Virtual machines were commonly used by developers prior to the introduction of Docker. Virtual machines, on the other hand, have lost favour as they have been shown to be inefficient. Docker was later introduced, and it replaced virtual machines by allowing developers to address problems quickly and efficiently.
We will cover the following:
- What is Docker Swarm?
- Key Concepts of Swarm Mode
- How does Docker Swarm Work?
- Features of Docker Swarm
- Kubernetes vs. Docker Swarm
What is Docker Swarm?
A Docker Swarm is a collection of physical or virtual machines that have been configured to join together in a cluster and run the Docker application. You can still run the Docker commands you're used to once a set of machines has been clustered together, but they'll be handled by the machines in your cluster. A swarm manager oversees the cluster's operations, and machines that have joined the cluster are referred to as nodes.
Docker Swarm is a docker container clustering and scheduling tool. IT admins and developers may use swarm to create and manage a cluster of Docker nodes as a single virtual system. Docker Engine, the layer between the OS and container images, also has a native swarm mode. Swarm mode adds docker swarm's orchestration features into Docker Engine 1.12 and newer releases.
In container technology, clustering is an important part because it allows a cooperative group of systems to provide redundancy by allowing docker swarm failover if one or more nodes fail. Administrators and developers can easily add or remove container iterations as compute demands vary with a docker swarm cluster. The user can deploy manager and worker nodes at runtime in the Docker engine's swarm mode.
To communicate with other tools, such as docker-machine, Docker Swarm employs the standard docker application programming interface (API).
Key Concepts of Swarm Mode
Let's continue our exploration of what Docker swarm is and the key concepts of swarm mode.
Service and Tasks
Services are used to start Docker containers. There are two types of service deployments: global and replicated.
- Containers that want to run on a Swarm node must be monitored by global services.
- Replicated services describe the number of identical tasks that a developer needs on the host machine.
Developers can use services to scale their applications. A developer should implement at least one node before releasing a service in Swarm. Any node in the same cluster can use and access services. A service describes a task, whereas a task actually does the work. Docker aids a developer in the creation of services that can initiate tasks. However, once a task has been allocated to a node, it cannot be assigned to another node.
Node
The Docker engine is represented by a Swarm node. On a single server, it is possible to run many nodes. Nodes are dispersed over multiple devices in production installations.
How does Docker Swarm Work?
Containers are launched via services in Swarm. A service is a collection of containers with the same image that allows applications to scale. In Docker Swarm, you must have at least one node installed before you can deploy a service.
In Docker Swarm, there are two categories of nodes such as:
- Manager Node – Maintains cluster management responsibilities
- Worker Node – The manager node sends tasks to this node, which it receives and executes
Consider the case where a manager node issues directives to various worker nodes. The worker nodes receive tasks from the manager node and the manager node in a cluster is aware of the status of the worker nodes. Every worker node has an agent who reports to the manager on the status of the node's tasks. In this approach, the cluster's desired state may be maintained by the manager node.
API over HTTP is used by the worker nodes to communicate with the manager node. Services can be deployed and accessed by any node in a Docker Swarm cluster. You must indicate the container image you want to use when creating a service. You can make commands and services global or replicated: a global service will execute on all Swarm nodes, whereas a replicated service will have the manager node distribute duties to worker nodes.
Are Task and Service being the same thing?

No!!!
A service is a description of a task or a state, whereas the task itself is the work to be completed. A user can use Docker to develop services that can do tasks. A task can't be assigned to another node once it's been assigned to another. Within a Docker Swarm environment, many manager nodes are feasible, but only one primary manager node will be elected by other manager nodes.
The command-line interface is used to create a service. We may orchestrate by generating tasks for each service using the API that we connect in our Swarm environment. The task allocation feature will allow us to assign work to tasks based on their IP address. The dispatcher and scheduler are in charge of assigning and instructing worker nodes on how to complete a task.
The Worker node establishes a connection with the Manager node and monitors for new tasks. The final step is to carry out the duties that the manager node has given to the worker node.
