Kubernetes Events- A Complete Guide!

Kubernetes stands out as a powerful orchestrator, managing the deployment, scaling, and operation of containerized workloads. A key component of Kubernetes observability and troubleshooting capabilities is the generation of events.
These events serve as vital records, documenting incidents and changes within the cluster, offering real-time insights into the health and dynamics of the system.
Thus events become crucial indicators that help administrators and developers troubleshoot issues, monitor cluster health, and respond effectively to the ever-changing landscape of a Kubernetes cluster.
Are you interested in learning more? Let's get started!
Table of Contents
- Introduction to Kubernetes Events
- Resource Allocation and Pod Dynamics
- Kubernetes Event Classifications
- Important Kubernetes Events
- Efficient Filtering of Kubernetes Events
- Event Monitoring
Introduction to Kubernetes Events
In Kubernetes, events are records of incidents or occurrences related to the resources within the system. These events provide information about the state and changes in the cluster. They can include details about successful operations, errors, or warnings.
For example, if a pod fails to start, an event will be generated to indicate the failure along with relevant details. Events help administrators and developers troubleshoot issues, monitor the health of the cluster, and understand the history of activities. They are a crucial part of Kubernetes' observability and debugging capabilities.
Resource Allocation and Pod Dynamics
To enhance comprehension of events, it is crucial to grasp how Kubernetes allocates resources and initializes containers within a running application.
In Kubernetes, applications exhibit variability and are not consistently stable. They constantly change their resource needs, based on user demand, application workload, network traffic and much more.
Imagine a busy restaurant adjusting staff based on customer flow – Kubernetes does something similar, managing resources like CPU and memory for your apps.
Sometimes, Kubernetes might shift resources purposefully or face unexpected changes, leading to pod evictions or node failures. Understanding these events is crucial. Suppose if a pod suddenly disappears, an event note appears, helping us understand why.
Thus these events are key to responding effectively to the ever-changing landscape of your Kubernetes cluster.
Kubernetes Event Classifications
In Kubernetes, events play a crucial role by acting as essential indicators, documenting occurrences and transformations within the system. These records offer real-time insights into the health and dynamics of the cluster.
From errors during pod startup to evictions triggered by resource constraints, understanding the significance of various event types is key for effective cluster management and troubleshooting.
1. Failed Events
These events occur when a critical operation or resource allocation within the Kubernetes cluster encounters an error or failure. It signals the potential issues in the cluster, thus failed events are crucial for administrators to swiftly identify and resolve problems.
2. Evicted Events
Evicted events occur when a pod is forcibly removed from a node, typically due to resource scarcity or other operational constraints. Evicted events thus helps to optimize the overall performance of the Kubernetes environment by offering insights into resource allocation challenges.
3. Storage-Specific Events
These events revolve around storage-related incidents, providing information on volume mounting issues or access problems. This events are essential for maintaining data integrity, storage-specific events guide administrators in addressing and resolving storage-related issues effectively.
4. Failed Scheduling Events
Failed scheduling events signify situations where Kubernetes is unable to schedule a pod onto an available node. It offers visibility into scheduling constraints or resource limitations, these events aid in refining the cluster's resource allocation strategy.
5. Volume Events
Volume events capture occurrences such as the creation or deletion of volumes within the Kubernetes cluster. These events are vital for managing data persistence and overseeing storage operations, volume events play a key role in maintaining a robust and reliable storage infrastructure.
6. Node Events
Node events pertain to incidents on individual nodes, encompassing events like node failures or disruptions. Node events are critical for monitoring node health and ensuring the overall stability of the Kubernetes cluster, these events assist administrators in maintaining a resilient and efficient infrastructure.
Important Kubernetes Events
The count and types of events in Kubernetes change dynamically based on the state and activities within your cluster. Now, let's explore a few important Kubernetes events, understanding what each does and how it impacts the cluster.
- PodScheduled: This event occurs when a pod is scheduled to run on a node in the cluster. It indicates the initial placement of the pod.
