Understanding the Elasticsearch Query DSL: A Quick Introduction
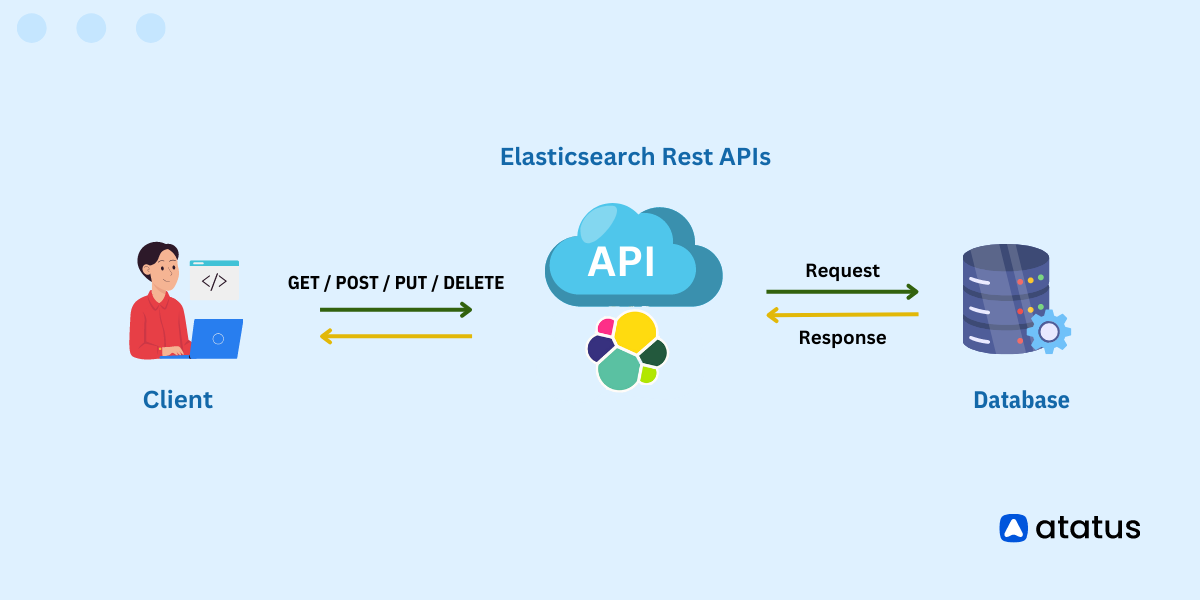
Elasticsearch is a distributed search and analytics engine that excels at handling large volumes of data in real time. When we have such a large repository of data, singling out the most suitable context can be a grueling task. And precisely that’s why we query.
Querying allows us to search and retrieve relevant data from the Elasticsearch index with relative ease. Elasticsearch uses query DSL for this purpose. Query DSL is a powerful tool for executing such types of search queries.
It can be used for full-text search, real-time data analysis, Retrieving structured and unstructured data, geospatial search and for monitoring logs and providing us with useful insights on application and system performance.
In this blog, we will take a look at some of the prominent query types in Elasticsearch. Also, feel free to read through Elasticsearch reference guide although it can be quite daunting.
Table Of Contents
- Query DSL in Elasticsearch
- Types of Queries and their usage:
- Boosting and Scoring Queries
- Querying Performance
Query DSL in Elasticsearch
In Elasticsearch, the Query DSL (Domain-Specific Language) is a powerful tool for constructing and executing various types of searches. It allows you to define complex queries and filters to retrieve data from your Elasticsearch indices.
The Query DSL consists of two main contexts: the query context and the filter context. These contexts serve different purposes and have distinct behaviors.
Query Context
The query context is used to calculate the relevance scores of documents based on the search criteria. It is primarily concerned with matching and scoring documents based on the provided query. In the query context, Elasticsearch evaluates the relevance of each document against the search query and returns the results sorted by relevance score. Here are some commonly used query context clauses:
- match: Performs full-text search on analyzed text fields.
- term: Searches for an exact term in a field.
- range: Matches documents based on a range of values.
- bool: Allows combining multiple queries using boolean logic (e.g., must, must_not, should).
The query context is typically used when you want to retrieve the most relevant documents based on the search query.
Filter Context
The filter context is used to narrow down the result set based on specific criteria without affecting the relevance scores. Unlike the query context, the filter context does not calculate relevance scores and is cacheable for better performance. It is primarily used for exact matches and filtering data. Here are some commonly used filter context clauses:
- term: Filters documents that have an exact term in a field.
