps to resolve the issue.
Mathematically, MTTR is expressed as:

How can you improve MTTR?
- Implementing automated incident detection and alerting systems reduces the time it takes to detect and notify the appropriate personnel about incidents.
- Establish clear escalation and communication procedures to ensure incidents are promptly assigned to the appropriate teams or individuals for resolution.
- Providing training and resources to incident response teams enables them to respond effectively to incidents and minimize response times.
MTTR: Mean Time to Repair
Mean Time Repair starts right when the repair works on incidents starts. i.e., this includes the time to fix the incident and the time it takes to return to its normal working state.

For example, if your system went down for about 160 minutes over five days in 16 separate incidents, the average repair time is 10 minutes per incident.
This metric will be of more use if you want to learn about your team's efficiency. The time they take to repair a particular fault incident. But the problem is if a peculiar incident occurs for the first time, you won't know how to repair it. Then the team would run so many tests just to analyze what the fault is all about, and then, all of this trial time gets included in the meantime to repair
MTTF: Mean Time to Failure
MTTF measures the average operating time of a system or component before it fails. It represents the system's reliability under normal operating conditions and estimates the expected time until failure occurs.
MTTF is calculated by dividing the total operating time of the system by the total number of failures that occur within that period.
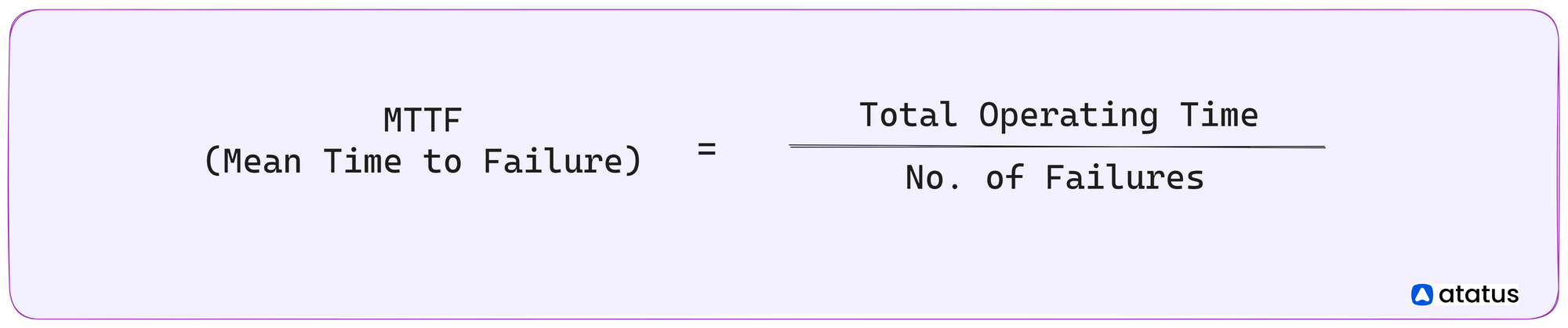
MTTF is used in various industries, including manufacturing, electronics, automotive, and aerospace, to assess the reliability of products and systems. It helps organizations make informed decisions about maintenance schedules, spare parts inventory, and warranty policies based on the expected reliability of their assets.
It's important to note that MTTF assumes a constant failure rate over time and may not capture variations in failure rates that occur due to factors such as wear and tear, environmental conditions, or changes in operating conditions. Additionally, MTTF is typically used for non-repairable systems or components, where failures are considered permanent and require replacement rather than repair.
MTBF: Mean Time Between Failures
Mean Time Between Failures (MTBF) measures the average time elapsed between consecutive system or component failures.
MTBF is calculated by dividing the total operating time of a system by the number of failures that occur within that time. The formula for calculating MTBF is:
MTBF=Total Operating Time / Number of Failures
MTBF is typically measured in hours, days, or other units of time, depending on the context of the system being analyzed. A higher MTBF value indicates a more reliable system with longer intervals between failures, while a lower MTBF value suggests shorter intervals between failures and potential reliability issues that may need to be addressed.
MTBF is often used with other reliability metrics, such as Mean Time to Repair (MTTR) and Availability, to assess systems' overall reliability, maintainability, and availability.
MTTA: Mean Time to Acknowledge
MTTA measures the time interval from when an incident is detected or reported to when the responsible team or individual acknowledges it. It reflects the responsiveness and efficiency of an organization's incident response process.
MTTA is calculated by summing up the time taken to acknowledge incidents across all occurrences and dividing it by the total number of incidents.
Mathematically, MTTA is expressed as:

