Getting Started with Elasticsearch Mapping
Elasticsearch Mapping is a process of defining the schema or structure of the data that is going to be indexed and searched.
Mapping determines how Elasticsearch will interpret and handle the data being indexed, including the field names, data types, and how they are analyzed and indexed for search.
Mapping in Elasticsearch is essential for ensuring that the data is indexed and searched accurately and efficiently.
It provides a blueprint of the data structure and helps Elasticsearch to understand the relationships between different data fields, which enables it to perform advanced searches and aggregations on the data.
Table Of Contents:-
- Introduction to Elasticsearch Mapping
- Get Mapping Requests
- Understanding the Structure of Elasticsearch Mapping
- Defining Field Datatypes
- Mapping Complex Data Structures in Elasticsearch
- Using Dynamic Mapping in Elasticsearch
- Updating Elasticsearch Mapping
- Limit the number of Fields
Introduction to Elasticsearch Mapping
In Elasticsearch, mapping refers to the process of defining the schema or structure of the data that will be stored and indexed in the search engine. It determines how Elasticsearch interprets and indexes the fields within your documents.
When you index a document in Elasticsearch, it automatically detects the data types of the fields based on the values provided. However, if you want more control over how your data is indexed and searched, you can explicitly define the mapping.
By defining the mapping, you can control how Elasticsearch indexes and analyzes your data, which can have a significant impact on search performance and relevance. Mapping helps Elasticsearch understand the structure and characteristics of your data, ensuring that the indexed documents are organized and searchable in an efficient and meaningful way.
Here's an example of creating an index with a predefined mapping in Elasticsearch:
PUT /my_index
{
"mappings": {
"properties": {
"title": {
"type": "text"
},
"description": {
"type": "text"
},
"price": {
"type": "float"
},
"stock_count": {
"type": "integer"
},
"is_active": {
"type": "boolean"
},
"created_at": {
"type": "date"
}
}
}
}By defining the mapping upfront, Elasticsearch knows the data types and properties of each field, allowing for optimized indexing and search operations.
You can adjust the mapping according to your specific requirements, adding or modifying fields and their properties as needed.
Understanding the Structure of Elasticsearch Mapping
Understanding the structure of Elasticsearch mapping is crucial for designing and working with mappings effectively. Elasticsearch mapping consists of several components that define the schema or structure of the data being indexed. These components include:
- Index Settings: Index settings define the configuration settings for the index, such as the number of shards, replication factors, and analysis settings.
- Field Mappings: Field mappings define the data fields in the index and their data types, as well as any additional field properties, such as indexing options, analysis settings, or storage requirements.
- Metadata Fields: Metadata fields are additional fields that Elasticsearch adds to each document in the index, such as the _id, _index, and _type fields. These fields are used for internal indexing and search operations.
- Dynamic Mapping: Dynamic mapping is a feature that allows Elasticsearch to automatically detect and create mappings for new fields as they are added to the index. Dynamic mapping can be configured to apply custom mappings or ignore certain fields.
Together, these components form the structure of Elasticsearch mapping. The mapping structure is represented as a JSON object, which can be retrieved and modified using Elasticsearch APIs. By understanding the structure of Elasticsearch mapping, you can design efficient and effective mappings that accurately index and search your data.
Defining Field Datatypes
Defining the appropriate field type for each data field is essential for accurate indexing and searching in Elasticsearch. Choosing the right field type ensures that the data is analyzed and indexed correctly, which leads to more accurate search results and faster search queries.
Elasticsearch supports several field types, including:
- Text: This field type is used for full-text search and analysis of text data. Text fields are analyzed, meaning they are broken down into individual terms for searching.
- Keyword: This field type is used for keyword-based search and analysis of non-textual data, such as IDs, categories, or tags. Keyword fields are not analyzed and are searchable as exact values.
- Numeric: This field type is used for numeric data, such as integers, floats, and doubles. Numeric fields can be used for range queries and sorting.
- Date: This field type is used for dates and time-based data. Date fields can be used for range queries and sorting.
- Boolean: This field type is used for boolean data, such as true/false or yes/no values.
- Binary: This field type is used for storing binary data, such as images or documents.
In addition to these basic field types, Elasticsearch also supports complex field types, such as nested, object, and geo-point fields, which can be used to index and search complex data structures, such as arrays or geographical data.
Elasticsearch Get Mapping Requests
Get mapping request is a request to Elasticsearch that retrieves the mapping for a specific index or indices. To make a get mapping request, you can use the following syntax
GET /<index>/_mappingIn this syntax, <index> refers to the name of the index or indices for which you want to retrieve the mapping. For example, to retrieve the mapping for an index named "my_index", you can use the following request:
GET /my_index/_mappingThis request will return a JSON object containing the mapping for the specified index or indices. The JSON object will include a nested structure that describes the fields and their data types, as well as any custom mappings that have been applied.
