Laravel Application Performance Monitoring
Get out-of-the-box visibility into critical KPIs and business performance with our Laravel monitoring tools. Analyze database transactions, debug with detailed traces, and visualize your applications and their dependencies for optimal insights and management.
Where Laravel Production Breaks Down?
Hidden Failures
When requests fail silently, teams learn about issues from users instead of signals. Missing context around what actually broke turns incidents into guesswork.
Slow Root Cause
Errors surface, but the path to the cause is fragmented across logs, traces, and tribal knowledge. Engineers lose hours reconstructing what happened.
Scale Blindness
Traffic grows, workloads spike, and bottlenecks appear without warning. Teams cannot tell whether issues come from code paths, background jobs, or infrastructure pressure.
Async Uncertainty
Queues and workers fail differently than web requests. Without end-to-end visibility, delayed jobs and stuck workers remain invisible until business impact shows up.
Environment Drift
Production behaves differently from staging. Small config or dependency changes compound, and teams lack confidence in what actually changed.
Release Anxiety
Every deploy carries risk because failures only appear after users interact. Rollbacks happen fast, but understanding why they were needed takes much longer.
Signal Ambiguity
Production signals exist, but they lack hierarchy and meaning. Engineers see activity without knowing which changes actually explain user impact or failures.
Team Misalignment
Backend, platform, and SRE teams see different symptoms of the same issue. Without shared context, incident response slows down.
Complete Performance Clarity for
Laravel Applications
Purpose-built observability for Laravel that helps teams understand application behavior, resolve issues faster, and keep production systems running smoothly.
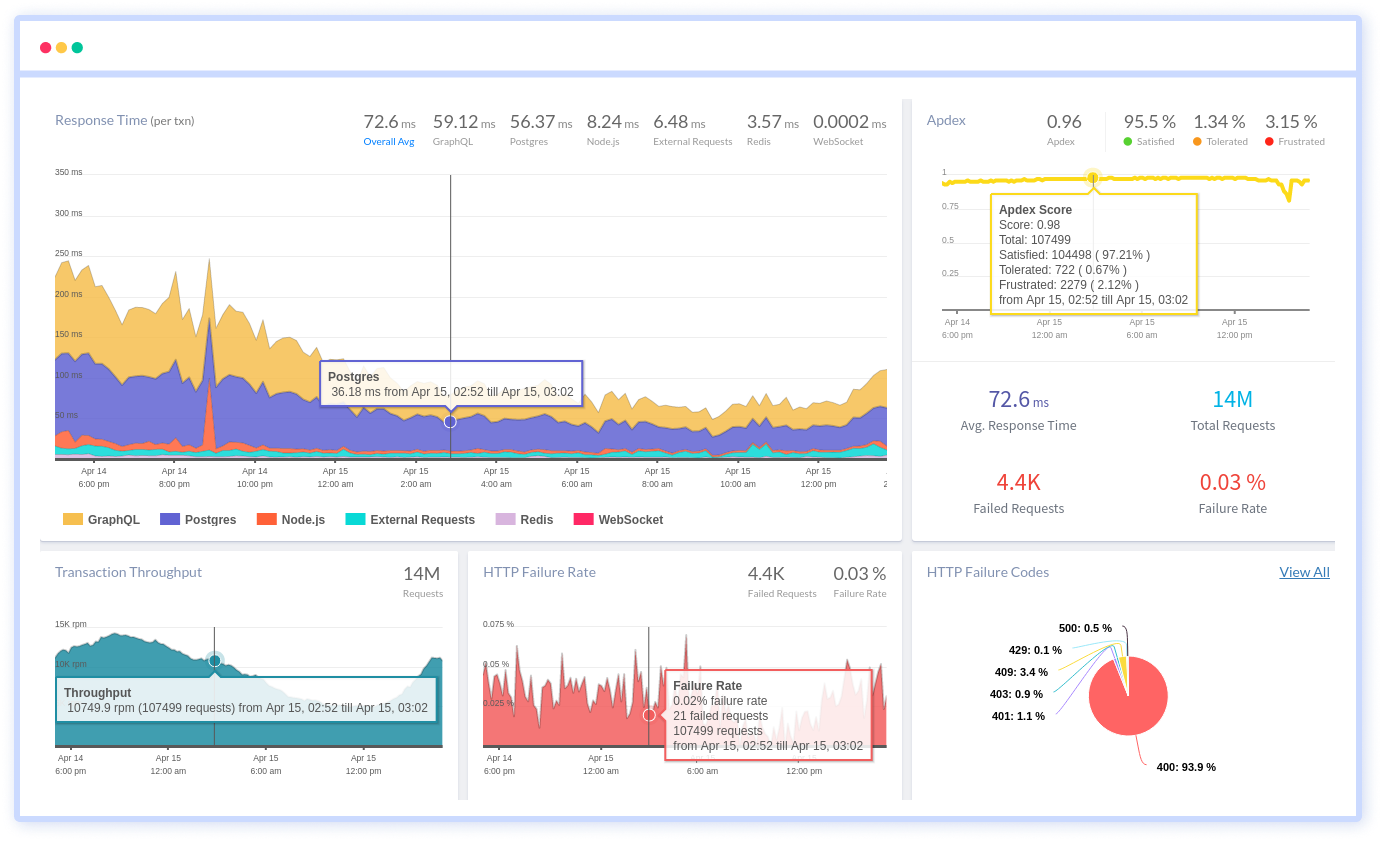
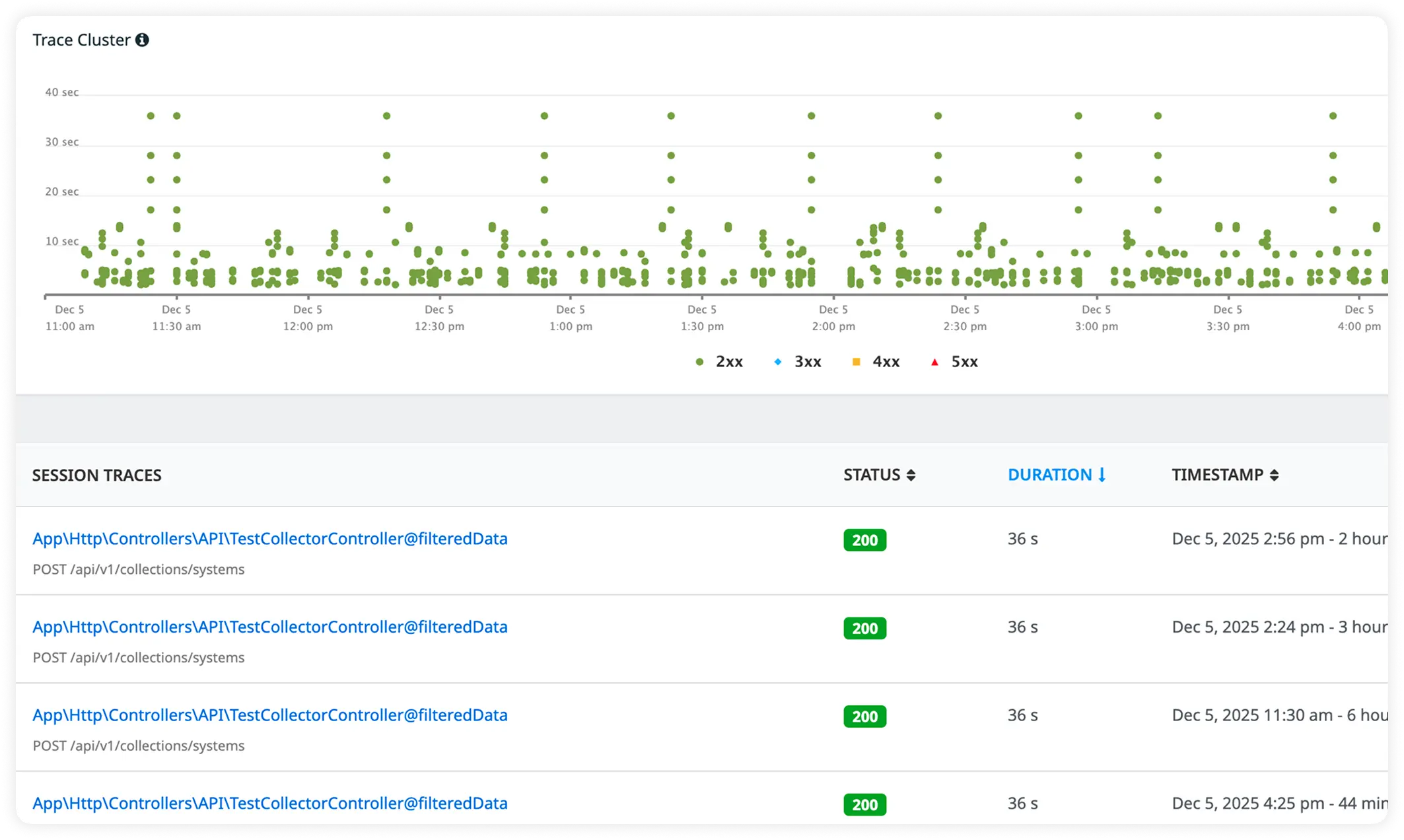
Deep Visibility into Laravel Routes
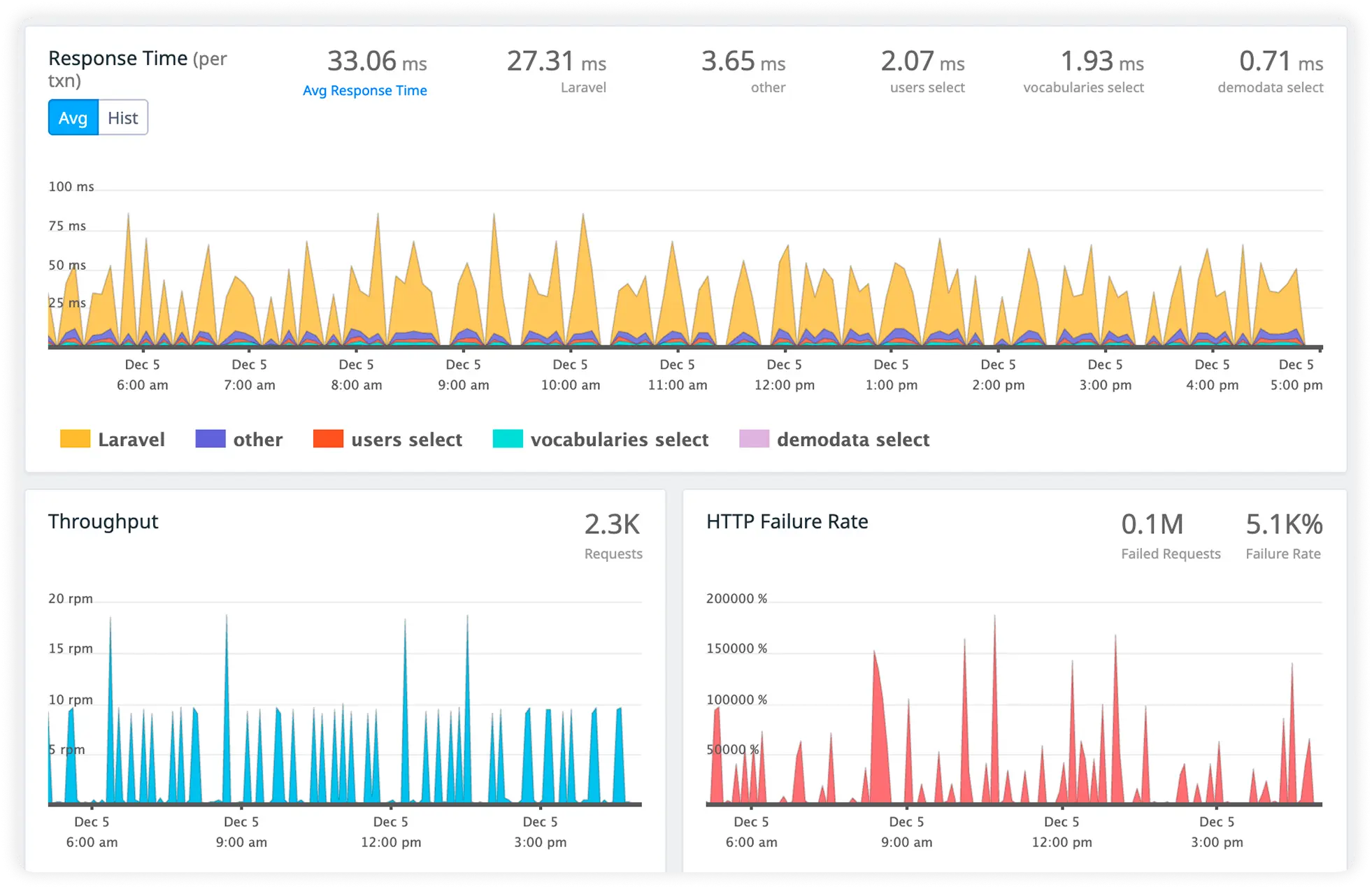
Break down performance at the route level to identify slow endpoints, heavy traffic paths, and error-prone controllers. Get instant clarity on what's impacting response times across your application.
