Statefulset vs. Deployment in Kubernetes
As Kubernetes continues its ascent as a leading container orchestration platform, it's common for users to encounter a perplexing choice between two prominent workload controllers: StatefulSets and Deployments.
Despite both controllers being instrumental in managing high-availability workloads, they diverge significantly in terms of features and use cases. Grasping these distinctions is pivotal for fine-tuning the performance and scalability of your Kubernetes infrastructure.
This blog post takes a deep dive into the fundamental disparities that set StatefulSets and Deployments apart. We'll unravel their respective use cases and guide you in selecting the precise controller that aligns with your workload's demands.
Moreover, we're poised to furnish you with invaluable best practices for the deployment and management of high-availability workloads within Kubernetes using these very controllers.
Table of Content
- Statefulset in Kubernetes
- Features of Statefulset
- Deployment in Kubernetes
- Statefulsets vs Deployments
- When to use StatefulSet vs. Deployment in Kubernetes
Statefulset in Kubernetes
StatefulSets are primarily used for managing stateful applications, where each instance (Pod) of the application has a unique identity and typically maintains its own persistent data. Examples of stateful applications include databases like MySQL, MongoDB, and distributed systems like Apache Kafka.
It provide guarantees about the order in which pods are created, updated, and deleted. When you scale up a StatefulSet, each pod is created in a specific order, and when you scale down, pods are terminated in the reverse order. This ordering ensures that data consistency and dependencies between pods are maintained.
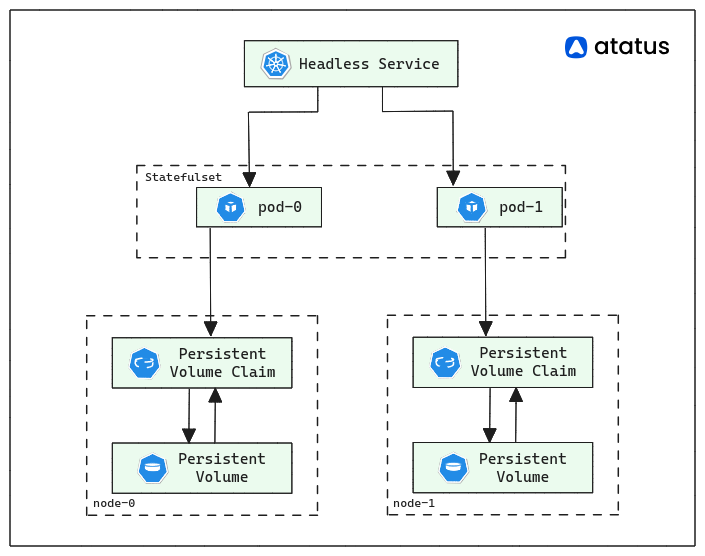
StatefulSets can utilize PersistentVolumes (PVs) to provide persistent storage for their pods. Each pod created by a StatefulSet can be associated with a unique PersistentVolumeClaim (PVC), allowing the pod to access the same storage even if it gets rescheduled to a different node.
To create and manage a StatefulSet in Kubernetes, you define a StatefulSet manifest file that describes the desired state of the StatefulSet, including the pod template, replica count, storage requirements, and any other relevant configuration.
You can then use the Kubernetes API or a Kubernetes management tool (e.g., kubectl) to create, update, or delete the StatefulSet based on the manifest file.
Note that StatefulSets require certain features to be enabled in the underlying Kubernetes cluster, such as a stable network identity for each pod (provided by a Headless Service) and a storage solution that supports dynamic provisioning (such as a provisioner for PVs).
StatefulSets provide a robust and reliable way to manage stateful applications in Kubernetes, offering unique identity, ordered deployment, and persistent storage capabilities.
Here's an example of a StatefulSet manifest file in YAML format:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: my-statefulset
spec:
serviceName: my-statefulset
replicas: 3
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: my-container
image: my-image:latest
ports:
- containerPort: 8080
volumeMounts:
- name: data-volume
mountPath: /data
volumeClaimTemplates:
- metadata:
name: data-volume
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 10GiIn this example, we define a StatefulSet named my-statefulset with three replicas. The selector field is used to match the pods managed by the StatefulSet. The template section specifies the pod template for the StatefulSet, including container details, ports, and volume mounts.
