Exploring Kubernetes Storage: Persistent Volumes and Persistent Volume Claims
In today's world of container-based applications, the role of storage has become more critical than ever. One of the most significant challenges of containerization is the management of stateful applications.
Kubernetes, one of the popular container orchestration platforms, provides a solution to this problem - Persistent Volumes (PVs). PVs allow the storage provision to be decoupled from the lifecycle of the Pod, making it easier to manage stateful applications.
This enables stateful applications to run on Kubernetes and ensures that data is not lost when pods are terminated or moved. With the increasing adoption of Kubernetes, it is essential to understand how PVs work and how to use them effectively.
In this blog post, we will dive deep into Persistent Volumes (PVs) and explore their features and functionalities.
- What are Kubernetes Persistent Volumes?
- How to Create a Persistent Volume (PV)?
- How to use a Persistent Volume Claim (PVC)?
- How to use the PV and PVC in a Pod?
- Types of Persistent Volumes
- Types of Persistent Volumes Claim
- Applications of Persistent Volumes
Introduction to Kubernetes Storage
Kubernetes storage encompasses the administration and allocation of durable storage resources for applications running on a Kubernetes cluster. Although Kubernetes is optimized for stateless applications that don't preserve data across restarts or rescheduling, real-world scenarios often demand persistent storage.
Applications like databases, file servers, and caching systems necessitate the ability to retain data even when individual containers are terminated or relocated.
To cater to these requirements, Kubernetes provides various storage options and abstractions. Persistent Volumes (PVs) act as representations of physical or cloud-based storage resources that exist independently of pods.
Persistent Volume Claims (PVCs) enable pods to request specific storage resources without direct interaction with the underlying storage infrastructure. Additionally, Storage Classes facilitate dynamic provisioning of PVs based on PVC specifications, streamlining storage allocation and management.
Kubernetes storage capabilities empower developers to deploy stateful applications with data persistence, ensuring data availability and enabling robust backup and recovery strategies.
The versatility of Kubernetes allows it to cater to a wide spectrum of applications, from simple stateless microservices to intricate stateful applications that heavily depend on persistent data storage.
What are Kubernetes Persistent Volumes?
Persistent Volume (PV) in Kubernetes is a cluster-level resource that provides persistent, durable storage for applications running in the cluster. PVs abstract the underlying storage infrastructure and provide a consistent API for applications to consume storage without worrying about the implementation details.
In Kubernetes, containers and pods are ephemeral by nature. When a pod restart or gets rescheduled, the data stored within it is typically lost. However, some applications require persistent storage that survives across pod restarts and rescheduling. This is where Persistent Volumes come into play.
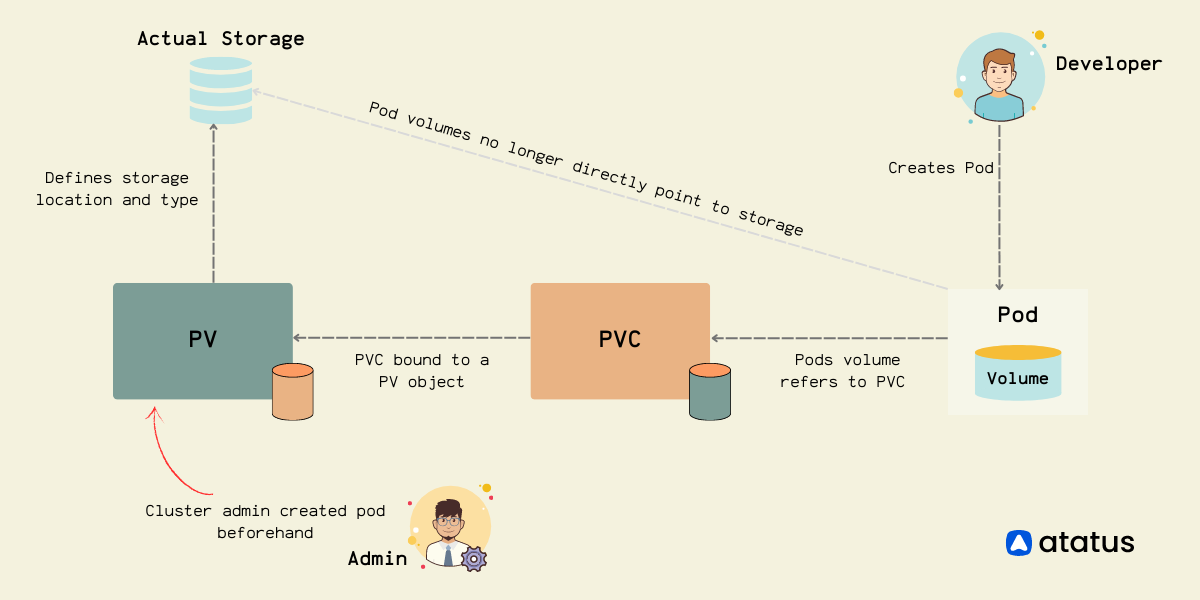
In the above image, the Kubernetes Admin creates a Persistent Volume (PV). Subsequently, the Developer creates a Persistent Volume Claim (PVC) to request storage and bind it to the PV. Finally, the Developer configures a Pod to utilize the PV, satisfying the claim made by the PVC.