Features of Docker Swarm
The following are some of Docker Swarm's most important features:
- High Scalability
The Swarm environment is transformed into a highly scalable infrastructure through load balancing. - High-level Security
Any communication between the Swarm's manager and client nodes is encrypted. - Automatic Load Balancing
Within your environment, there is autoload balancing, which you can script into how you write out and build the Swarm environment. - Decentralized Access
Swarm makes accessing and managing the environment very simple for teams. - Reverse a Task
Swarm allows you to revert surroundings to a previous, safe state.
Kubernetes vs. Docker Swarm
Now that we know what Docker Swarm is, let's look at the differences between Kubernetes and Docker Swarm.
Simple Installation
In Kubernetes, however, it isn't easy to set up a cluster. Getting started with Kubernetes might take a lot of time and effort in terms of planning. Different configurations exist for many operating systems, making the process complicated and time-consuming.
Swarm is easier to set up than Kubernetes. To establish clusters in Docker Swarm, you only need to know a few commands. Furthermore, the configuration is the same across operating systems, making it easy for developers to get started regardless of whatever OS they're using.
Scalability
Kubernetes has auto-scaling capabilities and can grow up to thousands of nodes, each with many containers. Despite the fact that Kubernetes is a tried-and-true all-in-one framework with a vast set of APIs and consistent cluster states, its complexity slows down the deployment of new containers.
Auto-scaling is not available out of the box in Docker Swarm. DevOps and IT teams can sometimes identify remedies for this issue. When it came to establishing a new container, the prior version of Docker Swarm was five times faster than Kubernetes in 2016. Additionally, when listing all operating containers in production, Swarm might be up to seven times faster at the time.
However, the speed difference between Docker Swarm and Kubernetes is now insignificant.
Fault Tolerance
For management failover, both Kubernetes and Docker Swarm use raft consensus. Both technologies require 3-5 manager nodes and let health checks construct containers automatically if applications or nodes fail. Overall, the fault tolerance difference between Kubernetes and Docker Swarm is negligible.
Networking
- TLS authentication is required for security in Kubernetes, which requires manual configuration
- TLS authentication and container networking are configured automatically in Docker Swarm
Service Discovery
Service discovery is handled differently in Docker Swarm and Kubernetes. Containers must be explicitly defined as services in Kubernetes. Swarm containers can connect with each other using virtual private IP addresses and service names, regardless of the hosts on which they are operating.
Rolling Updates and Rollbacks
Updates on a regular basis is used to update the pods in a sequential manner. In the event of a failure, Kubernetes provides automated rollbacks. Updates are handled by the scheduler in Swarm. Additionally, automated rollbacks are not accessible out of the box. However, by setting “update-failure-action=rollback” in your services, you may have complete auto-rollback support in every update, including health check rollbacks.
Customization
The learning curve is higher in Kubernetes; Docker CLI and Docker Compose aren't available for defining containers, and YAML definitions must be rebuilt. But Kubernetes provides additional customizing options. While the Swarm API makes it simple to use Docker for similar tasks, it is difficult to conduct actions that aren't covered by the API.
Load-balancing
By deploying a container on many nodes, both container orchestration technologies provide high availability and redundancy. When a host goes down, the services can self-heal as a result.
Monitoring
There is built-in logging and monitoring. However, you can maintain track of logs and other vital performance metrics using third-party monitoring solutions.
Docker Service Logs, Docker Events, and Docker Top are some of the core out-of-the-box capabilities provided by Swarm. However, if you want to take your monitoring to the next level, you'll need to use other third-party logging and monitoring solutions like Atatus.
Summary
Docker is a tool that automates the deployment of an application as a lightweight container, allowing it to run in a variety of environments. The docker engine and docker swarms are being used by an increasing number of developers to design, update, and execute applications more efficiently. Container-based approaches like docker swarm are being adopted by even software behemoths like Google. Docker Swarm enables enterprises to create small, self-contained code components that demand little resources.
Atatus Log Monitoring and Management
Atatus is delivered as a fully managed cloud service with minimal setup at any scale that requires no maintenance. It monitors logs from all of your systems and applications into a centralized and easy-to-navigate user interface, allowing you to troubleshoot faster.
