Redis Tutorial: Exploring Data Types, Architecture, and Key Features
In today's digital landscape, data reigns supreme, shaping every facet of modern life. From personal pursuits to corporate endeavors, data's significance is undeniable. Its pivotal role spans industries, driving informed decisions and fueling efficient operations.
Businesses harness data's power to decipher trends, understand customers, and adapt strategies. Effective data management, epitomized by Database Management Systems (DBMS), is essential. DBMS acts as a digital organizer, streamlining data storage, retrieval, and security.
Redis, a dynamic DBMS, stands out with its distinct features. In this Redis tutorial, we'll delve into its data types, architecture, and key attributes, unlocking insights into this powerful tool.
Table of Content
- Introduction - In-memory Database
- Differences between Redis and other Databases
- What is Redis?
- Features of Redis
- Redis Data Structures
- What is Redis Stack?
- Architecture of Redis
- Persistence Model in Redis
- Drawbacks of Redis
- Use Cases of Redis
Introduction - In-memory Database
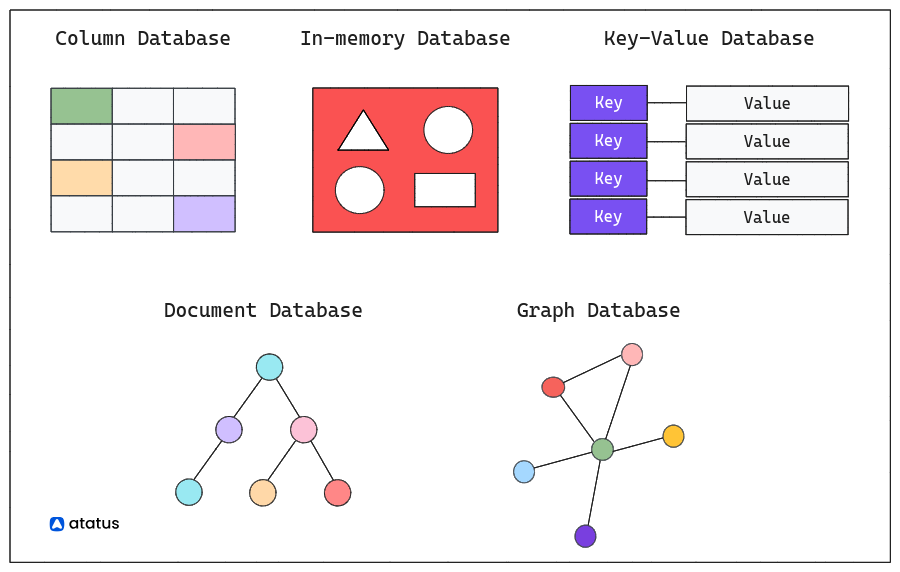
An in-memory database is a type of database management system (DBMS) that primarily relies on storing and managing data in the computer's main memory (RAM) rather than on disk storage. This approach contrasts with traditional databases that primarily store data on disk and retrieve it into memory when needed.
Redis vs Memcached
Redis and Memcached are well-known open-source in-memory data storage solutions. Memcached primarily serves as a key/value store for caching purposes.
Meanwhile, Redis, while also functioning as a key/value store for caching, is frequently adopted not only as a cache but also as a primary database or message broker. It additionally provides a distinct pathway for transitioning into a robust enterprise-level solution.
Memcached exclusively accommodates the string data type, making it well-suited for housing read-only information. In contrast, Redis offers compatibility with a wide array of data types, encompassing nearly all conceivable data formats.
Key-Value Pair
In Redis, a key-value pair is a fundamental data structure used for storing and retrieving data. The "key" is a unique identifier that is used to access the associated "value".
This concept is similar to how words are looked up in a dictionary: the word (key) is used to find its meaning (value). Redis uses this simple structure to enable efficient and quick data retrieval, making it well-suited for various applications like caching, session management, and more.
Differences between Redis and other Databases
Redis introduced the concept of a hybrid system that functions as both a storage solution and a cache. It was engineered with the principle of performing all data read and write operations in the primary computer memory.