Persistent Volume is a representation of a physical storage resource in the cluster, such as a disk, network-attached storage (NAS), or a cloud storage volume. It decouples the storage from the lifecycle of pods and allows the storage to persist independently.
PVs have the following key characteristics:
- Lifecycle Management: PVs have a lifecycle independent of the pods that use them. They can be provisioned, attached to pods, and later released.
- Capacity and Access Modes: PVs have a specified capacity that determines the maximum amount of data that can be stored. They also have access modes that define how the storage can be accessed, such as ReadWriteOnce (RWX), ReadOnlyMany (ROX), and ReadWriteMany (RWX).
- Storage Classes: PVs can be provisioned statically by an administrator or dynamically using Storage Classes. Storage Classes define the properties of the underlying storage and can be used to dynamically provision PVs based on the requested storage class.
- Reclaim Policies: When a PV is released, it goes through a reclaim policy that determines whether the data should be retained, deleted, or recycled. The reclaim policy is specified when creating the PV and can be set to Retain, Delete, or Recycle.
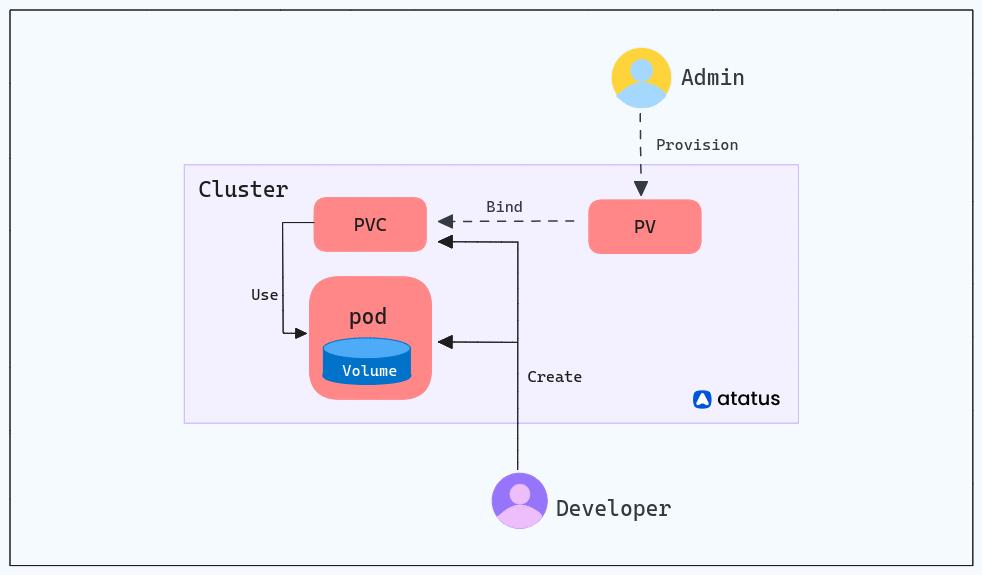
- Binding with Persistent Volume Claims (PVCs): To consume a PV, a user or application needs to create a Persistent Volume Claim (PVC) that specifies the desired capacity, access modes, and other requirements. The PVC acts as a request for storage, and Kubernetes matches it with an appropriate PV based on the criteria specified in the PVC.