By examining the mapping of an index, you can gain insight into the data structure and how Elasticsearch is handling the data. This can be useful for troubleshooting indexing or searching issues, as well as for designing more efficient mappings for future indices.
Mapping Complex Data Structures in Elasticsearch
Mapping complex data structures in Elasticsearch requires careful consideration of the data schema and the desired search and analysis behavior. Complex data structures can include nested or hierarchical data, arrays of objects, or dynamic fields that are added at runtime.
To map complex data structures in Elasticsearch, you need to define the fields and their data types, as well as any additional field properties, such as indexing options, analysis settings, or storage requirements. Elasticsearch Mapping API helps you to define custom mappings for your index.
1. Using Nested Objects
One approach to mapping complex data structures is to use nested objects. Nested objects allow you to index and search on the nested fields as if they were independent documents, while still maintaining the hierarchical relationship between the fields. To use nested objects, you need to define the field as a nested type and specify the fields within the nested object.
For example, suppose you have a document with nested fields representing a list of products with multiple attributes. You can map this data structure as follows:
PUT /my_index/_mapping
{
"properties": {
"product_list": {
"type": "nested",
"properties": {
"product_name": {
"type": "text"
},
"product_category": {
"type": "keyword"
},
"product_attributes": {
"type": "nested",
"properties": {
"attribute_name": {
"type": "text"
},
"attribute_value": {
"type": "text"
}
}
}
}
}
}
}In this example, the product_list field is defined as a nested object, and the product_attributes field is also defined as a nested object within the product_list object. This mapping allows you to perform complex queries and aggregations on the nested fields.
2. Using Multi-fields
Another approach to mapping complex data structures is to use multi-fields. Multi-fields allow you to index the same field with multiple data types or different analysis settings. This can be useful when dealing with fields that contain both text and numeric data, or when you need to perform different analysis on different parts of a field.
For example, suppose you have a document with a field representing a date and time as a string. You can map this data structure as follows:
PUT /my_index/_mapping
{
"properties": {
"date_time": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss",
"fields": {
"raw": {
"type": "keyword"
}
}
}
}
}In this example, the date_time field is defined as a date type with a specific date format. The fields property includes a raw sub-field, which is defined as a keyword type. This allows you to search on the date_time field using both the date format and the keyword format.
Dynamic vs Static Mapping in Elasticsearch
Here are the key differences between dynamic mapping and static mapping in Elasticsearch:
1. Definition
Dynamic mapping: Elasticsearch automatically creates a mapping for fields when a document is indexed, based on the field's data type and content.
Static mapping: Mapping is explicitly defined by the user, either when the index is created or when new fields are added to the index.
2. Flexibility
Dynamic mapping: Allows for flexibility in adding new fields to the index without the need for explicitly defining a mapping beforehand.
Static mapping: Provides more control over the indexing process, ensuring consistency and accuracy of data indexed into Elasticsearch.
3. Maintenance
Dynamic mapping: Can lead to mapping inconsistencies and errors if Elasticsearch incorrectly infers the data type or if there are conflicts between fields with the same name but different data types.
Static mapping: Requires more effort to set up and maintain than dynamic mapping but ensures that the data is indexed according to the specified mapping.
4. Example
Here's a simple example to illustrate the difference between dynamic and static mapping:
Suppose you have an index named "products" in Elasticsearch that contains information about products. Initially, the index has only two fields: "name" (string) and "price" (float).
Dynamic Mapping: When you add a new document to the index with a new field "description" (string), Elasticsearch will automatically create a mapping for the new field based on its data type, without the need for explicitly defining it beforehand.
POST /products/_doc/
{
"name": "Product 1",
"price": 19.99,
"description": "A new product"
}
In this case, Elasticsearch will create a dynamic mapping for the new "description" field.
Static Mapping: On the other hand, if you want to ensure consistency and accuracy of data indexed into Elasticsearch, you can define a static mapping when creating the index. For example, you can create an index with a static mapping that defines the "description" field as a "text" data type.
PUT /products
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"price": {
"type": "float"
},
"description": {
"type": "text"
}
}
}
}In this case, when you add a new document to the index with a "description" field, Elasticsearch will index the field according to the defined mapping.
Using Dynamic Mapping in Elasticsearch
Dynamic mapping in Elasticsearch is a feature that automatically detects and creates mappings for new fields as they are added to an index. This can be a useful feature for indexing data with changing schemas or when dealing with large amounts of data with many fields.