- range: Filters documents based on a range of values.
- bool: Allows combining multiple filters using boolean logic (e.g., must, must_not, should).
The filter context is beneficial when you want to apply strict filtering conditions to the result set, such as filtering documents based on specific fields or values.
Example:
curl -X GET "localhost:9200/_search?pretty" -H 'Content-Type: application/json' -d'
{
"query": {
"bool": {
"must": [
{
"match": {
"title": "Search"
}
},
{
"match": {
"content": "Elasticsearch"
}
}
],
"filter": [
{
"term": {
"status": "published"
}
},
{
"range": {
"publish_date": {
"gte": "2023-06-22"
}
}
}
]
}
}
}This is an example where query classes are used in search API. For this query to match the documents, certain conditions have to be met, like, the title field must contain search, content field must contain elasticsearch, the status field should contain the word published, and publish_date should contain a date starting from 2023-06-22.
It's important to note that in Elasticsearch, queries and filters can be used interchangeably in certain contexts. For example, in the bool clause, both queries and filters can be included as sub-clauses. However, using the appropriate context (query or filter) is essential for achieving the desired behavior and performance.
Query Type and its Usage
There are several query types in Elasticsearch. We will take a look at them one by one.
1. Full-text Queries
In Elasticsearch, full-text queries are used to perform text-based search operations on full-text fields. These queries analyze the text in the fields, considering language-specific stemming, tokenization, and relevance scoring to retrieve relevant results.
Here are some commonly used full-text queries in Elasticsearch:
i.) Match Query: The "match" query is a versatile and widely used full-text query. It analyzes the provided text and searches for matching terms in the specified field. It supports various options for controlling the relevance scoring and behavior of the query.
Example:
{
"query": {
"match": {
"description": "elasticsearch tutorial"
}
}
}ii.) Match Phrase Query: The "match_phrase" query matches exact phrases in a field. It analyzes the text and searches for the exact phrase in the specified field.
Example:
{
"query": {
"match_phrase": {
"content": "quick brown fox"
}
}
}iii.) Multi-Match Query: The "multi_match" query allows searching for a query string in multiple fields simultaneously. It can specify different fields and boost values for each field to influence the relevance scoring.
Example:
{
"query": {
"multi_match": {
"query": "elasticsearch tutorial",
"fields": [
"title",
"description^2"
]
}
}
}iv.) Query String Query: The "query_string" query supports advanced query syntax and allows constructing complex search queries. It parses the provided query string and performs full-text search based on the parsed terms.
Example:
{
"query": {
"query_string": {
"query": "(elasticsearch OR search) AND tutorial",
"default_field": "content"
}
}
}2. Term level Queries
Term-level queries find documents based on precise values in the structured data like IP address, data ranges, productIDs, prices, etc.
Term-level queries usually offer high precision since they tend to match the exact same term, unlike the other full-text queries, which search the document based on relevant terms.
Some of the types of term-level queries:
i.) Term Query: The term query is used to search for an exact term in a specific field. It matches documents that have an exact term in the specified field without any analysis or tokenization. For example, to search for documents where the "user" field has the exact value "johnsmith", you can use the following query:
{
"term": {
"user": "johnsmith"
}
}ii.) Terms Query: The terms query allows you to search for documents that match any of the specified terms in a field. It is useful when you want to perform an OR operation on multiple values. For example, to search for documents where the "status" field has either "open" or "pending" as values, you can use the following query:
{
"terms": {
"status": [
"open",
"pending"
]
}
}iii.) Range Query: The range query is used to search for documents within a specified range of values in a numeric or date field. It allows you to define inclusive or exclusive boundaries. For example, to search for documents where the "price" field is between 10 and 100, you can use the following query:
{
"range": {
"price": {
"gte": 10,
"lte": 100
}
}
}iv.) Exists Query: The exists query is used to search for documents that have a non-null value in a specific field. It is useful when you want to find documents that contain a particular field. For example, to search for documents where the "tags" field exists, you can use the following query:
{
"exists": {
"field": "tags"
}
}3. Compound Queries
Compound queries in Elasticsearch allow you to combine multiple queries or filters together to create more complex search conditions. They enable you to express advanced search requirements by combining various clauses and conditions in a single query.
