REST vs GraphQL: Everything You Need to Know
The RESTful web API has long been the industry standard, but in recent years, APIs based on the GraphQL Schema Definition Language has grown in popularity. This post will go over the advantages and disadvantages of each, as well as when GraphQL makes sense for your application.
We will cover the following:
- History
- What is REST?
- Issues with REST
- What is GraphQL?
- Issues with GraphQL
- Difference between REST and GraphQL
History
At the time, the Web's architecture was only loosely defined, and the industry was under pressure to agree on a standard for Web interface protocols. For example, numerous experimental additions to the communication protocol (HTTP) to accommodate proxies had been added, and other extensions were being proposed, but a formal Web architecture was needed to assess the impact of these changes.
Working groups from the W3C and the IETF collaborated to create formal specifications of the Web's three core standards: URI, HTTP, and HTML.
Fielding, in his 2000 Ph.D. dissertation "Architectural Styles and the Design of Network-based Software Architectures" at UC Irvine, he identified the needs that apply to constructing a global network-based application, such as the need for a low entry barrier to enable global adoption, to design the REST architectural style. He also looked at a variety of current network-based application architectural styles, determining which aspects are shared among them, such as caching and client-server features, and which are unique to REST, such as the concept of resources.
Fielding was attempting to categorize the present implementation's architecture and determine which components should be regarded as fundamental to the Web's behavioural and performance requirements.
Architectural styles are, by definition, independent of any specific implementation, and while REST was developed as part of the creation of Web standards, the Web does not follow every constraint in the REST architectural style. Mismatches can develop as a result of ignorance or neglect, but the REST architectural style allows them to be discovered before they become conventional.
What is REST?
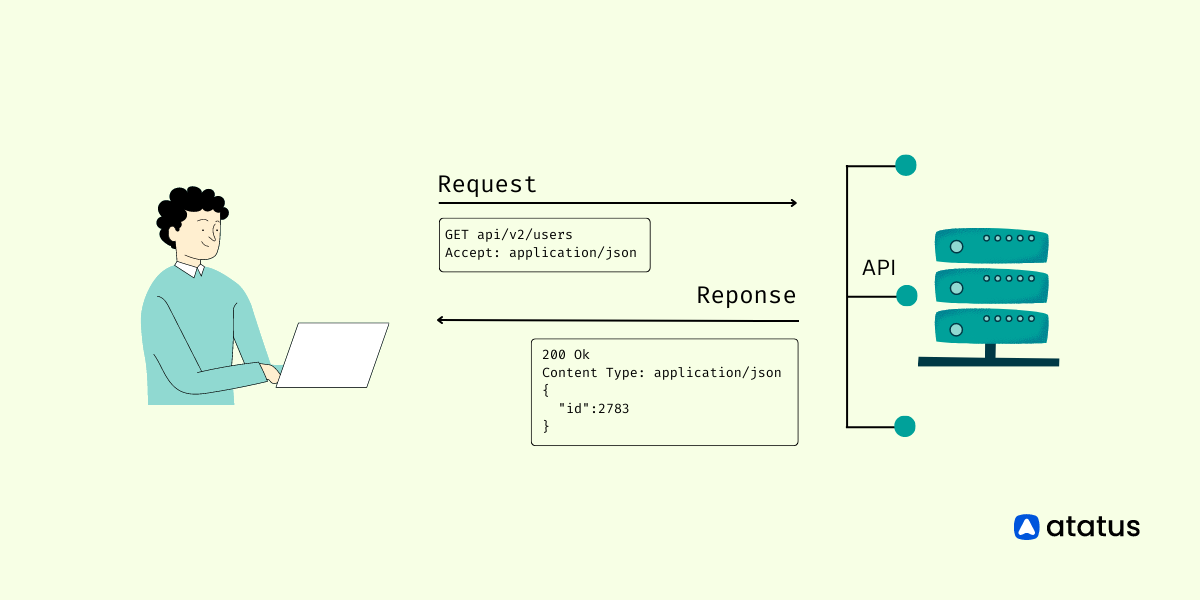
REST (representational state transfer) is a software architectural style that was created to help with the design and development of the Web's architecture. REST establishes a set of guidelines for how an Internet-scale distributed hypermedia system, such as the Web, should be designed.
The REST architectural style emphasizes scalability of component interactions, uniform interfaces, component deployment independence, and the establishment of a layered architecture to enable caching components to reduce user-perceived latency, enforce security, and encapsulate legacy systems.