By decoupling storage from individual pods, PVs enable data persistence and provide a scalable and flexible solution for managing storage in Kubernetes clusters.
What are Kubernetes Persistent Volumes Claim?
PVCs, or Persistent Volume Claims, are a core feature in Kubernetes that enable applications to request and use persistent storage resources in a cluster. They serve as a way for pods to declare their need for persistent storage without having to worry about the underlying storage details.
When a pod needs persistent storage to store data beyond its lifecycle, it creates a PVC with specific storage requirements, such as the desired capacity and access modes. The PVC represents a claim for storage, and Kubernetes attempts to find an appropriate Persistent Volume (PV) that matches the PVC's specifications.
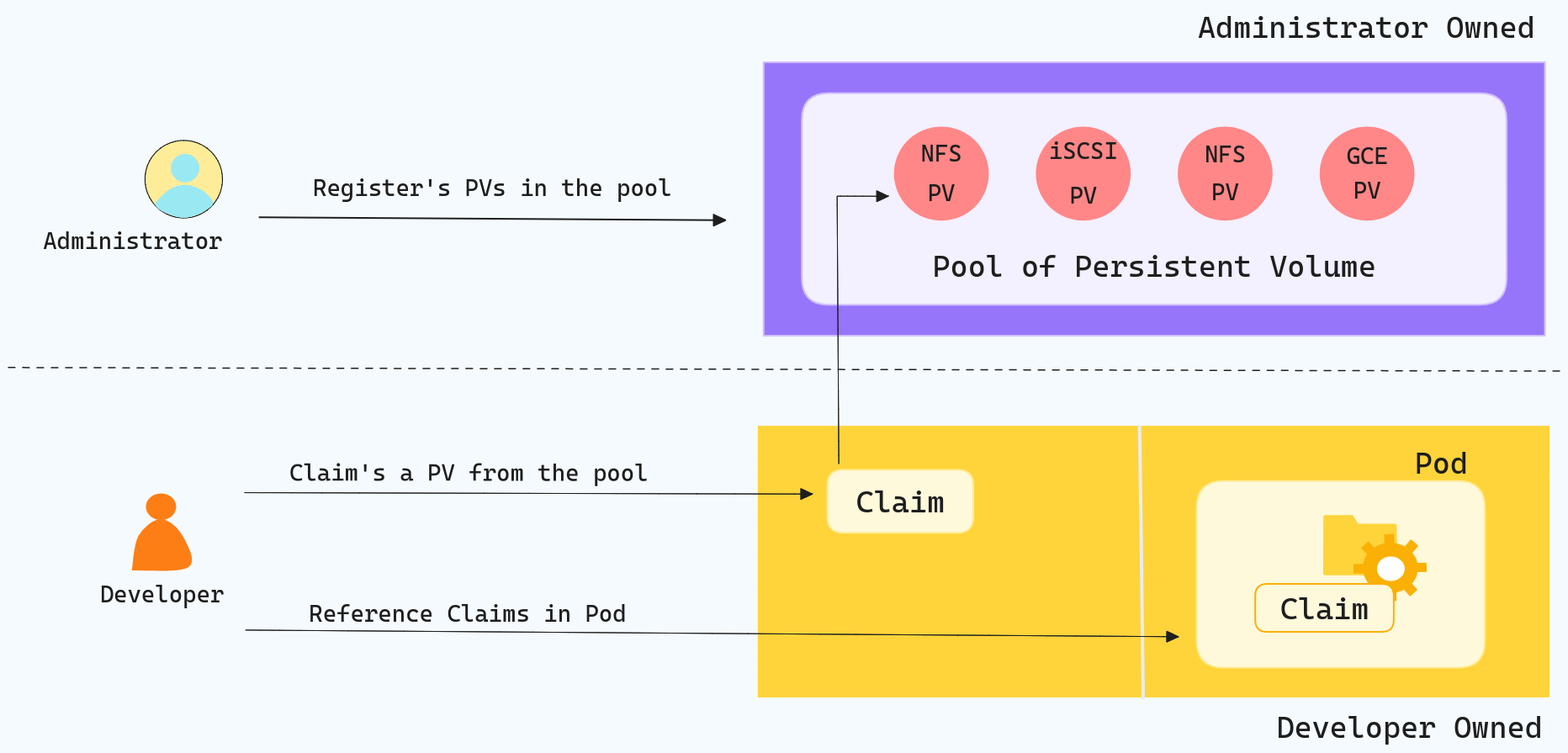
Key points about PVCs include:
- Abstraction Layer: PVCs abstract the process of provisioning storage resources from the pod's perspective. The pod only needs to specify its storage requirements in the form of a PVC, leaving the actual binding and provisioning of the storage to the Kubernetes system.
