
People often get confused between Monitoring and Observability and use them interchangeably in the DevOps field. But they are two very unique concepts. Since we work in this sphere, I thought it was ideal to clear up this confusion and give you the right information on it.
With most of the application software now adopting several microservices and going for distributed architecture, the need to have a complete overview of your system cannot be understated. This is where the terms “Monitoring” and “Observability” come into play.
In this blog, we will take a look at:
- What is Monitoring?
- Why is Monitoring alone Insufficient in this Modern era?
- What is Observability?
- Three Pillars of Observability
- Observability vs. Monitoring: What's the difference?
- Observability vs. Monitoring: What are the Similarities?
- Monitoring and Observability: Which is Better?
- Monitoring vs. Observability: Comparison
- Related Terms
What is Monitoring?
Monitoring is the process of collecting data from an application. It involves monitoring several components of your system, such as application metrics or assessing CPU usage, network traffic, or application response times.
In simpler words, monitoring is what you do when you instrument your application or hardware to collect some data. The output of such a collection would be quantifiable values on how different aspects of your application or features are performing. For example, if you’re monitoring your infrastructure, then you would want to look into the condition of your host CPU, memory usage, I/O wait time, etc.
DevOps monitoring covers the full software development lifecycle. It is closely linked with other IT service management (ITSM) functions including incident management, availability, capacity, and performance management.
Monitoring is a very generic term and it can be further divided into the following:
- Infrastructure Monitoring
- Application Performance Monitoring
- Network Monitoring
- Synthetic and Real User Monitoring
- Cloud Monitoring
- Container Monitoring
- Database Monitoring
- Security Monitoring
Monitoring is generally bound by time, i.e., metrics are always calculated over a predefined time period because only then can we analyze and find trends, anomalies and other potential issues.
- Keep real-time oversight of system health and metrics.
- Collection metrics involves those that directly affect the performance of applications.
- Alerts go off when the set threshold limit is breached. You can set these limits according to use case.
- Allows you to identify the cause of error quite early on. So you can keep an eye on them before the issue escalates.
- Optimize system performance, keeping these metrics in mind.
Monitoring Goals
1. High Application Availability:
A monitoring setup's primary goal is to ensure maximum availability and uptime, that the application is available for as long as feasible.
Two key metrics to quantify an application's reliability are Time to Detect (TTD) and Time to Mitigate (TTM). TTD is used to determine how quickly bugs in an application are reported to the appropriate team.
TTM indicates how quickly the team can respond to an issue and restore normalcy. While the TTM metric is dependent on the issue as well as the DevOps team's capabilities, a robust monitoring setup may assure good TTD values, reducing the amount of time it takes to complete the process.
2. Analysis of Usage Validates Learning:
Product teams can benefit greatly from application usage statistics. While a user can post a descriptive review of your app whenever they want, their usage statistics may give you a better idea of how well they've been able to use it.
Similarly, by examining changes in usage statistics, monitoring tools can be made smart enough to validate changes in performance across various deployments. If an update results in a reduced usage trend in the feature addressed by the update, this is an obvious red flag that the product team should address.
Why is Monitoring alone insufficient in Modern times?
Technology space has evolved and is teeming with up-and-coming solutions that cater to even the most atypical problems. At this time, if we rely only on Monitoring, we are losing out on so many things.
Consider these cases:

i.) Limited Visibility
The first big problem comes with correlating metrics collected from one product with another on the same stack. If you can’t compare the data across different platforms, how are you going to see its effects on the related components. Imagine a web application that's experiencing intermittent slowdowns during peak usage hours. Monitoring metrics like CPU usage and network traffic might show spikes during these periods, indicating a potential issue. However, without additional context from logs or traces, it's challenging to pinpoint the exact cause.
ii.) Complexity of Distributed Architecture
Since most of the applications are now made of distributed microservices, we need to ensure proper communication between these. For example, if an e-commerce platform suddenly experiences errors in its checkout process, monitoring is of not much help here. But if you had the option of request tracing, you could have identified the origin of this error.