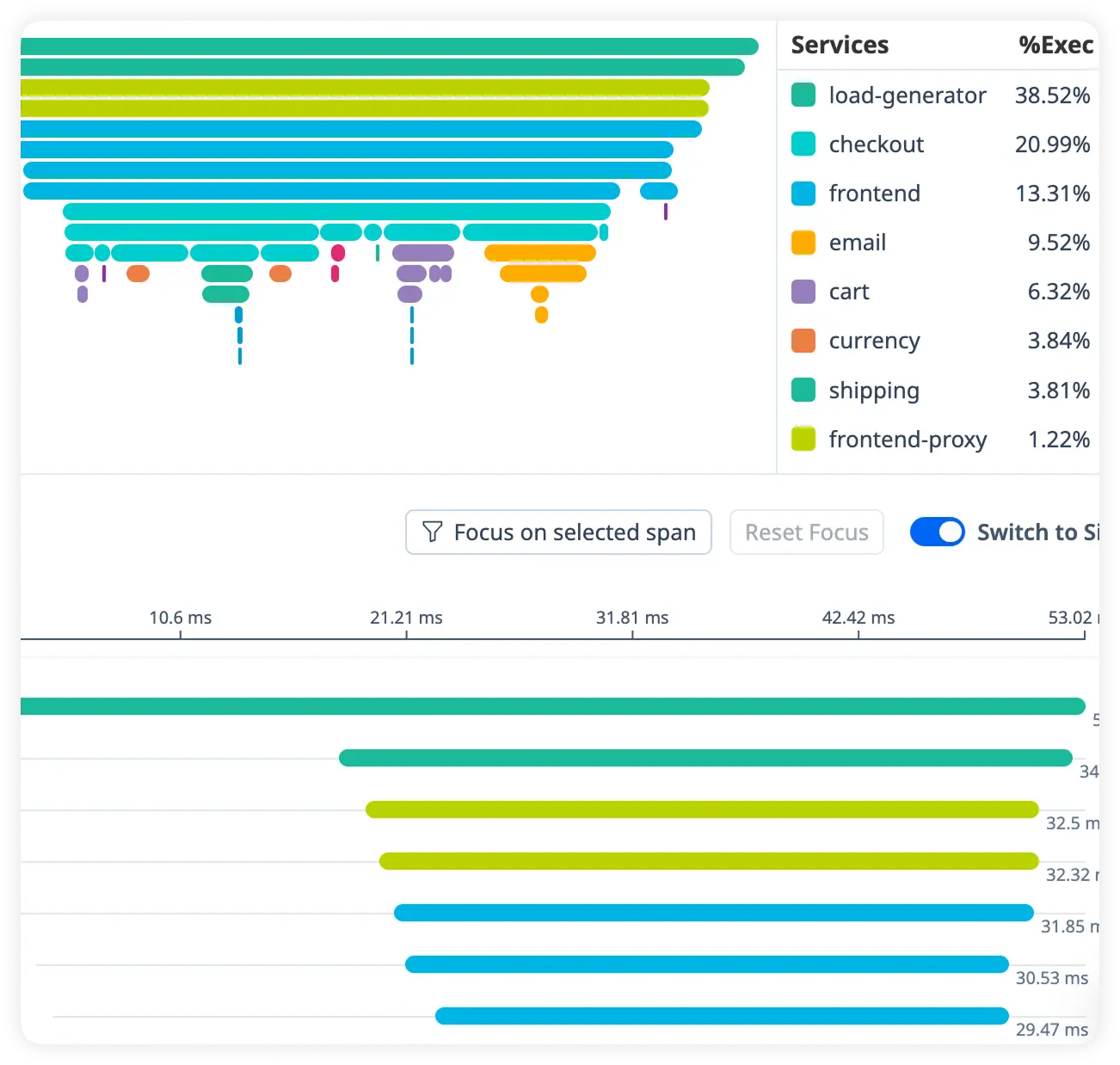
Real-Time Queue Delay Monitoring
Track background job processing and queue wait times to uncover bottlenecks in critical workflows. Ensure emails, payments, and async tasks run without hidden slowdowns.