Simultaneously, the data is persisted on disk in a manner unsuited for random data access. This structured data is reconstituted into memory only when the system undergoes a restart.
Redis diverges significantly from a typical relational database management system (RDBMS) in its data model. Instead of user commands outlining queries for execution by the database engine, Redis user commands dictate specific operations performed on abstract data types.
Consequently, the data storage strategy must be designed to facilitate swift retrieval in the future.
Retrieval occurs without reliance on database system features like secondary indexes, aggregations, or other conventional attributes of traditional RDBMSs. The implementation of Redis extensively utilizes the fork system call.
This call duplicates the process that holds the data. While the parent process continues to serve clients, the child process generates an in-memory replica of the data on disk.
What is Redis?
Redis, short for Remote Dictionary Server, stands as an open-source data structure store that resides in memory, serving as a database, cache, and message broker. Its core design focuses on speed, scalability, and adaptability, rendering it a favoured solution across various scenarios demanding rapid and efficient data storage and retrieval processes.
Due to its utilisation of in-memory storage and architectural design, Redis provides the advantage of minimizing latency in both read and write operations. This characteristic renders Redis especially well-suited for scenarios where caching is essential.
As a result, Redis has emerged as a dominant force in the realm of NoSQL databases, and it has achieved significant prominence as one of the most widely embraced database solutions overall.
Redis was developed by Salvatore Sanfilippo ("antirez") in 2009. Companies such as Twitter, Airbnb, Tinder, Yahoo, Adobe, Hulu, and Amazon incorporate Redis in their operations.
Redis offers client-side language bindings for a wide array of programming languages, including but not limited to Java, Python, Ruby, Go, and JavaScript (Node.js). This extensive support encompasses languages such as C, C++, C#, Elixir, Erlang, and many others, each having corresponding client software programs within the Redis ecosystem.
Features of Redis
Redis possesses the following attributes:
- In-Memory Data Storage: Redis predominantly stores data in memory, leading to rapid read and write operations, rendering it suitable for applications requiring quick data access.
- Diverse Data Structures: Redis accommodates an array of data structures including strings, lists, sets, sorted sets, hashes, bitmaps, hyperloglogs, and geospatial indexes, allowing for flexible data modelling.
- Persistence Choices: Redis provides options for both snapshot-based persistence and append-only files, enhancing durability by allowing data to be saved to disk or logged for recovery.
- Data Replication: Redis supports master-slave replication, enabling data to be duplicated from a master Redis instance to multiple slave instances, ensuring fault tolerance and read scalability.
- Robust Availability: Redis Sentinel automates monitoring and failover processes, assuring system availability by promoting a new master if the current one becomes inactive.
- Partitioning and Sharding: Redis Cluster streamlines horizontal scaling through automated data sharding across multiple nodes, redistributing the workload and boosting overall performance.
- Lua Scripting: Redis permits the direct execution of Lua scripts on the server, streamlining complex operations into a single server interaction.
- Atomic Operations: Redis executes operations on data structures atomically, guaranteeing consistency during multi-step operations.
- Time-to-Live (TTL): Redis supports the assignment of expiration times to keys, making it conducive to caching scenarios.
- Transactional Support: Redis permits transaction grouping using the MULTI and EXEC commands, ensuring the atomic execution of a series of operations.
- Memory Management: Redis employs diverse memory optimization techniques like compressed data structures and memory eviction policies to manage memory effectively.
- Cluster Management: Redis incorporates built-in tools for managing Redis Cluster instances, simplifying deployment, scalability, and monitoring tasks.
- Bitmap Operations: Redis supports bitmap data structures and operations, making it advantageous for applications involving analysis of user behaviour and similar use cases.
Redis Data Structures
Redis provides a wide range of data structures to meet a variety of data storage and manipulation requirements.