A lower MTTA indicates that incidents are promptly acknowledged and addressed, minimizing downtime and reducing the impact on operations.
Conclusion
Understanding and monitoring different metrics such as MTTR, MTBF, and MTTA is crucial for businesses and organizations to improve their efficiency and performance.
By identifying areas for improvement and implementing effective strategies, companies can decrease their MTTR and MTTA, increase their MTBF, and ultimately minimize downtime and maximize productivity.
It is important to regularly analyze and track these metrics to continuously improve processes and achieve success in today's fast-paced and competitive market.
Effective incident management is essential for minimizing downtime, mitigating business impact, ensuring service reliability, and enhancing customer satisfaction. It's critical to maintaining operational excellence and resilience in today's dynamic business environment.
Infrastructure Monitoring with Atatus
Track the availability of the servers, hosts, virtual machines and containers with the help of Atatus Infrastructure Monitoring. It allows you to monitor, quickly pinpoint and fix the issues of your entire infrastructure.
In order to ensure that your infrastructure is running smoothly and efficiently, it is important to monitor it regularly. By doing so, you can identify and resolve issues before they cause downtime or impact your business.
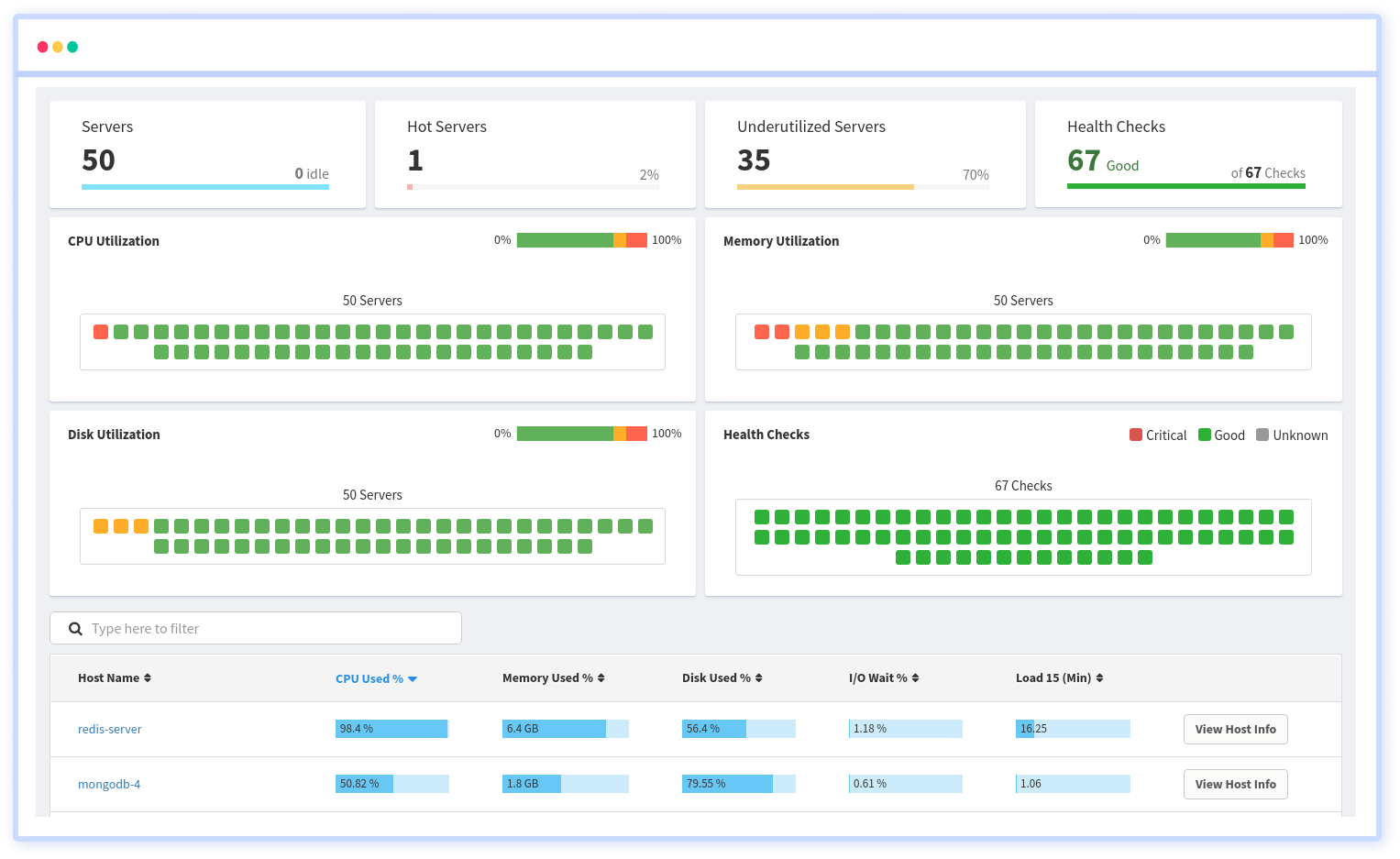
It is possible to determine the host, container, or other backend component that failed or experienced latency during an incident by using an infrastructure monitoring tool. In the event of an outage, engineers can identify which hosts or containers caused the problem. As a result, support tickets can be resolved more quickly and problems can be addressed more efficiently.
Start your free trial with Atatus. No credit card required.
#1 Solution for Logs, Traces & Metrics
![]() APM
APM
![]() Kubernetes
Kubernetes
![]() Logs
Logs
![]() Synthetics
Synthetics
![]() RUM
RUM
![]() Serverless
Serverless
![]() Security
Security
![]() More
More