The StatefulSet uses a volumeClaimTemplate to dynamically provision PersistentVolumeClaims for each pod. In this case, we define a volume named data-volume with a storage request of 10 gigabytes (storage: 10Gi), and the access mode is set to ReadWriteOnce, indicating that the storage can be mounted by a single pod at a time.
You can apply this manifest file using the kubectl apply command:
kubectl apply -f statefulset.yamlThis will create the StatefulSet and the associated pods and PersistentVolumeClaims. Kubernetes will ensure that the pods are created and scaled up in an ordered manner, and each pod will have its unique network identity and access to its persistent storage.
Features of Statefulset
StatefulSets in Kubernetes have several features that make them well-suited for managing stateful applications. Some of the key features of StatefulSets are as follows:
1. Pod Management
StatefulSets manage the creation, scaling, and deletion of pods. Pods created by a StatefulSet have a unique and stable network identity. Pods are created and terminated in a predictable order, ensuring orderly scaling and rolling updates.
2. Stable Network Identity
Each pod in a StatefulSet is assigned a stable hostname based on the pod's index. The hostname allows other pods to access the StatefulSet pods by their unique identity. Stable network identity enables applications to rely on consistent network addresses.
3. Persistent Storage
StatefulSets provide support for persistent storage volumes. Each pod in a StatefulSet can have its own unique persistent volume. Persistent volumes ensure data persistence across pod restarts or rescheduling.
4. Scaling and Updates
StatefulSets support both manual and automatic scaling of pods. Scaling a StatefulSet will create or delete pods in a predictable manner. Rolling updates can be performed on a StatefulSet, ensuring zero-downtime updates.
5. Headless Service
StatefulSets automatically create a headless service for accessing individual pods. The headless service allows direct communication with each pod by its hostname. It can be used for peer discovery or connecting to specific instances in the StatefulSet.
6. StatefulSet Controller
The StatefulSet controller monitors the desired state and actual state of pods. It ensures that the number of pods matches the desired replica count. The controller handles pod creation, deletion, scaling, and rolling updates.
Deployment in Kubernetes
Deployments are designed for managing stateless applications, where each instance (Pod) is identical and doesn't rely on maintaining its own persistent data. Stateless applications can be easily replaced or scaled horizontally.
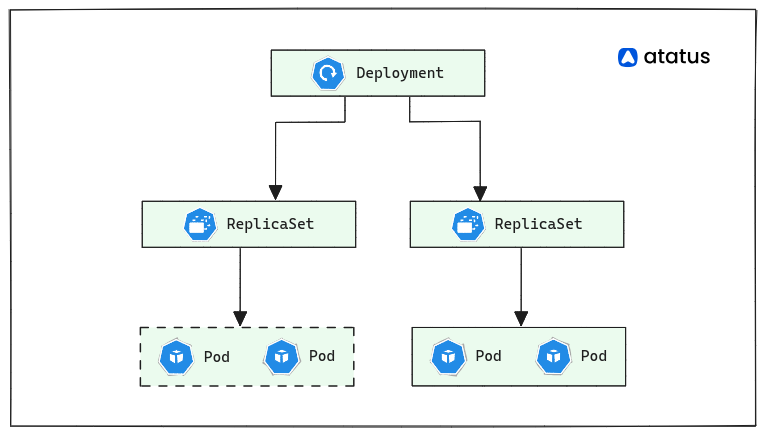
Let's break down the components of a Deployment in Kubernetes:
1. Application Deployment
A Deployment manages the deployment of application containers as pods in a Kubernetes cluster. It allows you to define the desired state of your application, including the number of replicas and the container image to use.
2. Replica Sets
Under the hood, a Deployment creates and manages ReplicaSets, which are responsible for maintaining a specified number of pod replicas. ReplicaSets ensure high availability by automatically replacing failed or terminated pods.
3. Rolling Updates and Rollbacks
Deployments support rolling updates, allowing you to update your application without causing downtime. During a rolling update, new pods with the updated version are gradually created, while old pods are gracefully terminated. If an issue is detected during the update, a rollback to the previous version can be performed easily.
4. Scaling
Deployments support both manual and automatic scaling of replicas. Scaling a Deployment adjusts the number of running replicas to meet the desired state. Automatic scaling can be achieved using Horizontal Pod Autoscalin (HPA) based on CPU utilization or other metrics.
