
A unified resource identifier (URI), in the world of computers, is a group of characters that is used to specify a name or a web resource. Such resource identification enables communication with web resource representations through a network utilizing particular protocols. Each URI is defined by a set of schemes with accompanying protocols and concrete syntax. In the Semantic Web, anything that can be identified by a URI can be defined and used as a basis for machine reasoning.
We will cover the following:
- What is Uniform Resource Identifier (URI)?
- History
- Types of URI
- Components of URI
- How do Uniform Resource Identifiers Work?
- URI vs URL
What is Uniform Resource Identifier (URI)?
Uniform Resource Identifier is a full form of URI. A logical or physical resource used by web technologies is identified by a Uniform Resource Identifier (URI), which is a unique sequence of characters. Anything can be identified by a URI, including concepts, information resources like web pages and books, as well as actual physical objects like people and places.
Some URIs, known as Uniform Resource Locators, offer a method of finding and obtaining information resources on a network (either on the Internet or on another private network, like a computer filesystem or an Intranet).
The location of the resource is provided by its URL. The resource is namely identified by a URI at the given place or URL.
Other URIs, such as Uniform Resource Names (URNs), just offer a distinctive name without a way to find or retrieve the resource or information about it. Web browsers are not the only web technology that employs URIs.
For example, ideas that are a part of an ontology defined using the Web Ontology Language (OWL) and people who are described using the Friend of a Friend vocabulary would each have a distinct URI. URIs are used to identify anything specified using the Resource Description Framework (RDF).
History
A history exists between URIs and URLs. The concept of a URL as a brief string designating a resource that serves as the target of a hyperlink was indirectly presented by Tim Berners-Lee in his ideas for hypertext in 1990. It was known as a "document name" or "hypertext name" at the time.
A requirement to distinguish between a string that supplied an address for a resource from a string that only identified a resource emerged during the following three and a half years as the World Wide Web's foundational technologies of HTML, HTTP, and web browsers evolved.
Although not yet fully defined, the terms Uniform Resource Locator and the more divisive Uniform Resource Name came to stand for the former and the latter, respectively.
The IETF "UDI (Universal Document Identifiers) BOF" report from July 1992 includes references to URLs (as Uniform Resource Locators), URNs (initially as Unique Resource Numbers), and the requirement to establish a new working group.
The inaugural meeting of the IETF "URI Working Group" took place in November 1992. It became clear throughout the discussion of the definitions of URLs and URNs that the ideas represented by the two names were only facets of the underlying, overarching concept of resource identification.
Berners-first Lee's Request for Comments, which acknowledged the existence of URLs and URNs, was published by the IETF in June 1994. A formal syntax for Universal Resource Identifiers was most notably defined.
Additionally, the RFC 1630 made an effort to condense the syntaxes of the URL schemes that were in use at the time. It accepted the existence of relative URLs and fragment identifiers but did not standardize them.
Types of URI
URIs can be of two types:
- Fragment URI (URN)
Universal Resource Name is referred to as URN. It uses an anchor identifier to refer to the content's position. But URLs are not URNs and vice versa. For each URN, there is a prefix URN. When "access mechanism, location" is specified, URI becomes the URL. - Relative URI (URL)
Uniform Resource Locator, or URL, is a term. The superset of a URL is a URI. The document inside the content may be defined by URN or Fragment URI. The URL contains instructions on how to obtain a resource from its location. Every URL starts with a protocol (Most obvious, HTTP). It will include information about the hostname and the path. A URL is used when a client sends a service request to the server.
Components of URI
Typically, a URL for HTTP (or HTTPS) consists of three or four components:
A Scheme
The protocol to be used to access the Internet resource is specified by the scheme. It can be HTTPS (with SSL) or HTTP (without SSL).
A Host
The host holding the resource is identified by its host name. For instance, www.example.com. Although hosts and servers do not correspond one-to-one, a server offers services under the host's name.
Port numbers can also be used to accompany host names. Typically, well-known port numbers for a service are not included in the URL. Most HTTP URLs omit the port number since most servers utilize the well-known port numbers for HTTP and HTTPS.
A Path
The web client wants to access a specific resource on the host, and the path specifies that resource. For instance, /software/htp/cics/index.html.
A Query String
If a query string is used, it does so after the path component and gives a string of data that the resource can use (for example, as parameters for a search or as data to be processed). Term=bluemonday is an example of a name and value pair that typically makes up the query string. Term=bluemonday&source=browser-search is an example of a name and value pair separated by an ampersand.
Although the case is not specified for the scheme or host components of a URL, it is for the path and query string. The entire URL is typically written in lowercase.
The following is how the URL's components are combined and delimited:
scheme://host:port/path?query

- A colon and two forward slashes are placed after the scheme.
- A colon separates the port number from the hostname if one is given.
- One forward slash before the path name at the start.
- A question mark is used to indicate whether a query string is given.
A fragment identifier could be put after a URL. The # character is used as a separator between the URL and the fragment identifier. A web browser can access a reference or function in the recently obtained item by using a fragment identifier.
For instance, if the URL identifies an HTML page, the ID of the subsection can be used as a fragment identifier to denote a segment within the page. In this situation, the user's web browser normally shows them the page so that they can see the subsection. Depending on the item's media type and the established meaning of the fragment identifier for that media type, the web browser's response to a fragment identifier varies.