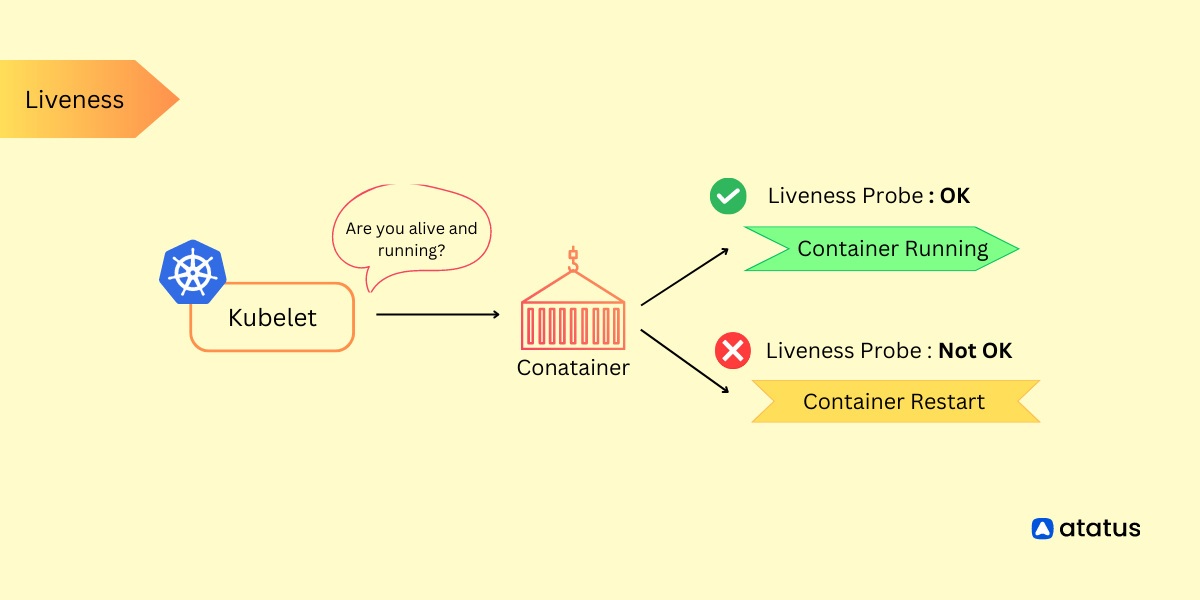
- UnhealthyContainer: Generated when the readiness probe of a container fails, signaling that the container is not in a healthy state.
- NodeNotReady: This event indicate that a node is unavailable for running pods due to underlying issues. This can range from network problems to hardware failures.
- CrashLoopBackOff: This event occurs when a pod repeatedly starts, crashes, restarts, and then crashes again, indicating a persistent issue within the pod.
- FailedScheduling: This event occurs when the Kubernetes scheduler is unable to find a suitable node to run a pod, often due to resource constraints or other scheduling constraints.
- ImagePullBackOff: The ImagePullBackOff event occurs when a node is unable to retrieve the specified container image for a pod, highlighting potential issues with image availability or authentication.
Efficient Filtering of Kubernetes Events
Filtering is the process of selectively extracting or displaying specific information from a larger dataset based on defined criteria. It is essential in computing to help users focus on relevant data, reduce information overload, and improve system performance. By allowing users to customize their view, filtering enhances the user experience and facilitates efficient resource utilization.
Various tools and techniques exist for filtering Kubernetes events within a Kubernetes cluster, and the kubectl command-line tool is one of the many ways to perform this process. The kubectl get events command, along with field selectors, stands out as a common and convenient method for users to filter and view specific events.
1. To list all events
kubectl get events
2. To filter events for a specific namespace
kubectl get events --namespace=<namespace-name>
3. To filter events for a specific resource
kubectl get events --field-selector involvedObject.name=<resource-name>
4. To filter events based on type
kubectl get events --field-selector type=Normal
kubectl get events --field-selector type=Warning
5. To filter events by time
kubectl get events --field-selector lastTimestamp>=<time>
6. Combining multiple filters
kubectl get events --namespace=<namespace-name> --field-selector involvedObject.name=<resource-name>,type=Warning
This approach allows users to customize their queries by specifying criteria such as resource names, namespaces, event types, or time ranges, providing a versatile and accessible means of monitoring and troubleshooting within the Kubernetes environment.
Event Monitoring
Kubernetes events monitoring involves tracking and analysing events within a Kubernetes cluster, such as changes in resource status, pod creations, deletions, or error events. Events are essential for understanding the state and behaviour of the cluster components.
Users benefit from events monitoring as it allows for real-time visibility into cluster activities, aiding in troubleshooting, performance optimization, and proactive issue detection.
By using tools like Kubernetes API or specialized monitoring solutions, users can gain insights into the lifecycle of resources, diagnose problems, and ensure the smooth operation of their containerized applications.
This level of monitoring is crucial for maintaining a resilient and responsive Kubernetes infrastructure.
Conclusion
Kubernetes events are not just records of incidents; they are windows into the inner workings of a dynamic and ever-changing system. Whether it's understanding resource allocation adjustments, troubleshooting critical errors, or monitoring the health of individual nodes, events are indispensable for administrators and developers.
Here are some key takeaways,
- Event Classifications: Understand the significance of event types, from critical errors (failed events) to resource optimization indicators (evicted events).
- Storage and Scheduling Insights: Storage-specific, volume, and node events provide crucial insights into data persistence, storage operations, and node disruptions.
- Efficient Filtering: Master the use of tools like kubectl for efficient event filtering, enabling focused monitoring and troubleshooting.
- Real-time Visibility: Events offer real-time visibility into cluster activities, aiding in proactive issue detection, troubleshooting, and performance optimization.
- Monitoring Tools: Utilize tools like Kubernetes API and monitoring solutions for a comprehensive view of resource lifecycles and effective issue diagnosis.