To use dynamic mapping in Elasticsearch, you need to ensure that it is enabled for the index or indices where you want to use it. Dynamic mapping is enabled by default in Elasticsearch, but you can customize its behavior by updating the dynamic mapping settings.
To update the dynamic mapping settings, you can use the following API call:
PUT /<index>/_mapping
{
"dynamic": "true/false",
"dynamic_templates": [
{
"template_1": {
"match": "pattern",
"mapping": {
"field_type": "type",
"index": "analyzed/not_analyzed",
"analyzer": "analyzer_name"
}
}
}
]
}In this syntax, <index> refers to the name of the index where you want to update the dynamic mapping settings. The dynamic parameter specifies whether dynamic mapping should be enabled (true) or disabled (false). The dynamic_templates parameter allows you to define custom mappings for fields that match specific patterns.
For example, the following API call disables dynamic mapping for an index named "my_index":
PUT /my_index/_mapping
{
"dynamic": false
}This call disables dynamic mapping for the entire index, which means that new fields will not be automatically mapped.
To use dynamic mapping with custom templates, you can define one or more templates that specify the field patterns to match and the custom mapping to apply. For example, the following template maps all string fields that start with "description_" to the text type:
PUT /my_index/_mapping
{
"dynamic_templates": [
{
"description_template": {
"match": "description_*",
"mapping": {
"type": "text"
}
}
}
]
}This template applies to any new field that matches the pattern "description_*" and maps it to the text type.
Updating Elasticsearch Mapping
Updating an Elasticsearch mapping can be done using the Update Mapping API. This API allows you to modify the existing mapping of a field or add new fields to an existing index.
To update an Elasticsearch mapping, follow these steps:
Create a new mapping definition that includes the changes you want to make to the existing mapping. You can define new properties or modify existing ones, but you cannot remove properties that are already indexed
For example, suppose you want to add a new field "new_field" to an existing index "my_index". You can create a mapping definition as follows:
PUT my_index/_mapping
{
"properties": {
"new_field": {
"type": "keyword"
}
}
}Submit the mapping update request using the Update Mapping API. You can do this using a PUT request to the _mapping endpoint, specifying the name of the index and the new mapping definition.
PUT my_index/_mapping
{
"properties": {
"new_field": {
"type": "keyword"
}
}
}This will update the mapping of the my_index index to include the new field.
Note that updating an Elasticsearch mapping can have significant impact on the existing data and search performance, so it's important to carefully plan and test any mapping changes before applying them to a production environment.
Limit the number of fields
Here are some strategies to prevent overloading of memory due to excess data fields in Elasticsearch mapping:
- Use field data types: Elasticsearch provides a wide range of data types, and it's important to choose the appropriate data type for each field. For example, using the text data type for a field that contains only numbers can result in wasted memory and slower queries. By choosing the appropriate data type, you can reduce memory usage and improve query performance.
- Use dynamic mapping templates: Dynamic mapping templates allow you to define rules for mapping fields based on their names and types. This can help prevent the creation of unnecessary fields and reduce memory usage.
- Use index templates: Index templates allow you to define a mapping template that will be applied to any new indices that match a certain pattern. By using index templates, you can ensure that all new indices have a consistent and optimized mapping.
- Limit the number of fields: If you have a large number of fields in your mapping, consider limiting the number of fields by splitting your data into multiple indices or by using nested fields.
Index.mapping.total_fields.limit- which is automatically set to 1000. - Use field aliases: Field aliases allow you to define an alternate name for a field. This can be useful when you need to change the name of a field, but don't want to reindex all of your data.
- Monitor memory usage: It's important to monitor memory usage and adjust your mapping and indexing strategies as needed. Elasticsearch provides a number of monitoring and diagnostic tools that can help you identify memory issues and optimize your system.
Conclusion
Elasticsearch Mapping is all about determining the structure of data that is going to be indexed and searched. This includes a series of field types, and data arrays and the process of analyzing these data sets.
In this blog, we go through different phases of Elasticsearch Mapping, starting with understanding mapping structure, followed by defining field types and mapping complex data structures.
Mapping complex data structures in Elasticsearch requires careful consideration of the data schema and the desired search and analysis behavior. By using nested objects, multi-fields, and other custom mappings, you can create efficient and effective mappings for your data.
Then we move onto Dynamic Mapping which is a powerful feature that allows for the automatic mapping of new fields as they are added to an index. By customizing the dynamic mapping settings and using dynamic templates, you can create efficient and effective mappings for your data.
Also to prevent overloading of memory due to excess data fields in Elasticsearch mapping, you must be good if you go with the suggestions listed above.