iii.) Adjusting to Dynamic Environments
Consider this scenario of an organization frequently updating its containerized applications running on a Kubernetes cluster. Monitoring tools track resource utilization metrics like CPU and memory usage, but they don't automatically adjust their monitoring configurations when new containers are deployed or scaled up/down. As a result, the operations team may miss critical performance issues or resource constraints in newly deployed containers.
iv.) Requirements Beyond Just Metrics
For example, take a financial services company whose trading platform experiences intermittent outages during peak trading hours. Monitoring tools generate alerts when the platform becomes unavailable, but the operations team struggles to diagnose the underlying cause. Without access to detailed transaction logs or request traces, they can't determine whether the outages are due to a database deadlock, network latency issues, or third-party API failures.
These examples demonstrate how observability complements monitoring by providing richer insights and context, enabling organizations to better understand and troubleshoot issues in modern IT environments.
What is Observability?
“Observability wouldn’t be possible without monitoring.”
Observability expands upon the concept of monitoring by emphasizing a deeper understanding of system behavior through comprehensive data collection, analysis, and contextual insights. While monitoring primarily focuses on predefined metrics and thresholds, observability seeks to provide visibility into the internal workings of complex systems, enabling organizations to answer questions about why things are happening the way they are.
Observability is important because it gives you performance-focused insights, more control, and is crucial for understanding complex IT systems. It provides performance insights, more control, and helps diagnose issues quickly. With comprehensive data analysis, it provides valuable insights to improve system performance and reduce downtime and understanding of complex modern IT systems.
- Data collection goes beyond metrics. Logs, traces, and events are included.
- Correlates data from diverse sources and provides a complete picture of what’s happening in your system.
- Highly efficient in analyzing root causes of spontaneous errors.
- Offers continuous monitoring and regular alerting to keep applications updated and error free.
- Analyze trends and make necessary changes, also helpful for proactive management.
The Three Pillars of Observability
When we talk of observability, three pillars basically capture the entire essence of it. These are logs, metrics and traces.
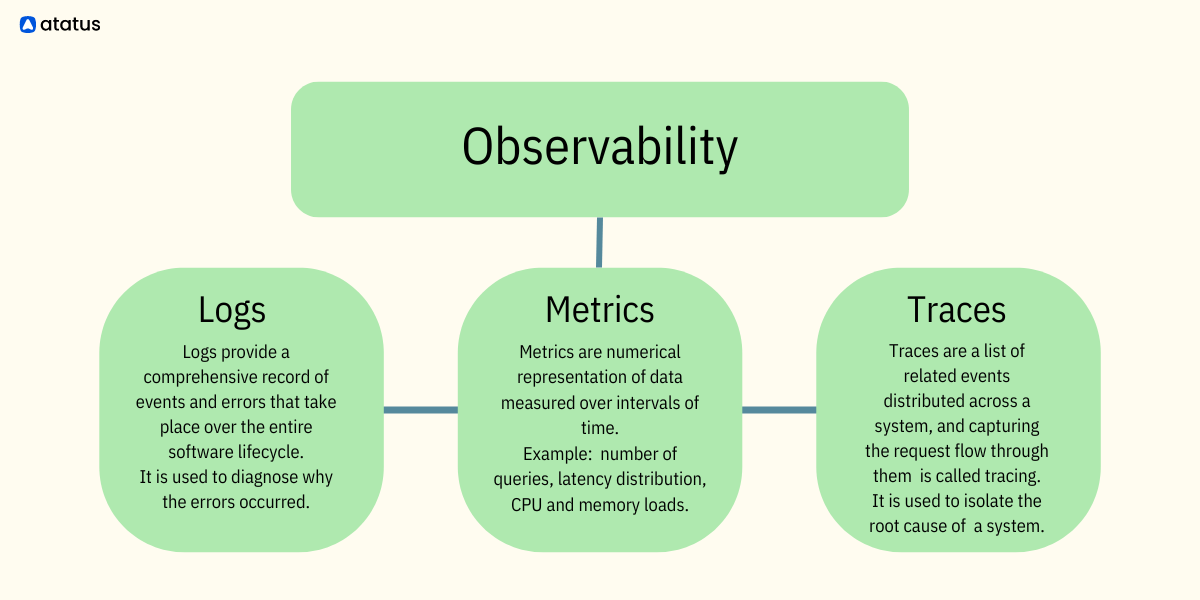
Logs
Logs consist of detailed records of events, activities, and transactions occurring within a system. They capture valuable information such as user interactions, system errors, application events, and infrastructure changes. Logs serve as a chronological record of system activity, enabling developers and operators to troubleshoot issues, trace the root cause of problems, and gain visibility into the inner workings of the system.
