Tracing is a basic software engineering practice that programmers use in combination with other logging methods to get data about an application's behaviour. When utilized to troubleshoot applications built on a distributed software architecture, however, traditional tracing has issues.
We will go over the following:
- What is Distributed Tracing?
- How does Distributed Tracing Work?
- Benefits of Distributed Tracing
- Challenges in Distributed Tracing
- Why Distributed Tracing is Important?
What is Distributed Tracing?
Distributed tracing, also known as Distributed Request Tracing, is a technique for monitoring microservices-based applications from frontend devices to backend services and databases. Its purpose is to help developers identify performance issues by profiling and monitoring modern applications built using microservices and/or cloud-native architecture. Developers can use distributed tracing to follow a single request as it moves through an entire system that is spread over multiple applications, services, and databases.
You can collect data on each request using a distributed tracing tool, which will enable you present, analyse, and visualize the request in detail. You can observe each step that a request takes and how long each step takes using these graphic representations. Developers can look at this data to discover where the system is encountering bottlenecks and latencies and figure out what's causing them. A request may, for example, move back and forth between numerous microservices before being fulfilled. There's no way to determine where the issues are until you trace the full journey.
Distributed tracing tracks each request end to end and assigns a unique trace ID to each request and associated trace data to understand exactly how each service is functioning in terms of processing a request. Adding instrumentation to the application code or introducing auto-instrumentation in the application environment are two common ways to accomplish this.
How does Distributed Tracing Work?
Applications might be monolithic or microservices-based. A monolithic application is a single functional unit that is developed. An application is broken down into modular services in a microservice architecture, each of which handles a fundamental function of the application and is often overseen by a dedicated team.
Many current applications use microservices to make it easier to test and deliver speedy updates while avoiding a single point of failure. Microservices, on the other hand, can be difficult to diagnose because they frequently run on a sophisticated, distributed backend, and requests may consist of several service calls. Developers may monitor the whole route of a request—from frontend to backend—and spot any performance issues or bottlenecks that happened along the way using end-to-end distributed tracing.
When a request is launched, such as when a user submits a form on a website, end-to-end distributed tracing systems begin gathering data. This causes the tracing platform to generate a unique trace ID and an initial span, known as the parent span. A trace displays the request's complete execution path, with each span representing a single unit of work along the way, such as an API call or database query. A top-level child span is produced whenever a request enters a service.
The top-level child span may operate as a parent to numerous child spans nested beneath it if the request made multiple instructions or searches within the same service. Each child span is encoded with the original trace ID and a unique span ID, duration and error data, and appropriate metadata, such as customer ID or location, by the distributed tracing platform.
Finally, all of the spans are represented in a flame graph, with the parent span at the top and the child spans nested below in order of occurrence. Engineers can observe how long the request is spent in each service or database because each span is timed, and they may focus their debugging efforts accordingly. The flame graph can also be used by developers to discover which calls have errors.
Benefits of Distributed Tracing
The ability of distributed tracing to offer coherence to distributed systems is its major benefit, which leads to several other benefits. These are some of them:
- Reduce MTTD and MTTR
Whether a customer detects a slow or broken feature in an application, the support team can look at distributed traces to see if it's a backend issue. Engineers can then swiftly troubleshoot the issue by analysing the traces created by the impacted service. You may investigate frontend performance issues from the same tool if you utilize an end-to-end distributed tracing tool. - Measure Certain User Actions
The time it takes to accomplish essential user actions, such as purchasing an item, can be measured via distributed tracing. Backend bottlenecks and issues that degrade the user experience can be identified using traces. - Understand Service Connection
Developers can discover cause-and-effect connections between services and optimize their performance by studying distributed traces. Viewing a database call's span, for example, may demonstrate that adding a new database entry affects slowness in an upstream service. - Flexible Implementation
Developers can integrate distributed tracing tools into nearly any microservices system and monitor data through a single tracing application because they work with a wide range of applications and programming languages. - Maintain Service Level Agreements (SLAs)
SLAs, which are contracts with customers or other internal teams to satisfy performance standards, are common in most companies. Teams may quickly determine if they're meeting SLAs using distributed tracing systems, which collect performance data from specific services. - Improve Productivity and Collaboration
Different teams may own the services involved in completing a request in microservice architectures. Distributed tracing identifies the source of an error and the team responsible for resolving it.
Challenges in Distributed Tracing
Despite these benefits, there are several challenges to overcome when using distributed tracing:
- Backend Coverage Only
A trace ID is generated for a request only when it reaches the first backend service unless you utilize an end-to-end distributed tracing platform. On the front-end, you won't be able to see the related user session. This makes determining the core cause of a bad request and whether the issue should be fixed by a frontend or backend team more difficult. - Manual Instrumentation
To begin tracing requests, some distributed tracing solutions require you to manually instrument or alter your code. Manual instrumentation takes up important engineering time and can lead to bugs in your application, yet it's typically required by the language or framework you're trying to instrument. Missing traces may occur if you standardize which parts of your code to instrument. - Head-based Sampling
Traditional tracing platforms sample traces at random at the start of each request. This method produces traces that are missing or incomplete. Businesses cannot always catch the traces that are most important to them, such as high-value transactions or requests from enterprise customers, using head-based sampling. Some current platforms, on the other hand, can swallow all of your traces and make judgments based on the tail, allowing you to record complete traces with business-relevant attributes like customer ID or region.
Why Distributed Tracing is Important?
It's nearly impossible to pinpoint the service that's causing a performance issue without a mechanism to track requests across multiple services. Distributed tracing allows you to track a request from beginning to end, making troubleshooting much easier.