Here are the main types of compound queries available in Elasticsearch:
i.) Bool Query: The bool query is a versatile and commonly used compound query that allows you to combine multiple query or filter clauses using boolean logic. It provides the following clauses:
- must: All specified clauses must match. This is equivalent to the logical
ANDoperation. - must_not: All specified clauses must not match. This is equivalent to the logical
NOToperation. - should: At l east one of the specified clauses must match. You can control the minimum number of matches required using the
minimum_should_matchparameter. - filter: Specifies additional filters that should be applied. Filters in the filter clause are used in the filter context, meaning they do not affect the relevance score calculation.
- The bool query is highly flexible and allows you to create complex search conditions by combining various clauses.
ii.) Constant Score Query: The constant_score query wraps a query or filter and assigns a constant relevance score to all matching documents. It is useful when you want to assign equal importance to all matching documents, regardless of their actual relevance scores. This query is commonly used with filters.
iii.) Disjunction Max Query: The dis_max query allows you to search for documents that match any of the specified queries. It calculates the relevance score for each query separately and returns the maximum score. This is useful when you want to search for multiple terms or phrases and prioritize the documents that match more terms.
iv.) Function Score Query: The function_score query enables you to modify the relevance scores of documents based on custom functions. It allows you to apply functions like decay functions, random scores, script-based scores, etc., to influence the relevance ranking.
4. Geo Queries
Geo queries in Elasticsearch are used to search for documents based on their geographical location. Elasticsearch supports various geo queries to perform spatial searches and filter documents within a certain distance or geographic shape.
Here are some commonly used geo queries in Elasticsearch:
i.) Geo Distance Query: The geo_distance query allows you to search for documents within a certain distance from a specified location. You can define the distance as a radius or use other distance units such as miles or kilometers. For example, to search for documents within 10 kilometers of latitude 51.5074 and longitude -0.1278 (coordinates of London), you can use the following query:
{
"geo_distance": {
"distance": "10km",
"location": {
"lat": 51.5074,
"lon": -0.1278
}
}
}ii.) Geo Bounding Box Query: The geo_bounding_box query allows you to search for documents within a rectangular bounding box defined by two sets of coordinates. It is useful when you want to find documents within a specific area. For example, to search for documents within the bounding box defined by the top-left corner (lat1, lon1) and bottom-right corner (lat2, lon2), you can use the following query:
{
"geo_bounding_box": {
"location": {
"top_left": {
"lat": 52.074,
"lon": 45.986
},
"bottom_right": {
"lat": -0.1278,
"lon": -1.4353
}
}
}
}iii.) Geo Polygon Query: The geo_polygon query allows you to search for documents within a specified polygon defined by multiple latitude-longitude points. It is useful when you want to find documents within a custom-shaped area. For example, to search for documents within a polygon defined by three points (A, B, C), you can use the following query:
{
"geo_polygon": {
"location": {
"points": [
{
"lat": latA,
"lon": lonA
},
{
"lat": latB,
"lon": lonB
},
{
"lat": latC,
"lon": lonC
}
]
}
}
}5. Match Queries
The Match Query in Elasticsearch is a full-text query that is used to search for documents based on a specific text value or a set of analyzed terms. It analyzes the search query text using the same analyzer that was used at index time for the specified field, enabling the search to match documents that contain the analyzed terms.
Here is an example of using the Match Query in Elasticsearch:
{
"query": {
"match": {
"title": "search term"
}
}
}In this example, we are searching for documents where the "title" field contains the term "search term". The Match Query will analyze the search term using the analyzer configured for the "title" field and match documents that have the analyzed terms.
By default, the Match Query performs an OR operation, meaning it will return documents that match any of the analyzed terms. If you want to perform an AND operation and retrieve documents that match all the terms, you can specify the "operator" parameter as "AND" in the query:
{
"query": {
"match": {
"title": {
"query": "search term",
"operator": "AND"
}
}
}
}Additionally, you can control the relevance scoring of the Match Query using parameters such as "fuzziness" for approximate matching, "boost" to adjust the relevance score, and minimum_should_match to specify the minimum number of terms that should match.
6. Range Queries
Range queries in Elasticsearch are used to search for documents that fall within a specified range of values in a numeric or date field. Range queries allow you to define inclusive or exclusive boundaries and can be used to filter documents based on a specific range.