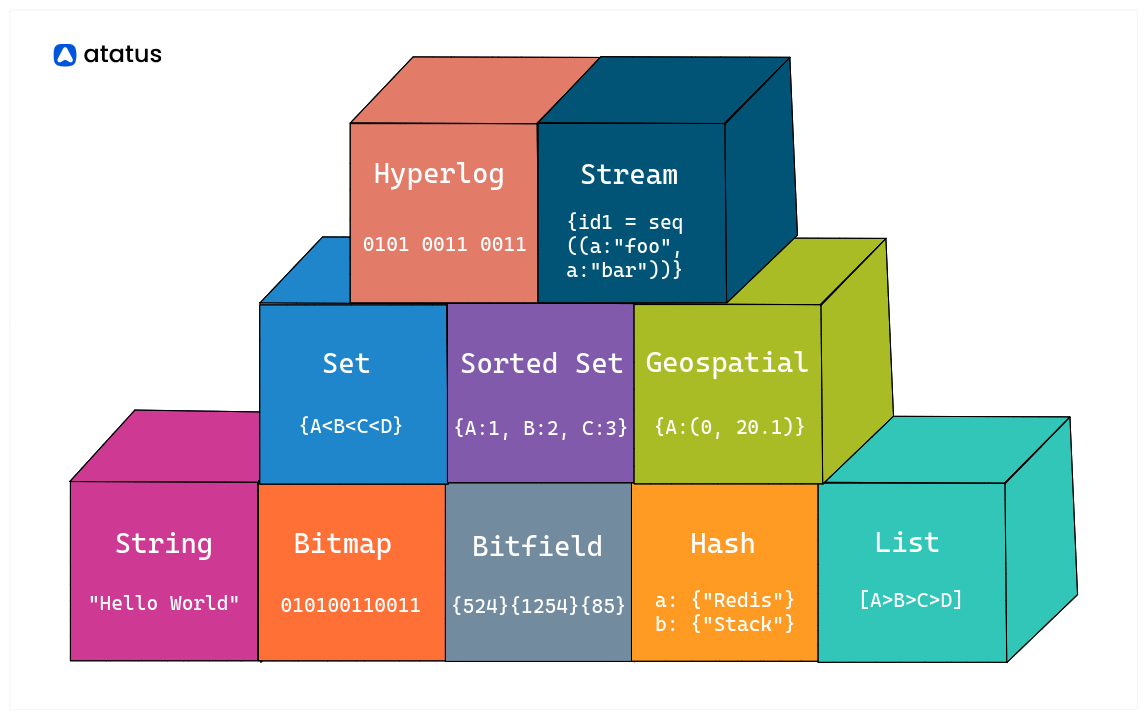
Redis' key data structures include:
i.) Strings: Fundamental key-value pairs, where the value may be a string, an integer, or a floating-point number. Redis additionally has operations for bit manipulation, concatenating strings, and other things.
Example:
SET username "john_doe"
GET usernameii.) Lists: Collection of strings that can have components added or removed from both ends and are arranged. Queues, stacks, and activity feeds are frequently implemented using lists.
Example:
LPUSH tasks "task1"
LPUSH tasks "task2"
LRANGE tasks 0 -1iii.) Sets: String collections that are not sorted. Sets are useful for executing set operations (union, intersection, difference), as well as removing duplicates from data.
Example:
SADD tags "redis"
SADD tags "caching"
SMEMBERS tagsiv.) Sorted Sets (Zsets): Similar to sets, but with each member having a corresponding score. When performing range-based queries based on scores, sorted sets are employed to maintain ordered lists.
Example:
ZADD leaderboard 100 "player1"
ZADD leaderboard 200 "player2"
ZRANGE leaderboard 0 -1 WITHSCORESv.) Hashes: Hashes, like dictionaries or maps, contain field-value pairs, where the field is a string and the value can be any data type. Hashes are good for representing things or entities.
Example:
HSET user:1 name "Alice"
HSET user:1 age 30
HGETALL user:1vi.) Bitmaps: A special kind of string where each bit may be set or unset allows for the space-efficient encoding of sets of values, including user activity over time.
Example:
SETBIT online_users 1001 1
BITCOUNT online_usersvii.) Bitfields: Storing and manipulating integer values at the bit level.
Example:
SETBIT stats:2023-08-16:clicks 1000 1
GETBIT stats:2023-08-16:clicks 1000viii.) HyperLogLog: Applied to accurately and efficiently estimate the cardinality (number of unique elements) of a set. available since Redis 2.8.9 in April 2014.