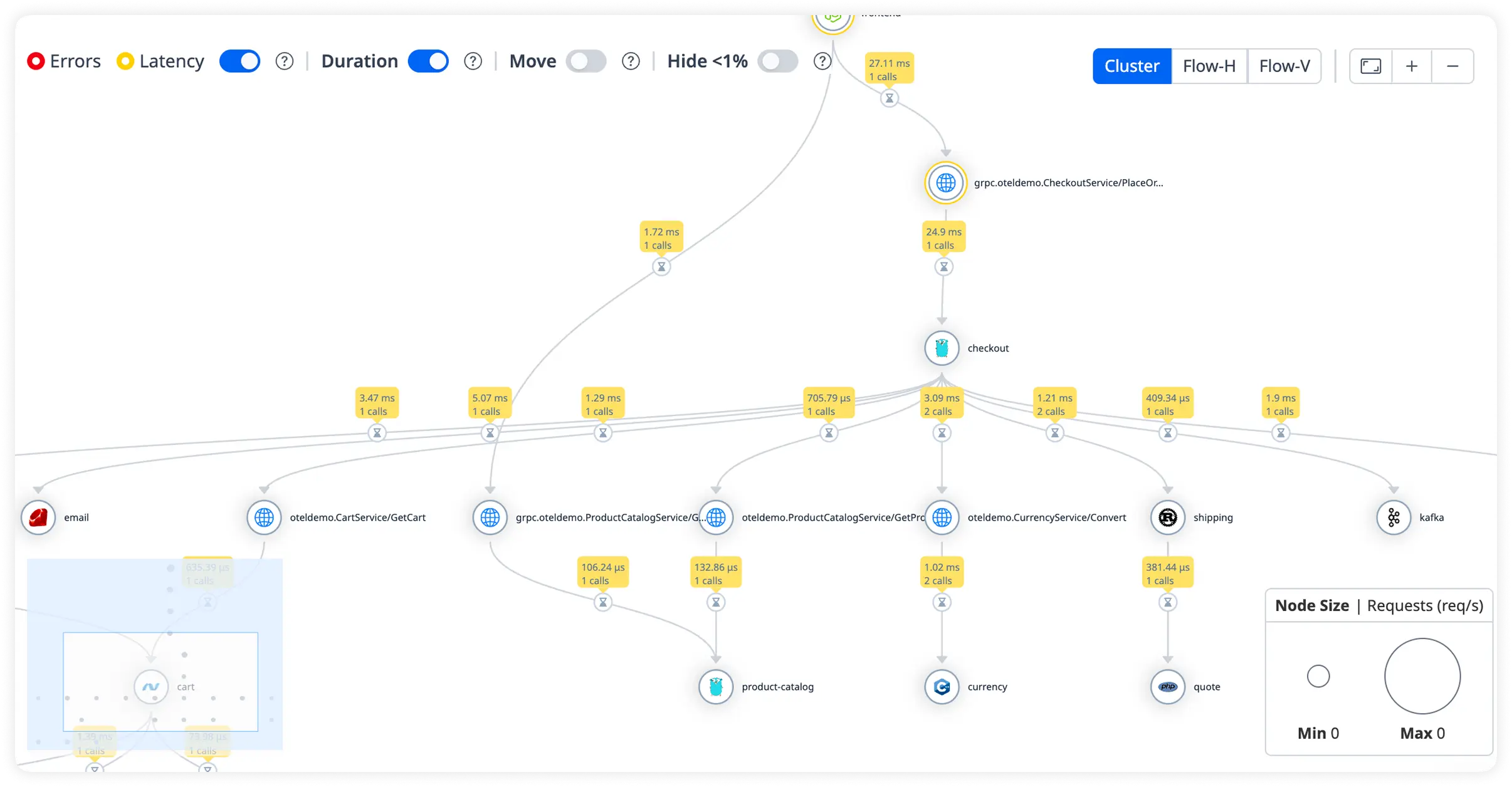
Actionable Database Performance Insight
Monitor slow queries, query volume, and database load across your Laravel environment. Quickly eliminate inefficiencies that degrade application speed.