Here are examples of different range queries in Elasticsearch:
i.) Numeric Range Query: The numeric range query is used to search for documents within a range of numeric values in a field. For example, to search for documents where the "price" field is between 10 and 100, you can use the following range query:
{
"range": {
"price": {
"gte": 10,
"lte": 100
}
}
}In this example, the gte parameter specifies a greater-than-or-equal-to condition, and the lte parameter specifies a less-than-or-equal-to condition. You can also use gt (greater-than) and lt (less-than) for exclusive boundaries.
ii.) Date Range Query: The date range query is used to search for documents within a range of dates or timestamps. For example, to search for documents created between two specific dates, you can use the following range query:
{
"range": {
"created_at": {
"gte": "2022-01-01",
"lte": "2022-12-31"
}
}
}In this example, the created_at field is assumed to be of date or timestamp type, and the gte and lte parameters define the inclusive range of dates.
iii.) IP Range Query: The IP range query is used to search for documents within a range of IP addresses. For example, to search for documents where the ip_address field is within a specific IP range, you can use the following range query:
{
"range": {
"ip_address": {
"gte": "192.168.0.0",
"lte": "192.168.255.255"
}
}
}In this example, the ip_address field is assumed to be of IP address type, and the gte and lte parameters specify the inclusive range of IP addresses.
Boosting and Scoring Queries
Elasticsearch has a default mechanism by which it sorts queries based on relevance scores. This score is arrived when the documents exactly match the query.
The relevance score is a positive floating point number returned by the search API's _score metadata field. The higher the _score, the more relevant the document. There are a variety of ways to calculate relevance scores based on query type, but the calculation also depends on whether the query clause is run in a query or filter context.
Boosting queries also come in handy when we have to demote certain queries, but don't want to omit the entire query itself. For example, when we are searching for a specific search term from a long list, like that of an employee name list.
POST employees/_search
{
"query": {
"boosting": {
"positive": {
"match": {
"country": "India"
}
},
"negative": {
"match": {
"company": "Namlabs"
}
},
"negative_boost": 0.5
}
}
}The positive section specifies the positive query that documents must match to receive a higher score. In this case, it is looking for documents where the "country" field matches the value "India".
The negative section specifies the negative query that documents must not match. Documents matching this query will have their score reduced. Here, it is looking for documents where the "company" field matches the value Namlabs.
The negative_boost parameter sets the boosting factor for the negative query. A value of 0.5 means that documents matching the negative query will have their score reduced by half.
When you run this query on Elasticsearch, it will give back results based on relevant boost scores. High positive scores will be first shown followed by negative boost scores.
Querying performance
There are several factors which affect query performance in Elasticsearch. We have listed the common factors below:
- Data Volume - The size of your data can be an important deciding factor. When we have significantly larger data sets, retrieving data will take longer.
- Data Model and Indexing - The way your data is modeled and the choice of data types, mapping settings etc can either increase or decrease the query retrieval rate.
- Complex Queries - If you have nested queries, or queries with complex filters and many aggregations will complicate the process of querying.
- Sharding and Replication - Elasticsearch replicates data and distributes it across multiple shards for proper organization and decreasing the overhead. We must balance replica numbers and cluster sizes to keep an optimal workload.
- Cluster Health - Each cluster is embossed with overloaded nodes, network latency, disk I/O bottlenecks, or inadequate resource allocation, etc. These can negatively affect query performance. So the solution is proper and regular monitoring.
- Caching - By default, Elasticsearch provides caching mechanism. This allows caching frequently accessed data into one single unit which can then be retrieved with relative ease.
- Network Latency - Latency issues from the client side server owing to erratic network connections and all can significantly affect querying performance.
Conclusion
Elasticsearch Query DSL provides a powerful and flexible way to query data stored in Elasticsearch.
With a variety of query types and subtypes available, including range queries, geo queries, compound queries, and match queries, developers can easily construct complex queries to retrieve the data they need.
By understanding how to use these query types and subtypes, developers can take full advantage of Elasticsearch's capabilities and build robust search applications that deliver accurate and relevant results to their users.
By leveraging the power of the Query DSL in Elasticsearch, you can construct flexible and precise search queries to retrieve the data that meets your requirements.
As Elasticsearch continues to grow in popularity, it's clear that Query DSL will remain an essential tool for any developer working with Elasticsearch.