Example:
PFADD visitors "user1"
PFADD visitors "user2"
PFCOUNT visitorsix.) Streams: Streams, introduced in later versions of Redis, are a log-like data structure for storing and processing ordered sequences of data, making them useful for use cases such as event sourcing and messaging. available since Redis 5.0 in October 2018
Example:
XADD notifications * type message user "Alice" content "Hello, Redis!"
XREAD COUNT 1 STREAMS notifications 0x.) Geospatial Indexes: Stores geographical information (latitude and longitude) and allows for distance-based searches.
Example:
GEOADD locations -122.4194 37.7749 "San Francisco"
GEOADD locations -118.2437 34.0522 "Los Angeles"
GEODIST locations "San Francisco" "Los Angeles" kmWhat is Redis Stack?
In Redis, a "stack" typically refers to using a list data structure to simulate the Last-In-First-Out (LIFO) behaviour. Elements are added and removed from one end, following stack principles. This is often achieved using list commands like LPUSH (push to the left) and LPOP (pop from the left).
The Last-In-First-Out (LIFO) principle states that the last element added is always the first one to be withdrawn from a stack. Redis lists let you do operations like push (adding an element to the left end), pop (removing and obtaining an element from the left end), and more.
Here's an illustration of how to implement a stack using a Redis list:
# Adding elements to the stack
LPUSH mystack "item1"
LPUSH mystack "item2"
LPUSH mystack "item3"# Removing and retrieving elements from the stack
LPOP mystack # Returns "item3"
LPOP mystack # Returns "item2"In this illustration, components are added to the left end of the list (to mimic the behaviour of a stack) and removed from the same end.
It's crucial to remember that while Redis has the ability to simulate a stack using lists, you may also use alternative data structures, such as sets, sorted sets, or even bespoke Lua scripts, depending on your requirements.
Architecture of Redis
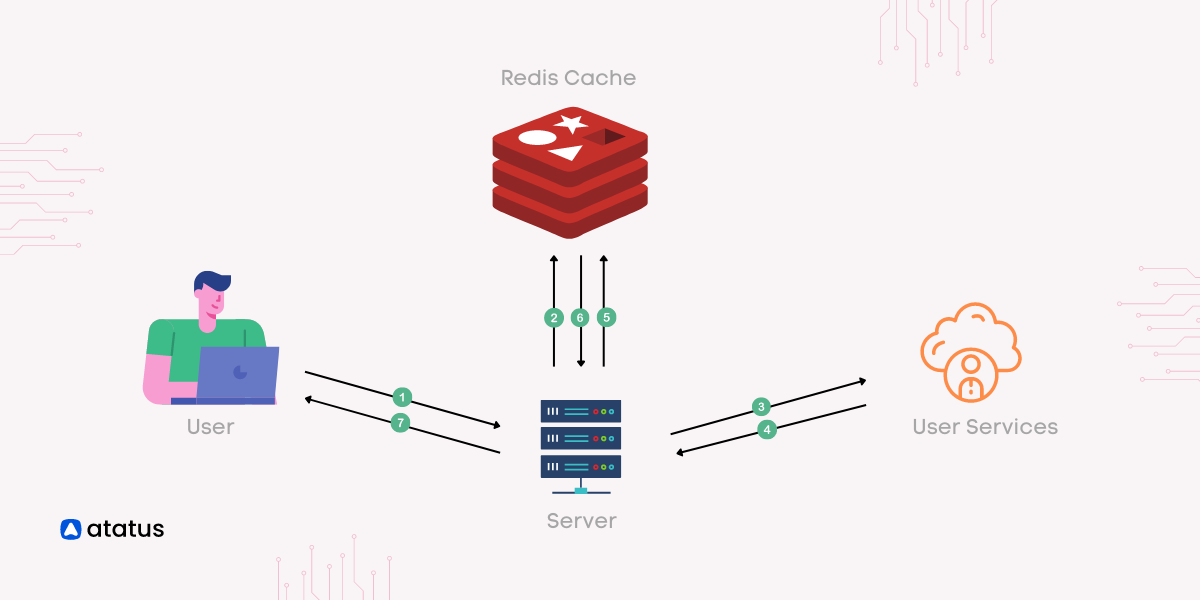
The Redis architecture comprises two primary components: the Redis client and the Redis server. You can install both the Redis server and client either on a single machine or on separate devices. Multiple clients can concurrently connect to a shared server, facilitating the handling of various requests.