Key Benefits of REST:
- Platforms and programming languages have no impact on how the REST API is implemented. Any language, including C#, PHP, Java, and Python, can be used with the REST API. The sole constant in the Rest API is the language used for request and response interchange, which is usually XML or JSON.
- Because of the isolation between the client and the server, as well as the stateless protocol, it's easy to scale applications.
- Data can be moved from one server to another, and DBMS levels can be changed at any time.
Issues with REST
As more APIs are deployed in production and grown to extreme levels, issues with RESTful architecture have arisen. You could even say that GraphQL is a hybrid of SOAP and REST, with elements of both.
Server Driven Selection
The server creates a representation of a resource to be returned to a client via RESTful APIs.
What if the client requests a specific result, such as the names of friends or friends of a user whose job title is an manager?
You might have something like this with REST:
GET api.sample.com/users/988?include=friend.friend.name&friend.friend.occupation=managerGraphQL allows you to express this query in a more concise manner:
{
user(id: 988) {
friends {
friends(job: "manager") {
name
}
}
}
}Fetching Multiple Resources
Many of us have encountered an API that requires us to first GET /user and then GET /user/:id/friend/:friend_id endpoints to fetch each friend individually. This can result in N+1 queries and is a well-known performance issue in API and database queries. Before the final representation for display can be generated, RESTful API calls are chained on the client. By allowing the server to combine the data for the client in a single query, GraphQL can help to reduce this.
What is GraphQL?
GraphQL is a runtime for satisfying queries with existing data, as well as an open-source data query and manipulation language for APIs. It describes a methodology for creating web APIs and compares and contrasts REST and other web service architectures. It allows clients to specify the structure of the data they seek, and the server returns the same structure, avoiding the server from returning overly huge amounts of data. However, this has implications for how efficient web caching of query results can be.
The query language's flexibility and richness add complexity, which may not be worth it for simple APIs. GraphQL, despite its name, does not offer the same breadth of graph operations as a full-fledged graph database like Neo4j, or even dialects of SQL that support transitive closure.
Key Benefits of GraphQL:
- Allowing the client to request only the data they need solves the problem of over-fetching and under-fetching data in REST APIs.
- Allows the client to acquire relevant data from various resources in a single request, saving time and bandwidth.
- To define and expose APIs, GraphQL employs a powerful type system. The GraphQL Schema Definition Language (SDL) is used to specify all of the kinds that are available in an API. This tightly typed schema is less prone to errors and adds an extra degree of validation.
Issues with GraphQL
Catching
Caching is a feature of the HTTP protocol that RESTful APIs can take advantage of. The semantics of GET vs. POST in terms of caching is well established, making it easy for browser caches, intermediary proxies, and server frameworks to follow. The guidelines below can be followed:
- It is possible to cache GET requests
- GET requests can be saved to the browser's history
- GET requests can be saved as favourites
- Idempotent GET requests
Instead of using the HTTP specification for caching, GraphQL employs a single endpoint. As a result, it is the developer's responsibility to ensure that caching is properly implemented for non-mutable requests that can be cached. For the cache, the right key must be used, which may include checking the body contents.
While you can utilize tools that understand GraphQL semantics, such as Relay or Salesforce dataloader, this still doesn't handle things like browser and mobile caching.
Diminishes Shared Nothing Architecture
RESTful APIs have the advantage of complementing shared-nothing architecture effectively. For example, an application has two endpoints. Those two endpoints appear to be two separate REST resources. Internally, however, they refer to two distinct microservices running on separate compute clusters. The alerting service is implemented in NodeJS, whereas the search service is written in Scala.
Routing HTTP requests via host or URL has a considerably lower level of complexity than analysing a GraphQL query and executing numerous joins.
Exposed for Arbitrary Requests
While one of the key advantages of GraphQL is that it allows clients to query for only the data they require, this can be troublesome, particularly for open APIs where an organization has no control over third-party client query behaviour. To guarantee that GraphQL queries don't result in expensive join queries that slow down server performance or potentially DDoS the server, extreme caution must be exercised. The data model and indexing used in RESTful APIs can be limited.
Rigidness of Queries
Custom query DSLs and side effect actions on top of an API are no longer possible with GraphQL. The Elasticsearch API, for example, is RESTful but also offers a sophisticated Elasticsearch DSL for doing advanced aggregations and metric calculations. Such aggregating requests may be more difficult to model in GraphQL.
Non-Existent Monitoring
RESTful APIs, like websites, benefit from following the HTTP specification when it comes to resources. Many tools may now probe a URL, which will return 5xx if something isn't right. Since most ping tools don't support HTTP and request bodies, you may not be able to use such tools with GraphQL APIs unless you allow inserting the query as a URL parameter.