Companies benefit from modern software architectures in a variety of ways. Microservices, containers, and DevOps, for example, make it easier for teams to manage and maintain their individual services, but they also introduce new issues. Reduced visibility and the increasing difficulty of managing your complete IT infrastructure are two of the most pressing problems.
A slow-running response in a modern application is dispersed among several microservices and serverless tasks that are monitored by multiple teams. Companies have adjusted their observability strategies to enable visibility of the full request cycle, not just isolated services, as a result of this increased complexity.
In a monolithic application, request tracing is simple. It corresponds to Application Performance Monitoring (APM), in which a reporting tool organizes, processes, and visualizes behaviour from requests in order to demonstrate how the system is doing. These insights can help developers quickly diagnose and repair bottlenecks and other performance issues before they have an impact on the customer experience.
In a distributed system with several services, traditional tracing is much more difficult. Microservices scale on their own, allowing for multiple executions of the same function. You can track a request through a single function in a monolithic application, but with microservices, there could be multiple iterations of the same function spread across multiple servers and data centres. You may track requests as they pass through each service using distributed tracing.
Conclusion
Microservices' benefits for constructing cloud-based applications are well documented, and their popularity is showing no signs of slowing down. As these systems get more complicated, distributed request tracing provides a significant advantage over the earlier, needle-in-a-haystack technique to troubleshooting potential service disruptions. If you're in charge of a microservice-based system, giving your company access to this powerful tool will change the way you work.
Monitor Your Entire Application with Atatus
Atatus provides a set of performance measurement tools to monitor and improve the performance of your frontend, backends, logs and infrastructure applications in real-time. Our platform can capture millions of performance data points from your applications, allowing you to quickly resolve issues and ensure digital customer experiences.
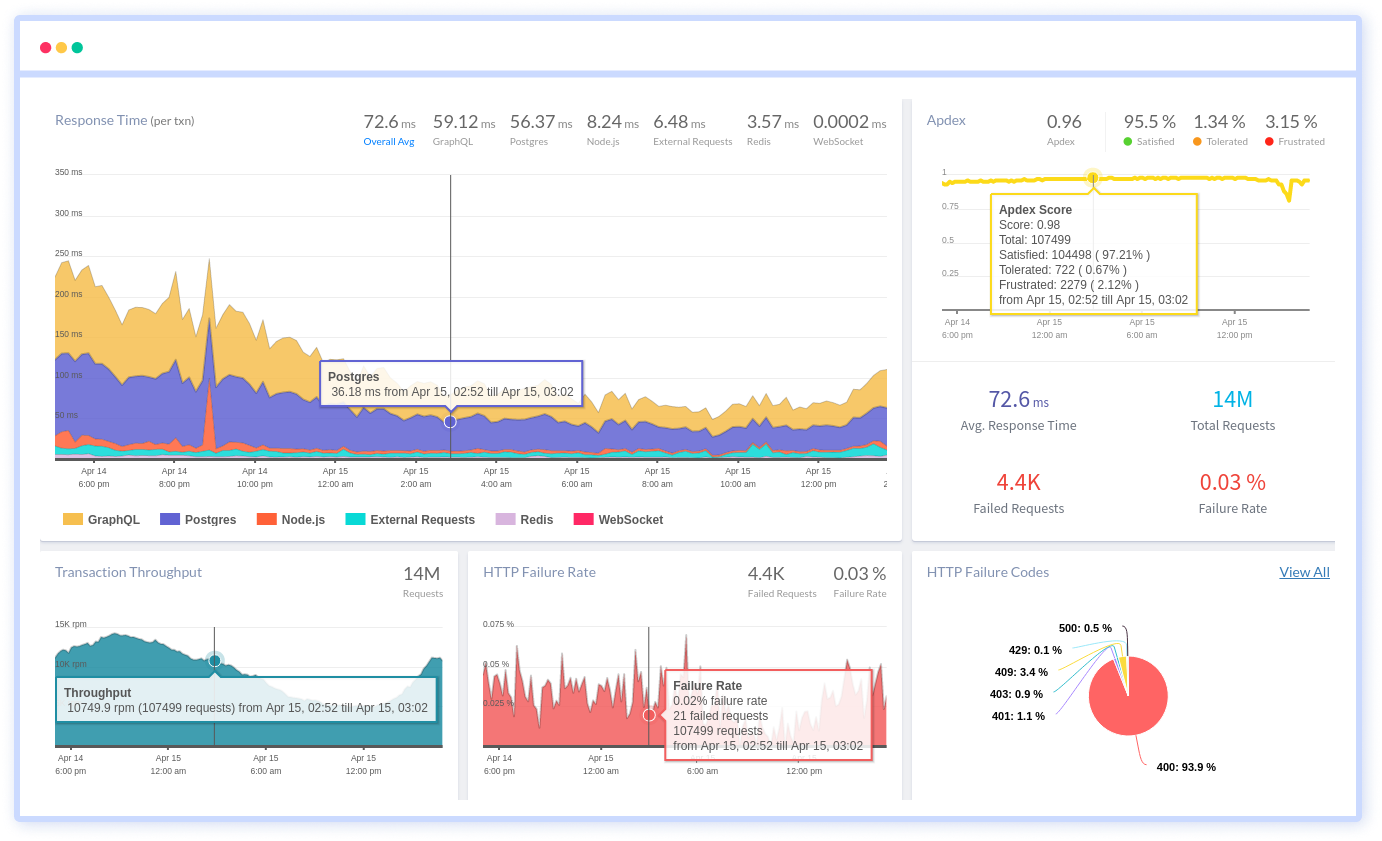
Atatus can be beneficial to your business, which provides a comprehensive view of your application, including how it works, where performance bottlenecks exist, which users are most impacted, and which errors break your code for your frontend, backend, and infrastructure.