Servers bear the responsibility of housing data within memory, subsequently overseeing all control aspects crucial to the architecture. As such, the Redis server constitutes a highly significant facet of this structure.
Conversely, a Redis client essentially serves as a Redis console integrated with a programming language tailored for the Redis API. In this setup, Redis retains all data within primary memory. However, it's essential to note that Redis's primary memory is impermanent; hence, restarting the server can lead to data loss.
Redis provides compatibility with the subsequent storage platforms:
The subsequent illustration delineates two segments: the client side and the server side.
AOF - primarily, enables data preservation by recording all write operations received from the server.
Save the command – Significantly, the "SAVE" command compels the Redis server to generate RDB snapshots on demand.
RDB - entails duplicating all data from memory and storing it in persistent storage at predefined intervals.
Replication is additionally provided to enhance fault tolerance and ensure data availability. Furthermore, you have the option to augment storage capacity by grouping two or more servers within a designated cluster.
The Redis architecture encompasses the following deployments:
- Single Redis Instance
- Redis High Availability (HA)
- Redis Sentinel
- Redis Cluster
1. Single Redis Instance
This represents the simplest way to deploy Redis. It requires users to configure and operate small instances that facilitate the expansion and acceleration of their services.'
Nevertheless, it comes with a disadvantage: if this active instance were to crash or become inaccessible, any requests directed towards Redis would be unsuccessful. As a result, there would be a decline in the overall system performance and speed.
2. Redis High Availability (HA)
An alternative widely used arrangement involves a primary deployment alongside a secondary deployment that consistently mirrors the replication process.
These secondary instances encompass one or multiple units within our deployment, facilitating the expansion of read capabilities from Redis. Furthermore, they offer a failover mechanism in scenarios where the primary instance becomes inaccessible.
High availability (HA) ensures consistent performance and uptime beyond the ordinary. Such systems avoid single points of failure, allowing smooth transitions between primary and secondary components without data loss, and feature automated failure detection and recovery.
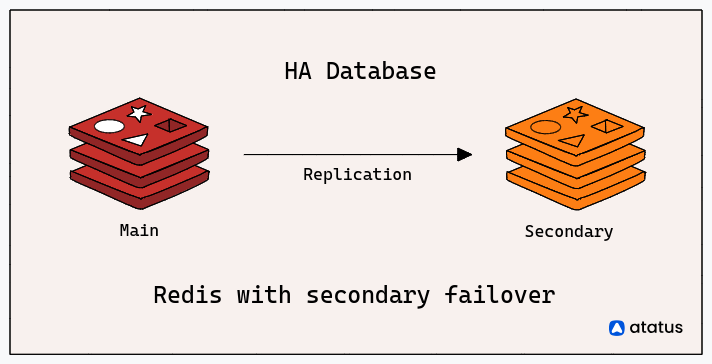
In this topology, various novel factors come into play as we step into a distributed system realm laden with multiple fallacies that demand attention. What was once simple now gains intricacy.
Redis Replication
In Redis, each main instance possesses a replication ID and an offset, crucial for pinpointing a replication instance's progress and enabling sync decisions. The offset increments with main instance actions.
When a replica is slightly behind the main instance, it catches up by replaying commands, achieving sync. Mismatched IDs or unknown offsets prompt full synchronization, where the main instance sends a snapshot to the replica. Replication resumes once the sync is complete.
Matching ID and offset mean identical data. A replication ID helps infer past primaries for partial sync after a restart or promotion. Similar IDs and slightly differing offsets indicate matching datasets. Dissimilar IDs require full sync unless common ancestry helps perform partial sync based on previous replication ID knowledge.