There are very few SaaS or open-source tools that provide API analytics or deeper analysis of your API calls, outside than ping services. In a GraphQL API, client errors are displayed as a 200 OK. Existing tools that assume 400 failures will not operate, causing you to overlook API errors. However, providing additional flexibility to the client takes even more tools to detect and explain API issues.
Difference between REST and GraphQL
Facebook released GraphQL in 2015, and its main features include support for hierarchical data architecture and client-specific queries. The hierarchical data model can reduce the number of endpoints API customers must access, allowing them to request only the information they require.
Over-fetching or under-fetching of data has been a common problem with REST APIs; sometimes the client only wants to see a small portion of the available data, but the API endpoint provides too much information in the JSON file, and other times the client needs to access multiple endpoints to get all of the desired data.
Using GraphQL does not always mean that API clients will have to conduct fewer queries, however, it has been demonstrated that in some circumstances, it can reduce the size of returned JSON documents by over 90% when compared to REST-based APIs.
An experiment conducted by the Federal University of Minas Gerais discovered that implementing GraphQL API queries was easier to learn than implementing REST API queries, especially when the query had numerous parameters. However, constructing a GraphQL server needs the use of API layer components such as a GraphQL execution unit, schema, and resolvers, which adds complexity and may make GraphQL overkill for simple applications.
Also, using HTTP caching with REST APIs is simple, but because the goal with GraphQL is to provide a single endpoint for API requests, caching needs extra effort from the developer.
GraphQL appears to be significantly distinct from REST from the above section. So, what are the differences?
#1 Endpoints
We normally look at one endpoint for each request when using a REST API. This applies to all queries, whether they are Select, Insert, Update, or Delete. Each endpoint corresponds to a separate database query. In the case of GraphQL, this is not the case. GraphQL only has one endpoint. A single endpoint is used for all calls.
This isn't to claim that GraphQL doesn't support Select, Insert, Update, and Delete operations. All of these forms of operations are still possible. All of this is done, however, through a single endpoint. Then there are two different "Types": query and mutation. These provide you the ability to accomplish precisely what they state. You can either query or alter the data, which could be an Insert, Update, or Delete.
#2 Structure
We know that data in a REST API is arranged in JSON format. Instead, we employ a graph structure with GraphQL. These nodes have a more specified schema than an object. Since it builds its own structure, this graph format is more unique to GraphQL. Because there isn't a de-facto standard like there is with REST, this provides for more freedom.
The server determines the size of resources in REST. In GraphQL, on the other hand, a server allows clients to make data requests at more specified times, determining what resources are available and when they are available.
Relationships are assigned based on the schema your graph is set up in because GraphQL only has one endpoint. Because it may only use a single endpoint, a relationship between tables is formed instead of using different endpoints.
#3 Solving Querying Issue
As previously said, GraphQL is designed to be adaptable. As a result, it can return a more personalized subset of data that better reflects the information needed. This means that you must first create a database and then retrieve it using a REST API. If we need information from multiple tables, we'll need different requests. In addition, if we needed a specific column from a table, we'd have to make a call to get it. We see that we have to put that data into an object as we develop, therefore there may be unneeded data preserved in that object.
Fetching data with GraphQL is more flexible and customizable. It could be able to reduce the number of calls required, or even keep them to just one. If only a few columns are required, they can be aggregated without the requirement to save others in an object. This might theoretically speed up your API calls.
#4 Scalability
Although it may not be a significant aspect, flexibility allows for much easier scalability. The ability to make changes to schemas or queries without affecting existing schemas/queries makes data expansion considerably easier to accomplish. This means that alterations have little impact on the existing architecture, which is reassuring when making significant changes.
Considering that resourcing is better handled by the server, the fact that GraphQL often speeds up queries is also highly useful. The ability to be so adaptable allows for continued development. It's also quicker to write because there's less code to alter. It is readable even by non-technical users due to the graph structure, making it easy for others to review and understand your code.
Summary
GraphQL is still evolving, therefore it does not yet have all of its faults ironed out. However, it currently provides greater flexibility than REST, as well as addressing some of REST's flaws, such as under-fetching and over-fetching. GraphQL also employs a robust “Type” system in its format, as well as a graph rather than JSON.
Each request in REST is sent to a distinct endpoint. GraphQL, on the other hand, only has one endpoint. There are also variances in architecture, such as how the server would allocate resources.
Finally, I believe that deciding whether to use GraphQL or REST is a matter of personal preference and ambition.