- Dynamic Provisioning: PVCs support dynamic provisioning, meaning that if no suitable PV is available to fulfill the claim, Kubernetes can automatically create a new PV that meets the PVC's specifications. This is made possible by using Storage Classes, which define the type of storage backend and provisioner to use for dynamic PV creation.
- Reusability: PVCs are not tied to specific pods or applications. Once created, a PVC can be used by multiple pods, enabling data sharing and making storage resources more efficient and reusable.
- Stateful Applications: PVCs are particularly valuable for stateful applications, such as databases, where data persistence is critical. Stateful applications can use PVCs to request persistent storage that remains available even if the application is moved or rescheduled.
Overall, PVCs provide a flexible and portable way to manage storage needs in Kubernetes, making it easier to allocate and manage persistent storage resources for various applications running in the cluster.
How to Create a Persistent Volume (PV)?
To create a Persistent Volume, you need to define a PV manifest in a YAML file and create it to your Kubernetes cluster using the kubectl create or kubectl apply command.
Here's an example of a PV manifest:
apiVersion: v1
kind: PersistentVolume
metadata:
name: my-pv
spec:
capacity:
storage: 10Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
storageClassName: standard
hostPath:
path: /path/to/host/folder
In the above YAML file:
namespecifies the name of the PV.capacitydefines the size of the storage volume.accessModesspecify how the PV can be accessed (e.g., ReadWriteOnce, ReadOnlyMany, ReadWriteMany).persistentVolumeReclaimPolicydetermines what happens to the PV's data when it's released by the application (e.g., Retain, Recycle, Delete).storageClassNamespecifies the storage class to use for dynamic provisioning (optional).hostPathis a type of PV that uses a directory on the host machine's filesystem.
To create the Persistent Volume based on the YAML file provided, execute the following command:
kubectl apply -f pv.yamlThis command will apply the configuration defined in the "pv.yaml" file and create the Persistent Volume in your Kubernetes cluster.
To list the Persistent Volumes (PVs) in your Kubernetes cluster, use the following command:
kubectl get pvExecuting this command will display a list of all the Persistent Volumes along with their respective details, such as name, capacity, access modes, reclaim policy, and status. This information will help you monitor and manage the available persistent storage resources in your Kubernetes cluster.
To apply or update the configuration specified in the pv.yaml file
kubectl apply -f pv.yamlThis command is used for creating or updating resources in the cluster. If the PV defined in pv.yaml already exists, kubectl apply will update the PV to match the specifications in the YAML file. If the PV does not exist, it will create a new PV.
Hence, both kubectl apply -f pv.yaml and kubectl create -f pv.yaml commands are used to apply the configuration specified in the pv.yaml file to your Kubernetes cluster.
How to use a Persistent Volume Claim (PVC)?
Persistent Volume Claim (PVC) is a request for storage made by an application to consume a PV. PVCs are bound to PVs based on their matching access modes, storage class, and capacity requirements.
Here's an example PVC manifest:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: my-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi
storageClassName: standardIn this example:
namespecifies the name of the PVC.accessModesdefine the desired access mode(s) for the PVC.resources.requests.storagespecifies the minimum required storage size.storageClassNamematches the PVC with a PV based on the storage class (optional).