Metrics
Metrics are quantitative measurements that track the performance and behavior of a system over time. These measurements include key performance indicators (KPIs), such as response times, error rates, and resource utilization. Metrics help identify deviations from expected behavior. Metrics are quantifiable data of how a system or software works. This can include response time, error rates, throughput, and resource utilization. Metrics help in understanding the overall health and efficiency of a system by providing objective indicators of its performance.
Traces
Tracing involves following the flow of requests or transactions as they traverse through a distributed system. Traces provide visibility into the end-to-end journey of a request, highlighting dependencies, latency, and potential bottlenecks. By correlating traces with logs and metrics, organizations can gain a holistic understanding of system interactions and diagnose complex issues more effectively.
Observability vs. Monitoring: What are the Differences?
While monitoring and observability share the common goal of ensuring the reliability and performance of systems, they differ in their approach and scope.
Monitoring relies on predefined metrics and thresholds to track system health and detect deviations from expected behavior, whereas observability goes beyond this by providing a more comprehensive view of system behavior through the collection of diverse, contextual data. Monitoring is well-suited for detecting known issues or patterns based on predefined metrics, while observability excels in uncovering insights and diagnosing issues that may not be captured by traditional monitoring alone.
Observability vs. Monitoring: What are the Similarities?
Both Monitoring and Observability aim to inform about system health and behaviour. While monitoring focuses on the metrics alone, observability goes a step further and includes details about where these metrics occurred and how they affect other components of the system.
They aim to generate insights into system health, performance, and reliability, aiding in issue detection and operational support. While monitoring alerts operators based on predefined thresholds, observability offers deeper insights into system behavior, enabling operators to identify root causes of issues and optimize performance. By integrating both practices, organizations can achieve a comprehensive approach to system management, ensuring operational excellence and addressing a wide range of operational challenges effectively.
Monitoring vs. Observability: Comparison
| Aspect | Monitoring | Observability |
|---|---|---|
| Focus | Tracks predefined metrics and thresholds. | Provides insights into system behavior and why it occurs. |
| Data Collection | Collects specific metrics (CPU, memory, etc.). | Gathers diverse data (metrics, logs, traces, events). |
| Depth of Insights | Offers surface-level insights into system health. | Provides deep insights with contextual understanding. |
| Reactive vs Proactive | Reactive; alerts triggered based on predefined thresholds. | Proactive; enables understanding of system behavior to prevent issues. |
| Complexity Handling | Handles simple metrics monitoring. | Handles complex distributed architectures effectively. |
| Root Cause Analysis | Limited ability to pinpoint root causes of issues. | Facilitates root cause analysis with comprehensive data. |
| Adaptability | May struggle to adapt to dynamic environments. | Adapts well to changes in system architecture and scale. |
| Use Cases | Basic system health monitoring. | Troubleshooting, debugging, performance optimization. |
Monitoring and Observability: Which is Better?
Having read this far, you might have doubts as to what to implement and which is better?
Typically, monitoring offers a condensed picture of the system data that is centered on specific metrics. When system failure modes are well understood, this strategy is enough.