Monitor API Failures with Atatus
Monitoring API failures in production is very hard. You'll need tools like Atatus to figure out which APIs are failing, how often they're failing, and why they're failing.
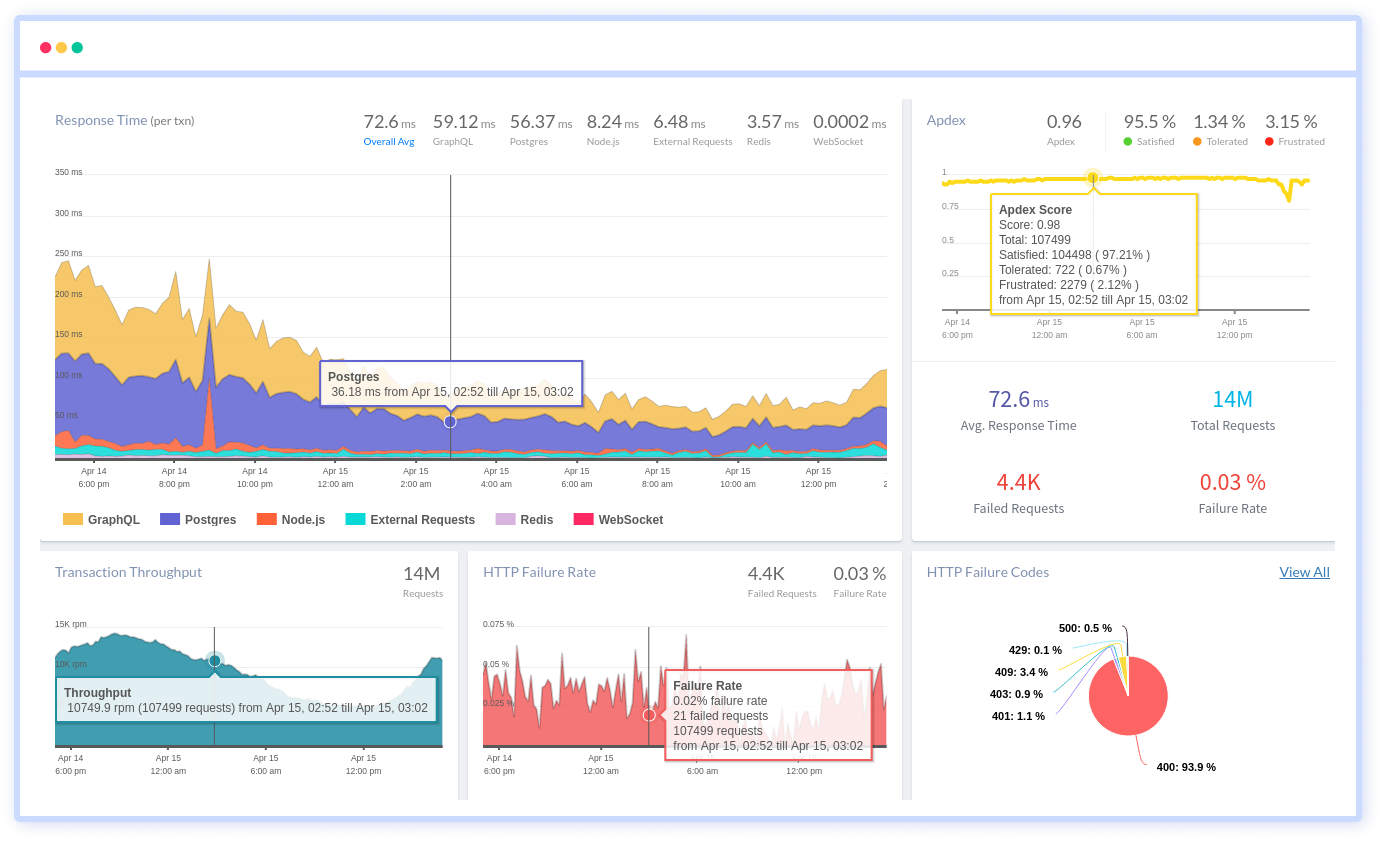
You can see the most common HTTP failures and get detailed information about each request, as well as custom data, to figure out what's causing the failures. You may also view how API failures are broken down by HTTP Status Codes and which end-users have the most impact.
#1 Solution for Logs, Traces & Metrics
![]() APM
APM
![]() Kubernetes
Kubernetes
![]() Logs
Logs
![]() Synthetics
Synthetics
![]() RUM
RUM
![]() Serverless
Serverless
![]() Security
Security
![]() More
More