Here are some frequently used kubectl commands for managing Persistent Volume Claims (PVCs) in Kubernetes:
i.) Once you have the PVC manifest defined, you can apply it using the following command:
kubectl apply -f pvc.yaml
ii.) To list all PVCs in your cluster, use the following command:
kubectl get pvciii.) To get detailed information about a specific PVC, use the following command:
kubectl describe pvc <pvc_name>iv.) To delete a PVC, use the following command:
kubectl delete pvc <pvc_name>v.) To edit the specifications of a PVC, use the following command. This will open the PVC's YAML file in your default text editor:
kubectl edit pvc <pvc_name>vi.) To retrieve the YAML definition of a PVC, use the following command:
kubectl get pvc <pvc_name> -o yamlvii.) To list PVCs in a specific namespace, use the following command:
kubectl get pvc -n <namespace>These commands will help you create, manage, and get information about Persistent Volume Claims in your Kubernetes cluster. Remember to replace <pvc_name> and <namespace> with the actual name of the PVC and the namespace you want to work with, respectively.
How to use the PV and PVC in a Pod?
To use the PV and PVC in a pod, you need to define a pod manifest that references the PVC. Here's an example pod manifest:
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
volumes:
- name: my-volume
persistentVolumeClaim:
claimName: my-pvc
containers:
- name: my-container
image: nginx
volumeMounts:
- name: my-volume
mountPath: /dataIn the above example:
volumesdefine the volumes available to the pod.persistentVolumeClaimreferences the PVC name.containersdefine the pod's containers.volumeMountsspecify the volume mounts within the containers.
Once you have the pod manifest defined, you can apply it using the following command:
kubectl apply -f pod.yamlThe pod will be scheduled on a node, and the PV will be bound to the PVC, providing persistent storage to the application running in the pod.
That's a basic overview of Kubernetes Persistent Volumes (PVs) and how to use them with Persistent Volume Claims (PVCs). There are other types of PVs available, such as network-based storage or cloud provider-specific options, but the concepts remain similar.
Types of Persistent Volumes
In Kubernetes, there are different types of Persistent Volumes (PVs) available to cater to various storage requirements. The types of PVs are determined by the storage backend and the access modes they support. Here are some commonly used types of PVs:
1. HostPath
HostPath PVs use a directory on the host node's filesystem as the storage source. They are primarily intended for development and testing purposes and not recommended for production deployments. HostPath PVs provide a simple way to expose local storage to containers running on the same node.
apiVersion: v1
kind: PersistentVolume
metadata:
name: hostpath-pv
spec:
capacity:
storage: 5Gi
accessModes:
- ReadWriteOnce
hostPath:
path: /path/to/host/directoryThis PV is using the HostPath volume type, where the storage is a directory on the host node's filesystem (/path/to/host/directory). The capacity is set to 5 gigabytes (5Gi), and the access mode allows read-write access from a single node (ReadWriteOnce).
2. Local
Local PVs are similar to HostPath PVs but with some additional capabilities. They allow you to specify storage devices or directories on a node and use them as persistent storage. Local PVs can be manually provisioned or dynamically provisioned using the local storage class.
apiVersion: v1
kind: PersistentVolume
metadata:
name: local-pv
spec:
capacity:
storage: 50Gi
accessModes:
- ReadWriteOnce
local:
path: /path/to/local/directory
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- node1This PV demonstrates the use of the Local volume type, which allows you to specify a local path on the host node as the storage source. Let's go through the key components:
- The capacity section defines the storage capacity of the PV, set to 50 gigabytes (50Gi).
- The
accessModesfield specifies the access mode for the PV. In this example, it is set to ReadWriteOnce, allowing read-write access from a single node. - The local section specifies the path to the local directory on the node
(/path/to/local/directory)that will be used as the persistent storage. - The nodeAffinity section enables node affinity for the PV. In this case, it specifies that the PV should be bound to nodes that match the given node selector. The example shows that the PV should be bound to nodes with the label
kubernetes.io/hostnameset to node1.
3. NFS
Network File System (NFS) PVs use a network-based file system to provide persistent storage across multiple pods and nodes. NFS PVs are commonly used for file sharing and allow multiple pods to access the same storage simultaneously.