I hope this quick summary helps you better understand Kubernetes events. Use these insights to improve how you manage and optimize your Kubernetes clusters. Happy orchestrating!
Atatus Kubernetes Monitoring
With Atatus Kubernetes Monitoring, users can gain valuable insights into the health and performance of their Kubernetes clusters and the applications running on them. The platform collects and analyzes metrics, logs, and traces from Kubernetes environments, allowing users to detect issues, troubleshoot problems, and optimize application performance.
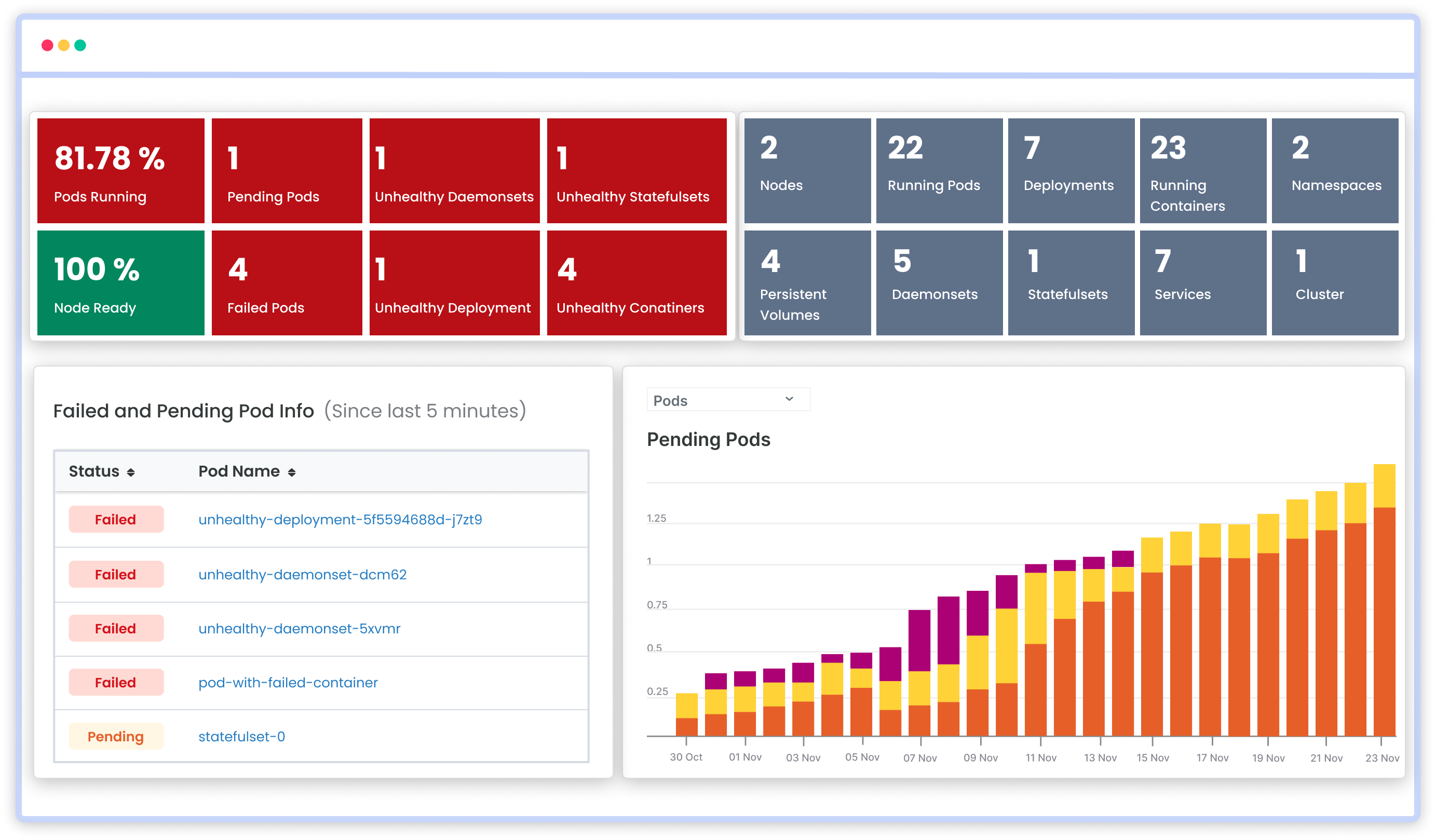
You can easily track the performance of individual Kubernetes containers and pods. This granular level of monitoring helps to pinpoint resource-heavy containers or problematic pods affecting the overall cluster performance.
#1 Solution for Logs, Traces & Metrics
![]() APM
APM
![]() Kubernetes
Kubernetes
![]() Logs
Logs
![]() Synthetics
Synthetics
![]() RUM
RUM
![]() Serverless
Serverless
![]() Security
Security
![]() More
More