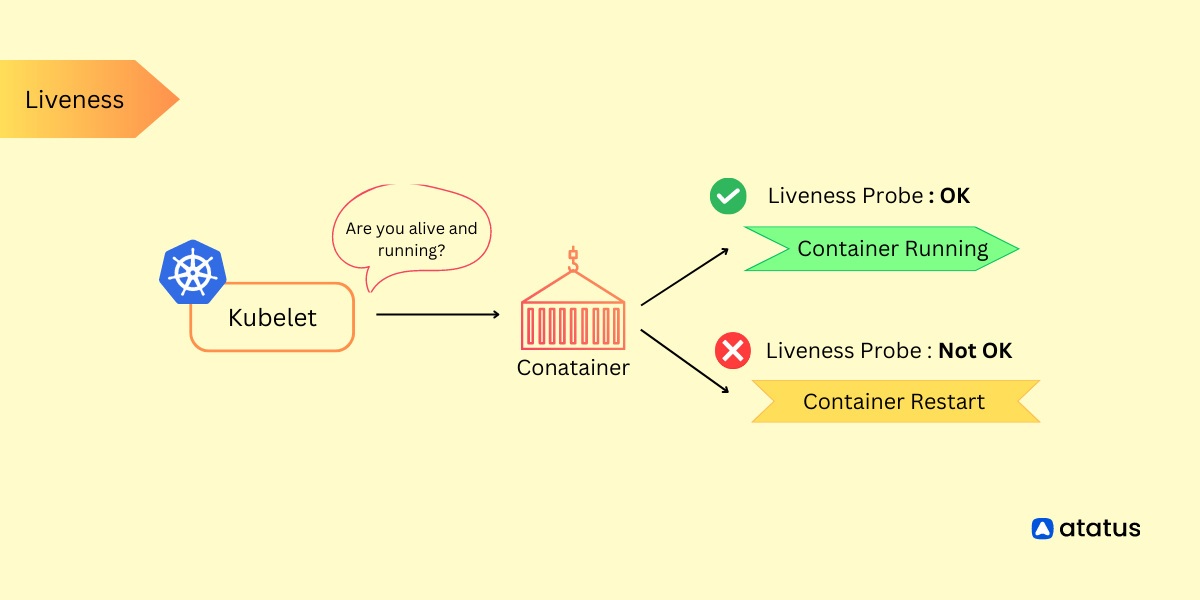
5. Health Checks and Self-Healing
Deployments can be configured to perform health checks on pods using readiness and liveness probes. Readiness probes ensure that pods are ready to receive traffic, while liveness probes detect and restart unhealthy pods.
6. Declarative Configuration
Deployments are defined using declarative YAML or JSON files, which specify the desired state of the application. The desired state includes information about the container image, environment variables, resource limits, and more.
7. Update Strategies
Deployments support different update strategies, such as rolling updates (default), recreating pods, or pausing updates. These strategies allow you to control the pace and behavior of updates to match your application's requirements.
Deployment Examples
Here are coding examples showcasing how to create a Deployment in Kubernetes using YAML manifests:
1. Basic Deployment
The following example demonstrates a simple Deployment that deploys a single replica of a containerized application.
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-deployment
spec:
replicas: 1
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: my-container
image: my-image:latest
ports:
- containerPort: 80This example creates a Deployment named my-deployment. The replicas field is set to 1, indicating that a single replica of the application should be created and maintained.
The selector field specifies the labels used to select the pods controlled by the Deployment. The template field defines the pod template for the Deployment. Inside the template, a single container named my-container is defined. The container uses the image my-image:latest and exposes port 80.
2. Deployment with Scaling
This example shows a Deployment that initially deploys three replicas of the application and can be scaled up or down.
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-deployment
spec:
replicas: 3
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: my-container
image: my-image:latest
ports:
- containerPort: 80This example is similar to the first one but has the replicas field set to 3. It indicates that the Deployment should maintain three replicas of the application. This allows for horizontal scaling by adding or removing replicas as needed.
3. Deployment with Rolling Update
Here's an example demonstrating a Deployment with a rolling update strategy, allowing you to update the application without downtime.
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-deployment
spec:
replicas: 3
selector:
matchLabels:
app: my-app
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1
maxSurge: 1
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: my-container
image: my-image:v2
ports:
- containerPort: 80In this example, the Deployment has the rolling update strategy specified. The maxUnavailable field is set to 1, which means that during an update, at most one replica can be unavailable at a time.
The maxSurge field is set to 1, allowing the Deployment to temporarily have one additional replica during an update.
These settings ensure that the rolling update process progresses gradually, maintaining availability as the new version is rolled out. The image in the container is changed to my-image:v2, representing the updated version of the application.