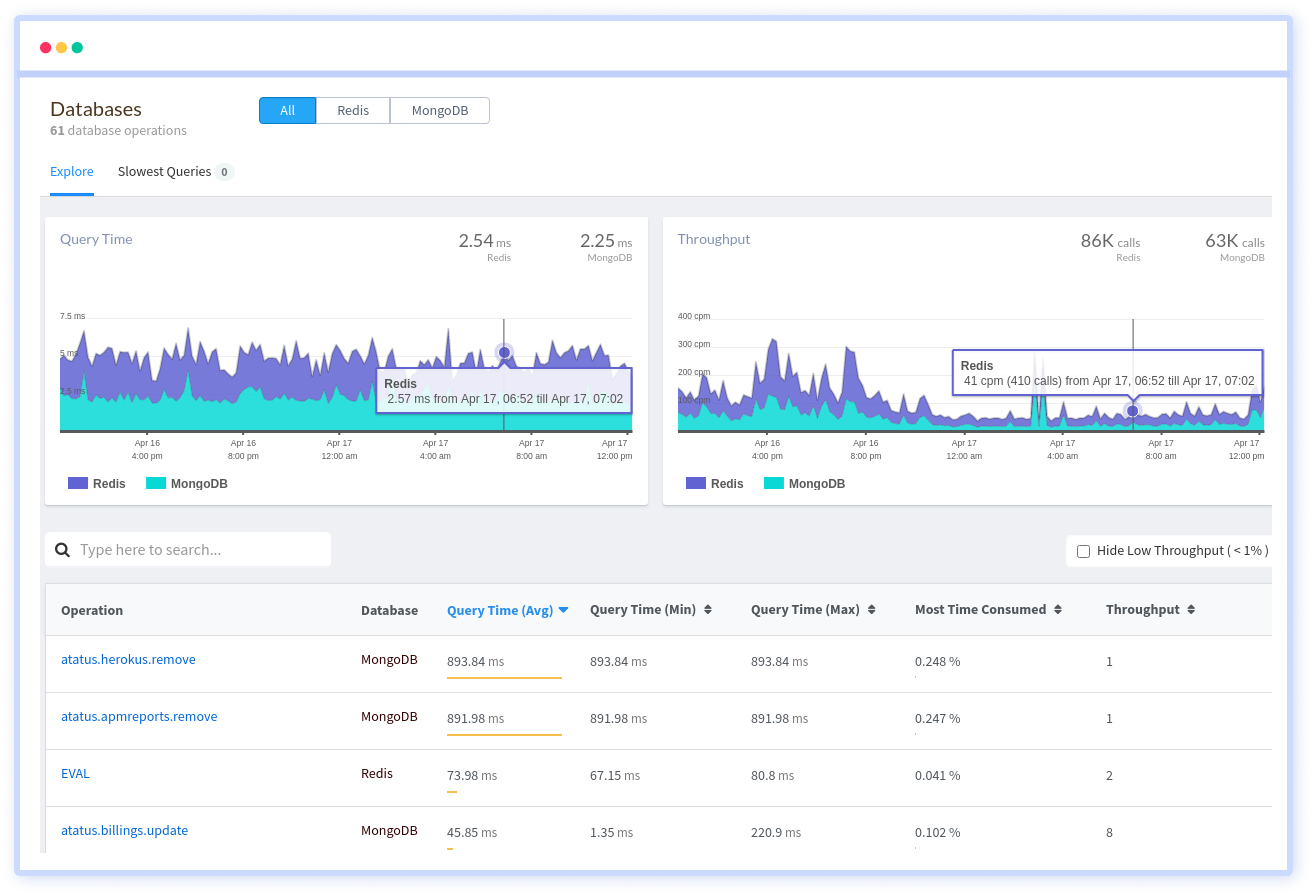
Database Monitoring with Atatus
Atatus provides you an in-depth perspective of your database performance by uncovering slow database queries that occur within your requests, and transaction traces to give you actionable insights. With normalized queries, you can see a list of all slow SQL calls to see which tables and operations have the most impact, know exactly which function was used and when it was performed, and see if your modifications improve performance over time.
Atatus benefit your business, providing a comprehensive view of your application, including how it works, where performance bottlenecks exist, which users are most impacted, and which errors break your code for your frontend, backend, and infrastructure.
#1 Solution for Logs, Traces & Metrics
![]() APM
APM
![]() Kubernetes
Kubernetes
![]() Logs
Logs
![]() Synthetics
Synthetics
![]() RUM
RUM
![]() Serverless
Serverless
![]() Security
Security
![]() More
More