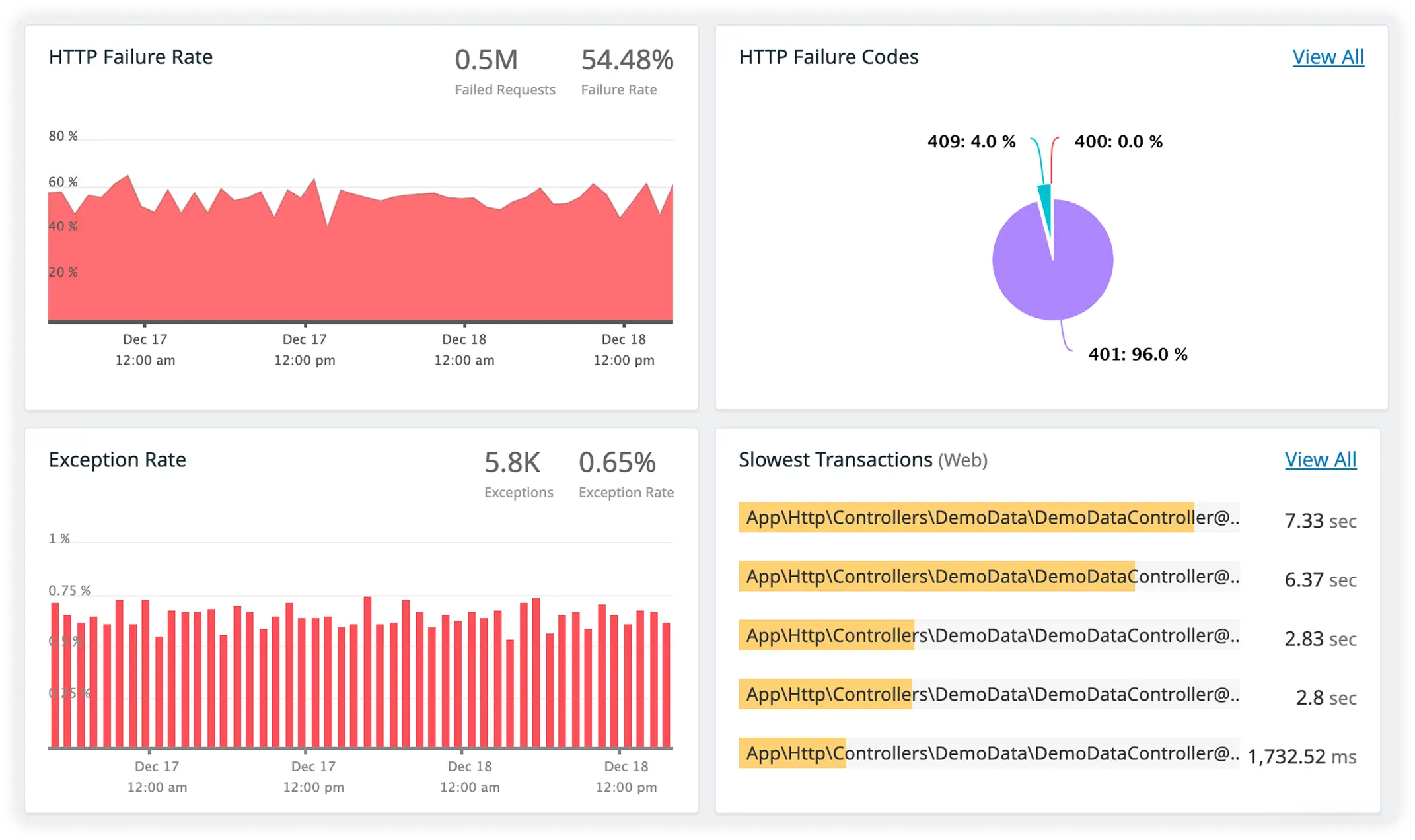
Clear Error Traces and Dependency Timing
View full Laravel stack traces alongside third-party service performance in one place. Pinpoint root causes while tracking how external dependencies impact request latency.
Why Engineering Teams Commit to Atatus?
Engineering teams choose Atatus when they want fewer assumptions in production and more confidence in how their Laravel systems behave under real load.
Clear Signals
Teams trust what they see because data reflects real execution, not approximations or sampled fragments.
Low Friction
Engineers can start trusting production signals without weeks of onboarding or internal evangelism.
Fast Adoption
Engineers start using it immediately without process changes or long onboarding cycles.
Shared Context
Platform, SRE, and backend teams operate from the same source of truth during incidents.
Production Confidence
Deployments feel safer because teams understand how systems react to change in real time.
Operational Simplicity
Minimal operational overhead keeps focus on shipping and stability instead of tool management.
Engineer Trust
Developers rely on the data because it matches what they see in code and production behavior.
Incident Control
Teams stay prepared for failure modes they have not explicitly seen before.
Decision Support
Engineering leaders make calls based on observed system behavior, not assumptions or anecdotes.
Unified Observability for Every Engineering Team
Atatus adapts to how engineering teams work across development, operations, and reliability.
Developers
Trace requests, debug errors, and identify performance issues at the code level with clear context.
DevOps
Track deployments, monitor infrastructure impact, and understand how releases affect application stability.
Release Engineer
Measure service health, latency, and error rates to maintain reliability and reduce production risk.