StatefulSets vs Deployments
Let's say you have a simple web application that doesn't maintain any local state, such as a static website or a front-end service. You can use a Deployment to manage this application:
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-app-deployment
spec:
replicas: 3
selector:
matchLabels:
app: web-app
template:
metadata:
labels:
app: web-app
spec:
containers:
- name: web-app-container
image: your-web-app-image:latest
ports:
- containerPort: 80In Kubernetes Deployment, each replica of a pod is considered interchangeable. When you update a Deployment, Kubernetes might create new pod replicas with updated configurations and then gradually replace the old ones in a controlled manner.
This interchangeable nature of pods in Deployments means that they don't need to have stable and predictable identities. They can be assigned random IDs, and Kubernetes will manage their scaling, updates, and rollbacks without concern for individual pod identity.
In this example, the Deployment manages three replicas of a web application. The actual pod names can be something like web-app-deployment-xyzabc123, where xyzabc123 is a random string generated by Kubernetes. The important aspect here is that these pods are interchangeable, and their identity is not critical.
Now, imagine you're running a distributed database that requires unique network identities and stable storage. A StatefulSet can be used to manage this application:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: database-statefulset
spec:
replicas: 3
serviceName: database-service
selector:
matchLabels:
app: database-app
template:
metadata:
labels:
app: database-app
spec:
containers:
- name: database-container
image: your-database-image:latest
ports:
- containerPort: 5432
StatefulSets are used for applications that require stable, predictable identities and ordered scaling. This is particularly important for stateful applications like databases, where each instance might represent a shard or a node in a cluster. StatefulSets ensure that each pod instance maintains its identity, hostname, and network identifier throughout its lifecycle.
In this example, the StatefulSet manages three replicas of a database application. The pods will be named database-statefulset-0, database-statefulset-1, and so on. The identity of each pod is stable and predictable, which is crucial for maintaining the integrity of the stateful application.
The main difference between StatefulSets and Deployments in Kubernetes lies in their management of stateful applications and the guarantees they provide.
| Feature | StatefulSets | Deployments |
|---|---|---|
| Use Case | Stateful applications (e.g., databases) | Stateless applications, microservices, web servers |
| Stable Identity | Pods have unique and stable network identities | Pods don't have stable network identities |
| Scaling | Supports scaling, but with ordered deployment | Supports scaling, replicas are interchangeable |
| Persistent Storage | Supports unique persistent volumes per pod | Typically does not handle persistent storage |
| Ordering Deployments | Provides ordering guarantees for pod creation and deletion | No specific guarantees for pod order during creation and deletion |
| Rolling Updates | Not designed for rolling updates | Supports rolling updates for seamless updates |
| Use Cases | Databases, distributed systems | Web servers, microservices, stateless applications |
When to use StatefulSet vs. Deployment in Kubernetes
When to use StatefulSet:
- For stateful applications requiring unique network identities and stable hostnames.
- When ordered and predictable deployment and scaling of pods are essential, as it maintains fixed pod naming.
- If data persistence through Persistent Volumes (PVs) is needed for applications that store data.
- During rolling updates to maintain the identity and data of each pod.
When to use Deployment:
- For deploying stateless applications that don't rely on persistent data or unique network identities.
- When easy scaling is required without the need for ordered pod naming or maintaining stateful data.
- If frequent application updates with rolling updates are needed, prioritizing simplicity and speed.
- To leverage features like ReplicaSets for high availability and scaling capabilities.
Conclusion
StatefulSets are designed for stateful applications requiring stable network identities and persistent storage. They guarantee ordered pod creation and deletion, ensuring orderly scaling and updates. With unique hostnames and support for persistent volumes, they are well-suited for databases and distributed systems.
Deployments, on the other hand, are tailored for stateless applications without stable network identities or persistent storage needs. They manage replica scaling via ReplicaSets and support seamless rolling updates. Deployments are commonly used for web servers and microservices.
The choice between StatefulSets and Deployments depends on specific application requirements. StatefulSets are ideal for stateful applications needing stable identities and data persistence. Deployments are better suited for stateless applications requiring rolling updates and scaling capabilities.
Atatus Kubernetes Monitoring
With Atatus Kubernetes Monitoring, users can gain valuable insights into the health and performance of their Kubernetes clusters and the applications running on them. The platform collects and analyzes metrics, logs, and traces from Kubernetes environments, allowing users to detect issues, troubleshoot problems, and optimize application performance.