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfs-pv
spec:
capacity:
storage: 10Gi
accessModes:
- ReadWriteMany
nfs:
server: nfs-server.example.com
path: /exported/pathThis PV uses the NFS volume type, which provides network-based file system storage. The storage capacity is set to 10 gigabytes (10Gi), and the access mode allows multiple nodes to have read-write access (ReadWriteMany).
The server field specifies the NFS server's hostname (nfs-server.example.com), and the path field indicates the exported path on the NFS server (/exported/path).
4. AWS Elastic Block Store (EBS)
EBS PVs are backed by Amazon Web Services (AWS) Elastic Block Store volumes. They provide persistent block-level storage for applications running on Kubernetes clusters hosted on AWS. EBS PVs are commonly used in AWS environments to store data reliably.
apiVersion: v1
kind: PersistentVolume
metadata:
name: ebs-pv
spec:
capacity:
storage: 20Gi
accessModes:
- ReadWriteOnce
awsElasticBlockStore:
volumeID: <EBS_VOLUME_ID>
fsType: ext4This PV is using the AWS Elastic Block Store (EBS) volume type. The storage capacity is set to 20 gigabytes (20Gi), and the access mode allows read-write access from a single node (ReadWriteOnce). The volumeID field should be replaced with the actual ID of the EBS volume to be used. The fsType field specifies the file system type to be used (ext4 in this example).
5. Azure Disk
Azure Disk PVs are backed by Azure Managed Disks and provide persistent block storage for applications running on Azure Kubernetes Service (AKS). Azure Disk PVs are suitable for storing data in Azure environments and offer different performance tiers.
apiVersion: v1
kind: PersistentVolume
metadata:
name: azure-disk-pv
spec:
capacity:
storage: 30Gi
accessModes:
- ReadWriteOnce
azureDisk:
diskName: <AZURE_DISK_NAME>
diskURI: <AZURE_DISK_URI>This PV utilizes the Azure Disk volume type. The storage capacity is set to 30 gigabytes (30Gi), and the access mode allows read-write access from a single node (ReadWriteOnce). The diskName and diskURI fields should be replaced with the actual name and URI of the Azure Disk to be used.
6. Google Persistent Disk (GPD)
GPD PVs are backed by Google Cloud Persistent Disks and provide persistent block storage for applications running on Google Kubernetes Engine (GKE). GPD PVs offer different performance classes and are suitable for storing data in Google Cloud environments.
apiVersion: v1
kind: PersistentVolume
metadata:
name: gpd-pv
spec:
capacity:
storage: 40Gi
accessModes:
- ReadWriteOnce
gcePersistentDisk:
pdName: <GPD_NAME>
fsType: ext47. CSI Drivers
Container Storage Interface (CSI) drivers allow integration with third-party storage providers. CSI PVs enable the use of storage systems and vendors beyond the built-in PV types. Various storage vendors provide CSI drivers to connect their storage systems with Kubernetes clusters.
apiVersion: v1
kind: PersistentVolume
metadata:
name: csi-pv
spec:
capacity:
storage: 50Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
csi:
driver: my-csi-driver
volumeHandle: my-volume-handle
fsType: ext4The CSI field in the PV specification indicates the usage of a CSI driver. driver specifies the name or identifier of the CSI driver to be used. volumeHandle represents a unique identifier or reference to the specific storage resource managed by the CSI driver. fsType is an optional field that specifies the desired file system type for the PV.
Types of Persistent Volumes Claim
In Kubernetes, Persistent Volume Claims (PVCs) can specify different access modes, which determine how the underlying Persistent Volume (PV) can be accessed and utilized by pods. There are three types of access modes available for PVCs:
1. ReadWriteOnce (RWO)
RWO allows the PVC to be mounted as read-write by a single node (pod) at a time. This mode suits scenarios where only one pod needs both read and write access to the storage simultaneously.
Example: A database pod that requires read-write access to its data from a single node.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: my-rwo-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi2. ReadOnlyMany (ROX)
ROX allows the PVC to be mounted as read-only by multiple nodes (pods) simultaneously. It is useful when multiple pods need read-only access to the same data without requiring write access.