Database Monitoring with Atatus
Atatus provides you an in-depth perspective of your database performance by uncovering slow database queries that occur within your requests, and transaction traces to give you actionable insights. With normalized queries, you can see a list of all slow SQL calls to see which tables and operations have the most impact, know exactly which function was used and when it was performed, and see if your modifications improve performance over time.
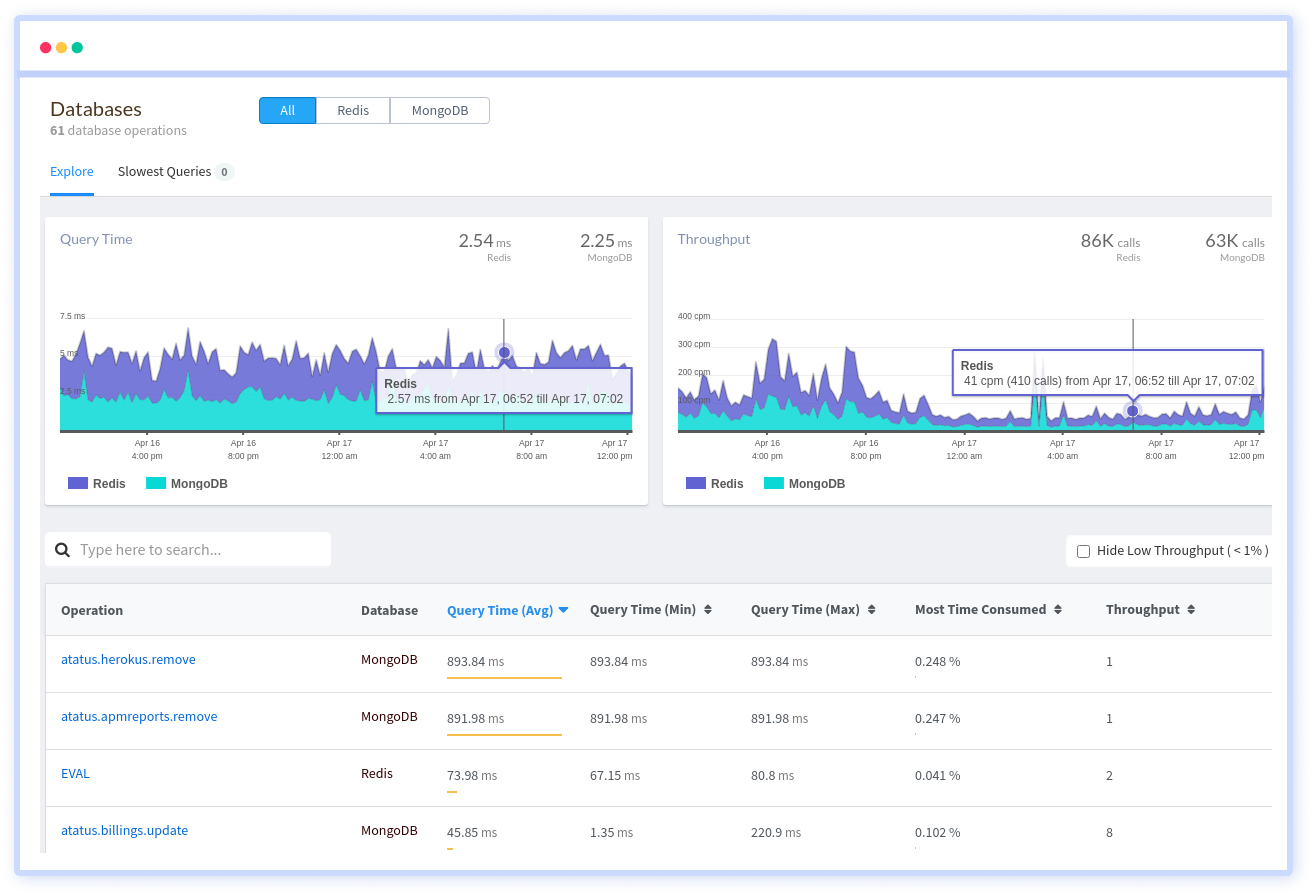
Atatus benefit your business, providing a comprehensive view of your application, including how it works, where performance bottlenecks exist, which users are most impacted, and which errors break your code for your frontend, backend, and infrastructure.
#1 Solution for Logs, Traces & Metrics
![]() APM
APM
![]() Kubernetes
Kubernetes
![]() Logs
Logs
![]() Synthetics
Synthetics
![]() RUM
RUM
![]() Serverless
Serverless
![]() Security
Security
![]() More
More