3. Redis Sentinel
Sentinel represents a distributed system configuration. It's structured to encompass a cluster of sentinel processes collaborating to coordinate the system's state, ensuring uninterrupted accessibility of the Redis system. In addition to caching, Redis Sentinel offers several other functionalities.

- Monitoring: Scrutinizing all instances, including both master and slave, to ensure proper functionality.
- Notification: In case any Redis instance deviates from expected behaviour, Sentinel can alert system administrators or external programs via an API.
- Automatic failover: If the master doesn't function as anticipated, Sentinel elevates a slave to the master position and redirects additional slaves to the new master.
Sentinel serves as the primary reference for clients. Clients connect to Sentinel to obtain information about the present Redis master's location.
4. Redis Cluster
The Redis cluster stands as the definitive architecture within Redis, enabling the horizontal expansion of its capabilities.
Within the Redis cluster framework, we opt to distribute the data we store across numerous machines, a technique referred to as sharding. As a result, each Redis instance present in the cluster is regarded as a shard encompassing a portion of the complete dataset.
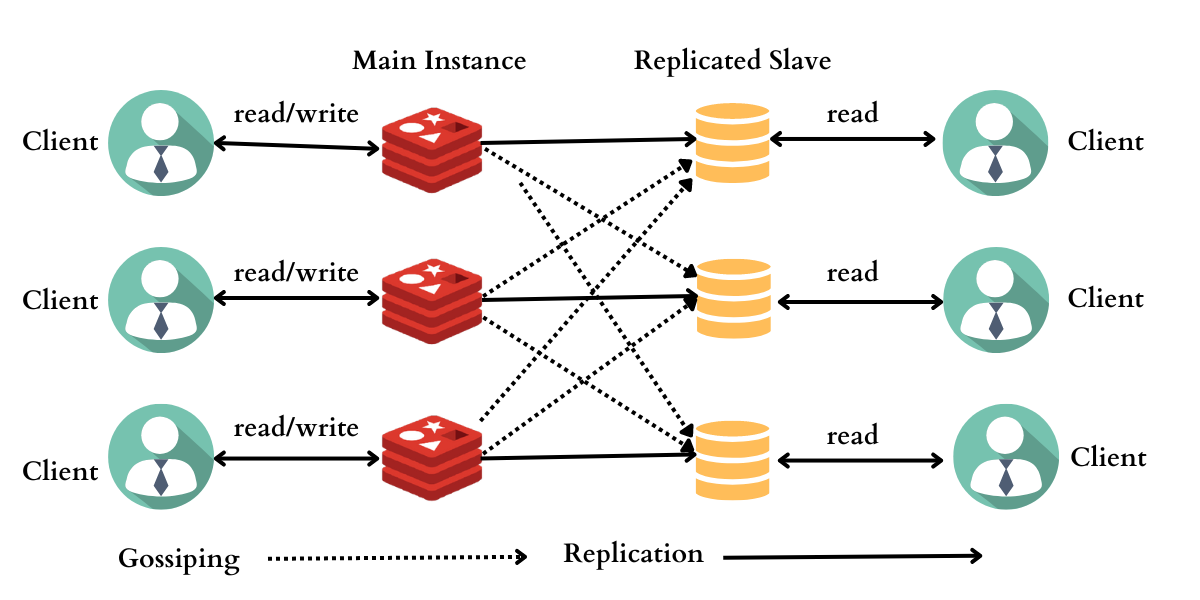
Algorithmic sharding is the approach employed by the Redis Cluster. When determining the shard associated with a specific key, the key undergoes a hashing process, followed by modulo division against the total number of shards.
Employing a deterministic hash function ensures that a given key consistently maps to the same shard. Consequently, this enables us to predict the shard location of a particular key when reading it in subsequent instances.
For accommodating the addition of additional shards within the system, also known as sharding, the Redis cluster employs a Hashslot mechanism to which all data is allocated.
Consequently, when introducing new shards, we can seamlessly transfer hash slots from one shard to another, streamlining the process of incorporating new primary instances into the cluster. Remarkably, this procedure can be executed without causing any downtime and with only a minimal impact on performance. An illustrative example is presented below:
Consider the number of hashslots to be 10K.