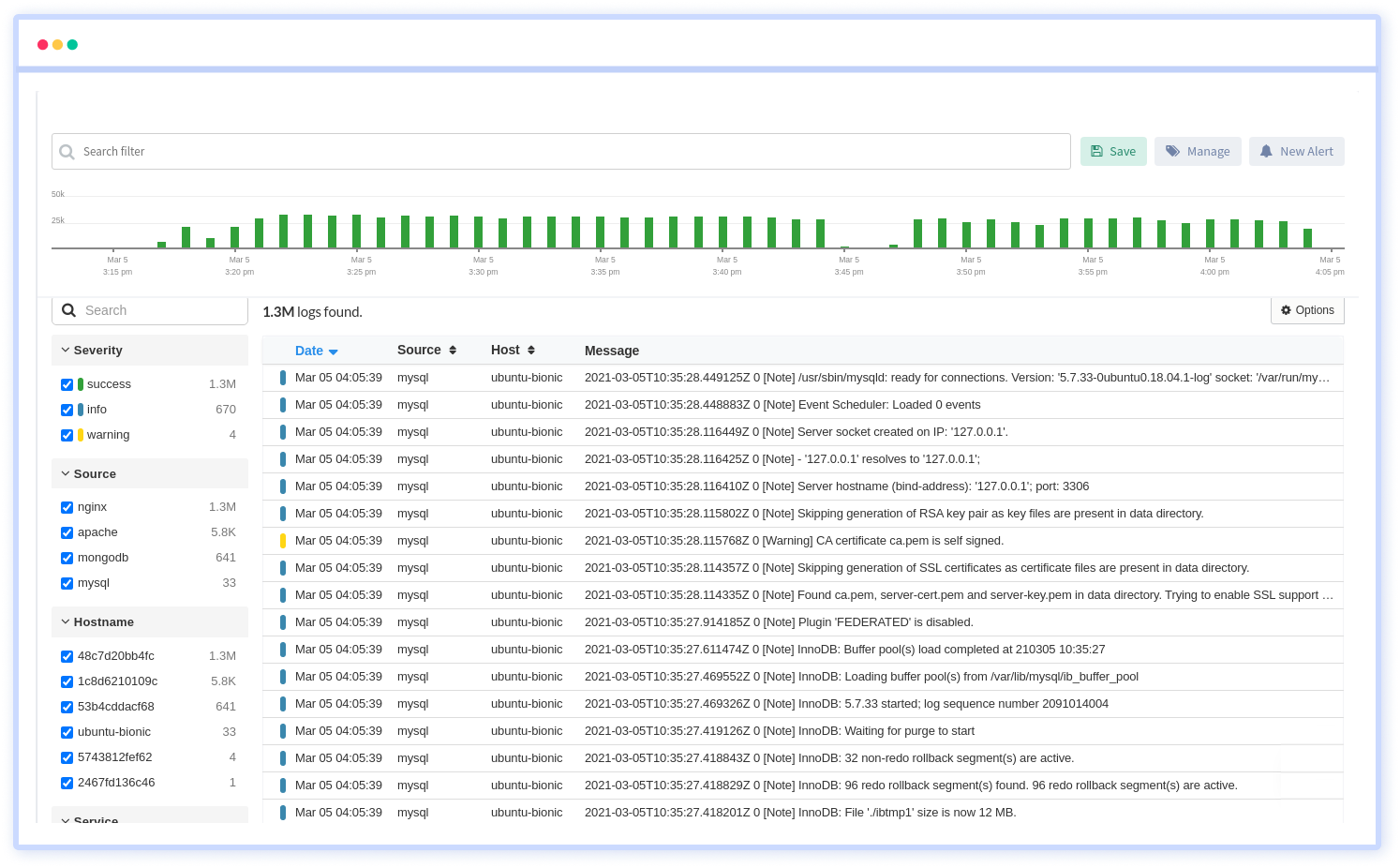
We give a cost-effective, scalable method to centralized logging, so you can obtain total insight across your complex architecture. To cut through the noise and focus on the key events that matter, you can search the logs by hostname, service, source, messages, and more. When you can correlate log events with APM slow traces and errors, troubleshooting becomes easy.