Example: A pod serving static content like images or CSS files that are accessed by multiple pods in read-only mode.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: my-rox-pvc
spec:
accessModes:
- ReadOnlyMany
resources:
requests:
storage: 10Gi3. ReadWriteMany (RWX)
RWX enables the PVC to be mounted as read-write by multiple nodes (pods) simultaneously. This mode is used when multiple pods require both read and write access to the same data concurrently.
Note: Not all storage backends support RWX, so its availability may vary depending on the storage provider.
Example: Multiple web servers accessing shared configuration files in read-write mode.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: my-rwx-pvc
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 20GiApplications of Persistent Volumes
Persistent Volumes (PVs) in Kubernetes are versatile and can be used in various use cases where persistent storage is required for applications. Here are some common use cases for Persistent Volumes:
- Database Storage: PVs are commonly used to provide persistent storage for databases such as MySQL, PostgreSQL, MongoDB, and others. Databases require durable storage to store data reliably and ensure data integrity even if the application or pod restarts or migrates to different nodes.
- File Sharing and Storage: PVs can be utilized for file sharing and storage scenarios. They can serve as shared network storage for multiple pods or applications, allowing them to access and share files. Network File System (NFS) is often used as a PV type for file sharing.
- Content Management Systems: Content Management Systems (CMS) like WordPress or Drupal often require persistent storage for media files, themes, plugins, and other assets. PVs can provide the required storage to ensure that the content remains available even if the pods or containers are restarted or redeployed.
- Logging and Monitoring: Applications generate logs and metrics that need to be stored persistently for analysis, troubleshooting, and compliance. PVs can be used to store log files and metric data generated by logging and monitoring systems such as Atatus, Elasticsearch, Prometheus, or Fluentd.
- Data Processing and Analytics: Big data processing and analytics workloads often require storage for large datasets. PVs can be used to store input data, intermediate results, and output data for distributed data processing frameworks like Apache Hadoop, Apache Spark, or Apache Flink.
- Backup and Disaster Recovery: PVs can be used for backup and disaster recovery purposes. Applications can write data to PVs, and backup tools or processes can then take periodic snapshots or replicate the data to remote storage for disaster recovery scenarios.
- Machine Learning and AI Workloads: Machine learning and AI applications require persistent storage to store training datasets, model checkpoints, and intermediate results. PVs can provide the required storage capacity and ensure data availability across multiple training or inference runs.
- Stateful Applications: Any application that requires a persistent state, such as caching systems, message queues, or session stores, can benefit from PVs. PVs ensure that the state is preserved even if the application is restarted or moved to different nodes.
These are just a few examples of how Persistent Volumes can be used in Kubernetes. The flexibility and abstraction provided by PVs allow applications to work with persistent data reliably and independently of the underlying infrastructure.
Conclusion
Persistent Volumes (PVs) in Kubernetes offer a versatile and independent lifecycle, allowing provisioning, attachment to pods, and later release. They define storage capacity and access modes, making them suitable for various use cases such as databases, file sharing, logging, and machine learning.
PVs can be provisioned statically by administrators or dynamically using Storage Classes, with reclaim policies determining their fate upon release.
Different PV types like HostPath, NFS, AWS EBS, Azure Disk, Google Persistent Disk, and CSI Drivers cater to diverse storage requirements.
However, availability depends on the underlying infrastructure and cluster configuration. Custom storage solutions using the CSI framework can also be developed.
When working with PVs, consider factors like scalability, performance, durability, and access modes to meet your application's specific needs. Remember to consult documentation for detailed instructions and configurations, depending on the storage system or cloud provider you're using.
Atatus Kubernetes Monitoring
With Atatus Kubernetes Monitoring, users can gain valuable insights into the health and performance of their Kubernetes clusters and the applications running on them. The platform collects and analyzes metrics, logs, and traces from Kubernetes environments, allowing users to detect issues, troubleshoot problems, and optimize application performance.