Instance1 contains hashslots from 0 to 5000,
Instance2 contains hashslots from 5001 to 10000.
Now, let’s say we need to add another instance, now the distribution of hashslots comes to,
Instance1 contains hashslots from 0 to 3333.
Instance2 contains hashslots from 3334 to 6667.
Instance3 contains hashslots from 6668 to 10000.
Persistence Model in Redis
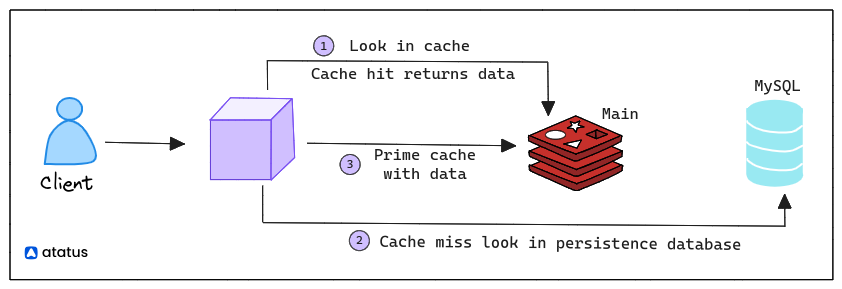
In Redis, a persistence model refers to the mechanisms used to store data on disk so that it can be recovered even after a Redis server restarts or crashes. Redis is an in-memory data store that provides high-performance caching and data storage. However, since all data is stored in memory, there's a risk of data loss in case of system failures.
Redis offers two main mechanisms for persistence:
1. RDB (Redis Database):
Redis can periodically take a snapshot of the dataset and write it to disk as an RDB file. This file is essentially a binary representation of the dataset at a specific point in time.
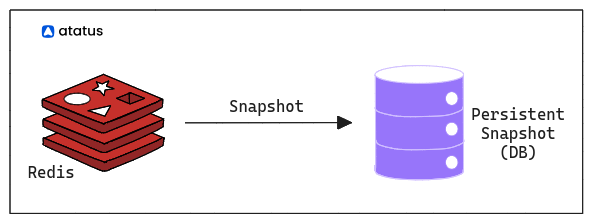
RDB snapshots can be configured to occur at different intervals or triggered manually. RDB files are generally more compact and suitable for backup purposes.
2. AOF (Append-Only File):
The AOF persistence mode logs all write operations (commands that modify the data) to a log file. This log file contains a sequence of commands that can be replayed to reconstruct the dataset. The AOF file is written sequentially and can grow over time. Redis offers different AOF synchronization options, like every write, every second, or even less frequently.
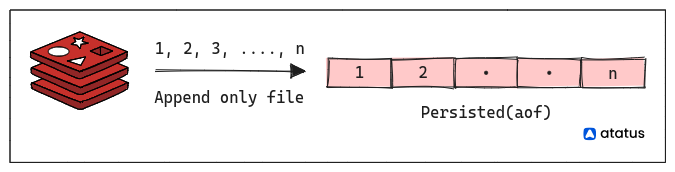
Users can choose to use either RDB or AOF or even both together, depending on their use case and the trade-off between data safety and performance. Combining both mechanisms provides a way to recover data from the last RDB snapshot and replay subsequent commands from the AOF log to bring the dataset up to the most recent state.
Drawbacks of Redis
Just like any other technology, Redis comes with certain limitations that need to be taken into account when evaluating its suitability for a specific application.
A primary drawback associated with Redis is its exclusive reliance on memory for data storage. Consequently, the system becomes vulnerable to potential data loss during crashes or shutdowns.
To mitigate this concern, Redis offers solutions like persistence and replication, enabling data to be stored on disk and duplicated across various servers. Nevertheless, the utilization of these features can introduce intricacies and additional processing demands, a factor that might not align well with every application's requirements.
An additional limitation of Redis is its single-threaded nature, restricting it to handling just one command at a time. This characteristic has the potential to curtail Redis's performance and scalability in scenarios demanding substantial concurrency and parallel processing.