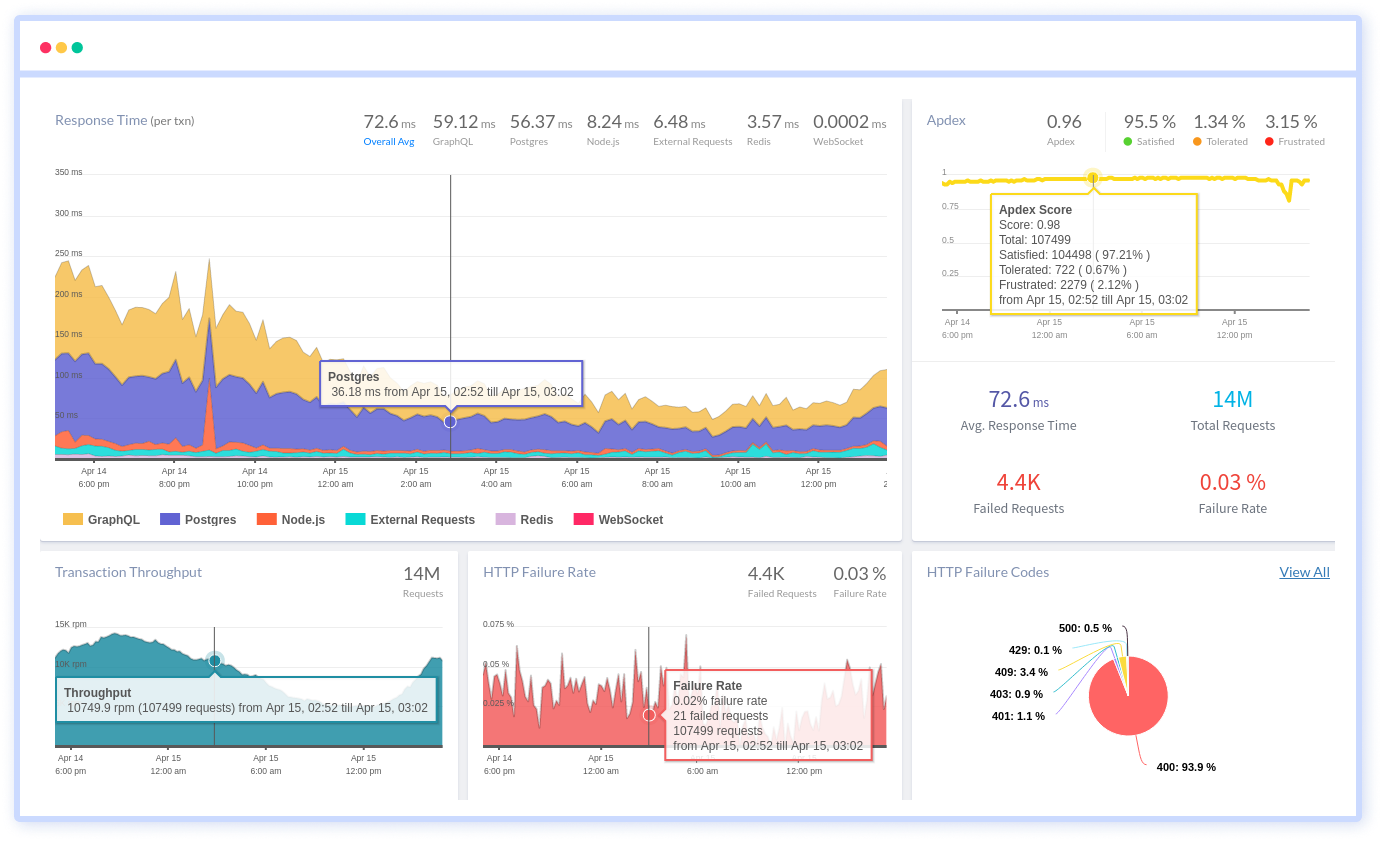
You can easily track the performance of individual Kubernetes containers and pods. This granular level of monitoring helps to pinpoint resource-heavy containers or problematic pods affecting the overall cluster performance.
#1 Solution for Logs, Traces & Metrics
![]() APM
APM
![]() Kubernetes
Kubernetes
![]() Logs
Logs
![]() Synthetics
Synthetics
![]() RUM
RUM
![]() Serverless
Serverless
![]() Security
Security
![]() More
More