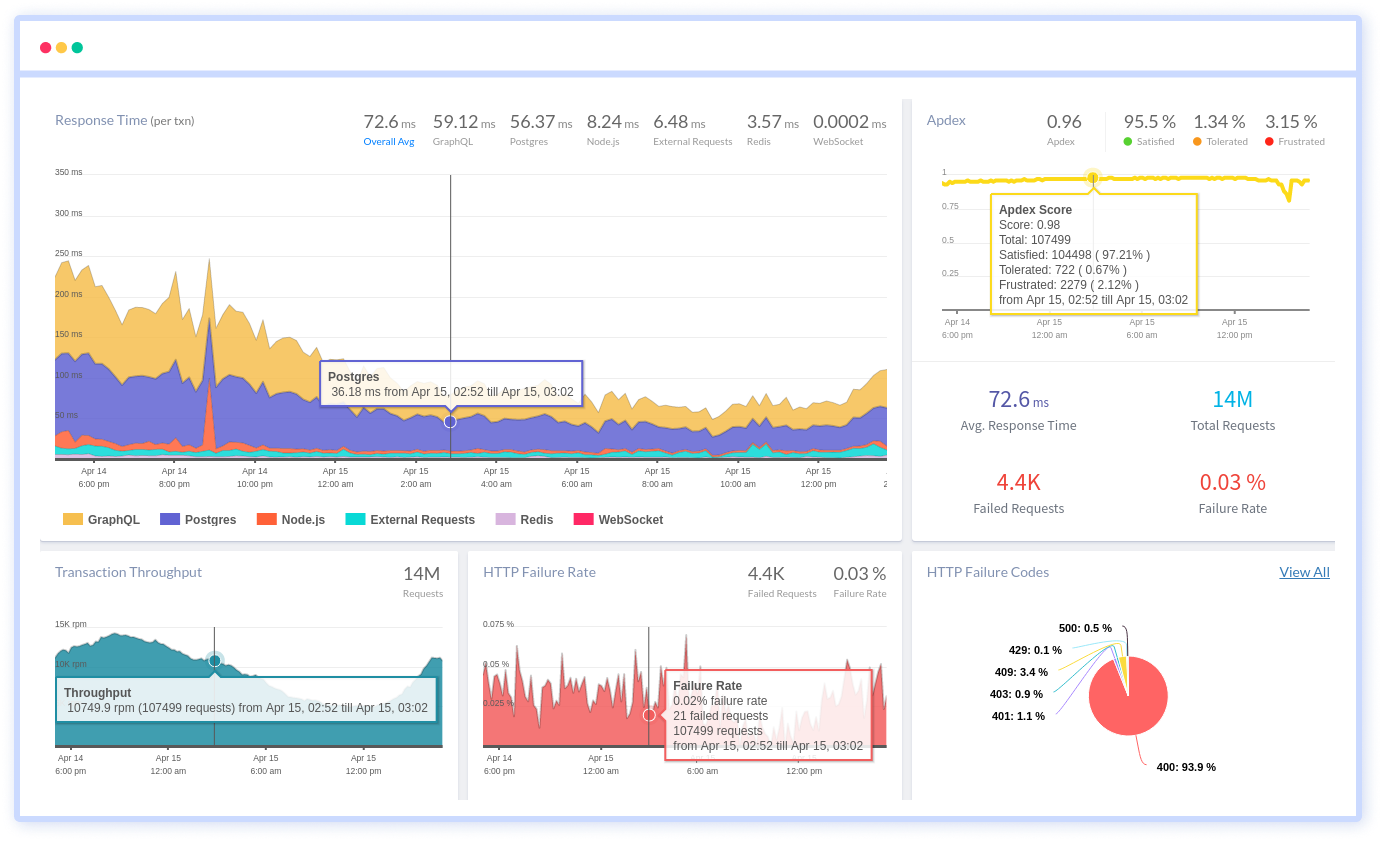
You can easily track the performance of individual Kubernetes containers and pods. This granular level of monitoring helps to pinpoint resource-heavy containers or problematic pods affecting the overall cluster performance.
#1 Solution for Logs, Traces & Metrics
![]() APM
APM
![]() Kubernetes
Kubernetes
![]() Logs
Logs
![]() Synthetics
Synthetics
![]() RUM
RUM
![]() Serverless
Serverless
![]() Security
Security
![]() More
More