Monitoring indicates system performance because it concentrates on important metrics like utilization rates and throughput. For example, you might want to keep track of any latency when writing data to the disk or the typical query response time when monitoring a database. Database administrators with experience can recognize patterns that may indicate recurring issues.
Examples include a rise in CPU usage, a decline in the cache hit ratio, or a surge in memory usage. These problems can be a sign of a badly worded query that needs to be stopped and looked at.
However, when compared to troubleshooting microservice systems with several components and a variety of dependencies, conventional database performance analysis is simple. Understanding system failure modes are useful for monitoring, but as applications become more complicated, so do their failure modes. Often, the way that distributed applications will fail cannot be predicted.
Making a system observable allows you to comprehend its internal state and, from there, identify what is malfunctioning and why.
However, in contemporary applications, correlations between a few metrics are frequently insufficient to diagnose events. Instead, these contemporary, complicated applications demand a greater level of system state visibility, which you can achieve by combining observability with more potent monitoring tools.
Use Monitoring When:
- Your application architecture is relatively simple, with predictable failure modes.
- You need to monitor specific metrics to track system performance and health.
- You want to identify trends, anomalies, and performance bottlenecks based on predefined metrics.
Use Observability When:
- You operate in a complex, distributed environment with numerous interconnected components and dependencies.
- Failure modes are unpredictable, and traditional monitoring may not provide sufficient insights.
- You need deeper visibility into the internal state and behavior of each component to diagnose issues effectively.
- You want to correlate metrics from different platforms and see how they reflect in each components performance.
Related Terms
Some terms related to Observability and Monitoring include:
Telemetry
Telemetry is the process of collecting raw data from a system and passing it onto a monitoring solution. This data often includes information about the performance, behavior, and status of various components within a system or network.
Telemetric data on its own is of no use; only when a monitoring or observability tool analyzes it does it provide value to the user.
Application Performance Monitoring (APM)
APM is a subset of both Monitoring and Observability. There are several types of monitoring, one of which is APM. APM focuses only on what happens within an application (for example, if you have an APM tool, it will not assess whether your servers are running properly!).
It monitors application-specific metrics, such as response times, transaction throughput, error rates, database queries, and user session metrics, which are closely related to making better user experiences.
Learn more about Application Performance Monitoring here.
Logs Monitoring
Logs monitoring involves the systematic tracking and analysis of logs generated by various systems, applications, networks, and devices within an organization's IT infrastructure. Logs contain all details about any event happening within your system - be it errors, crashes, malware or other security breaches. Log data is then aggregated into a centralized repository or database where it can be easily accessed and analyzed. This aggregation helps in correlating data from different sources and identifying patterns or anomalies.
Logs Monitoring typically follows this pattern:
Collection > Aggregation > Analysis > Alerting > Reporting
Visualizing log data makes it easier to comprehend the overall system performance and you can easily identify what to tweak and where. That is why Logs Monitoring solutions with an inclusive visualization capability are a big hit among developers.
Discover Atatus' Logs Monitoring Platform for an idea of how this exactly works.
Atatus: All in One Observability Platform
Atatus offers a comprehensive suite of products for logs monitoring, tracing, and metric collection, empowering you to gain deep insights into your applications' behavior, diagnose issues faster, and optimize performance with ease.
Atatus offers a Logs Monitoring solution, as a fully managed cloud service with minimal setup. It monitors logs from all of your systems and applications into a centralized and easy-to-navigate user interface. You can then search the logs by hostname, service, source, messages, and correlate log events with APM to identify slow traces and errors, to have a complete view of your application software.
Monitor CPU usage, memory consumption, request throughput, and custom business metrics in real-time, and stay ahead of potential issues with our curated Metric collection, be it within applications, or on infrastructure, or databases.
Along with Logs and Metrics, visualize end-to-end request flows, identify latency issues, and optimize critical paths across your distributed architecture with Atatus Tracing and pinpoint performance bottlenecks with precision.