In response, Redis introduces clustering and sharding functionalities to distribute data across multiple servers. However, these capabilities can introduce intricacies during setup and management.
Use Cases of Redis
Redis is adaptable and may be used for a variety of use cases because of its excellent performance and flexibility. Redis has a few frequent applications, such as:
- Caching: Redis is typically used as a caching layer to save frequently visited data in memory and eliminate the need to retrieve data from slower data sources. As a result, application response times are sped up, and backend databases are put under less stress.
- Session Management: Redis excels at handling user sessions in web applications. Storing session data in Redis enables quick and efficient session retrieval, improving user experience.
- Real-time Analytics: Because Redis has minimal latency, it can perform real-time data processing and analytics. Metrics, logs, and other real-time data streams are utilised to store and analyse it.
- Leaderboards and Counting: In gaming apps, social media sites, and other systems involving user engagement metrics, Redis is used to generate leaderboards to track counts, points, and ranks.
- Pub/Sub Messaging: Real-time messaging systems can be created more easily thanks to Redis' publish/subscribe (pub/sub) feature. Notifications, event broadcasts, and chat applications all use it.
- Job Queues: Redis is used to create job queues and work scheduling systems. It aids in the management of asynchronous jobs and the effective distribution of workloads.
- Geospatial Indexing: For location-based queries and applications, including mapping and location-based services, Redis supports geospatial data.
- Caching for Databases: Redis can act as a database cache, lowering the burden on core databases and boosting query performance.
- Rate Limiting: To regulate the frequency of specific actions, such as API requests, stop abuse, and guarantee fair usage, Redis can impose rate restrictions.
- Distributed Locking: Redis provides distributed locking methods that enable several processes or threads to collaborate and guarantee exclusive access to resources.
- Content and Object Caching: Redis can cache dynamic content or objects, including HTML fragments, database query results, or serialised objects, to enhance content delivery and lower server load.
- Shopping Cart and E-commerce: Redis is used to store shopping cart data, manage inventory, and deliver real-time updates on product availability and prices.
Conclusion
Redis appears to be a powerful and adaptable technology with enormous promise for improving web applications and distributed systems.
Its main advantages are its lightning-fast performance, scalability, and support for advanced features like Pub/Sub and Lua scripting. As a caching solution, Redis may significantly reduce server load, resulting in faster response times and a better overall user experience.
However, a fair judgement necessitates understanding its limits. The necessity for extensive memory allocation might be a significant factor, especially for larger datasets. The lack of inherent backing for intricate queries and joins should also be contemplated, particularly for endeavours necessitating.
Redis can be a game-changer in situations demanding caching, real-time communication, and prioritized speed. Yet, applications seeking strong transactional support, intricate querying abilities, and alignment with relational data models could find a better fit with alternative database solutions.
Hence, incorporating Redis into a project should hinge on a meticulous assessment of exact needs and use scenarios.
Enhance Your Redis Monitoring with Atatus
Are you looking to ensure optimal performance and reliability for your Redis database? Atatus offers comprehensive Redis monitoring that empowers you to keep your data store in check and your applications running smoothly.
- Problem Diagnostics: Troubleshoot issues quickly by drilling down into detailed Redis metrics.
- Latency Analysis: Pinpoint delays in data retrieval and updates, ensuring optimal responsiveness of your Redis operations.
- Throughput Insights: Monitor request and command rates to fine-tune Redis for maximum throughput, preventing performance bottlenecks.
- Memory Utilization: Keep track of memory usage trends to prevent out-of-memory crashes and optimize data storage.
- Capacity Planning: Make informed decisions about scaling resources based on usage patterns.
- Connection Tracking: Track connections in real-time to manage resource allocation and ensure efficient network usage.
Try Atatus’s entire features free for 14 days.
Boost your Redis experience and keep your app running smoothly. Try out our Redis Monitoring solution today for top-notch results.
#1 Solution for Logs, Traces & Metrics
![]() APM
APM
![]() Kubernetes
Kubernetes
![]() Logs
Logs
![]() Synthetics
Synthetics
![]() RUM
RUM
![]() Serverless
Serverless
![]() Security
Security
![]() More
More