URLs are also used by other protocols, like File Transfer Protocol (FTP) and Gopher. Some protocols’ URLs may differ from HTTP's in terms of syntax.
How do Uniform Resource Identifiers Work?
An easy-to-use, flexible method of identifying internet resources is provided by URIs. Different kinds of resource identifiers can be used in the same context because of the uniformity that URIs offer, independent of the methods employed to access those resources.
Additionally, the resource identifiers can be applied in various situations.
URIs can be used to identify a variety of resources, including:
- Electronic documents
- Webpages
- Images
- Information sources with a consistent purpose
URI vs URL
A URI can also be categorized as a name, a locator, or both. The phrase "Uniform Resource Locator" (URL) designates a subset of URIs that, in addition to identifying a resource, also offer a way to locate the resource by outlining its principal access mechanism (for example, its network "location").
The term "Uniform Resource Name" (URN) has been used to describe both URIs that follow the "urn" scheme [RFC2141], which must continue to be globally unique and persistent even if the resource disappears or becomes inaccessible, and any other URI that possesses the characteristics of a name.
The terms "URI" and "URL," though frequently used interchangeably, are not the same. A URL is a special kind of identifier that identifies a resource and describes how it can be accessed, whereas a URI is an identifier of a particular resource.
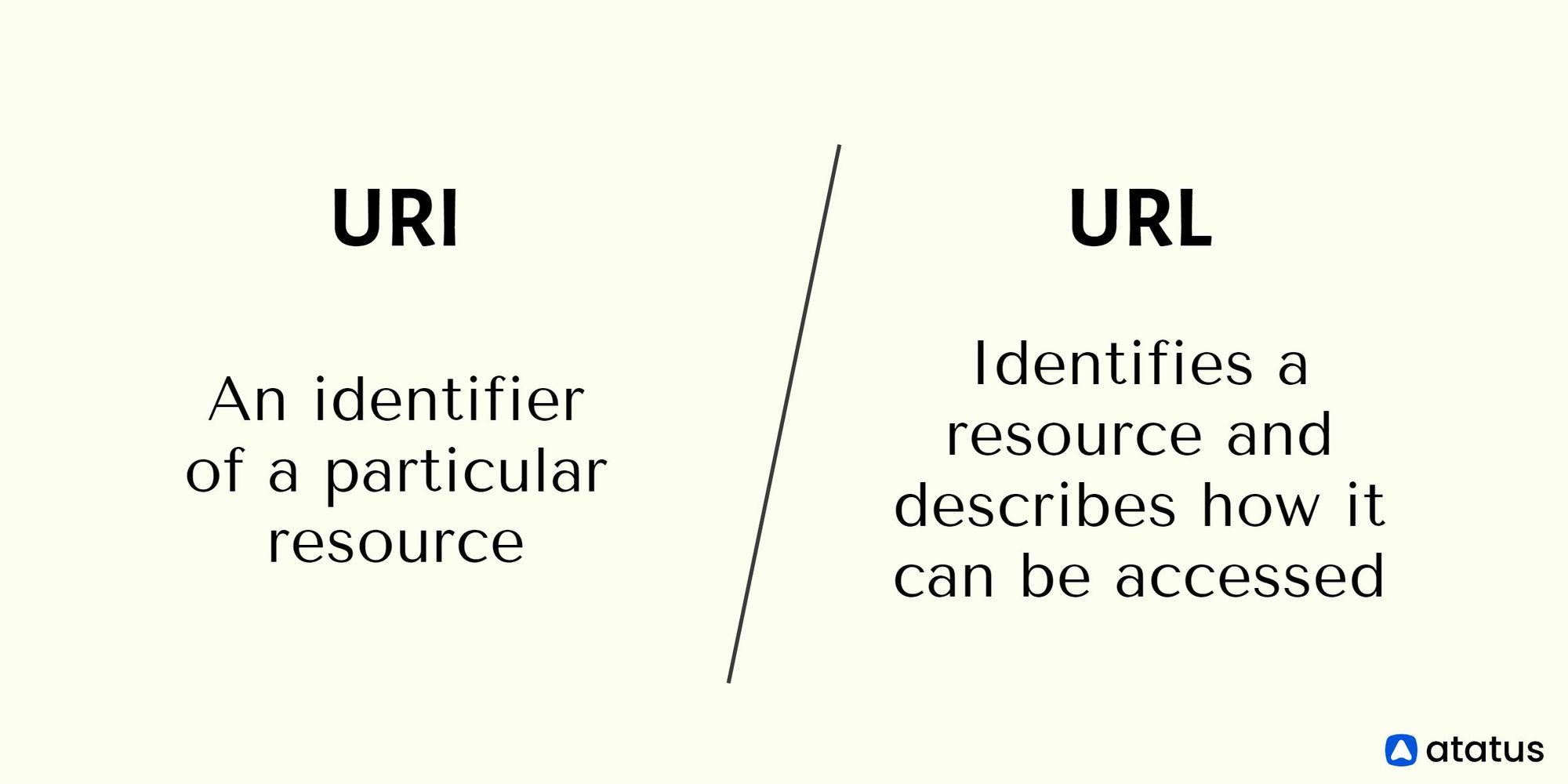
This difference can be explained using the comparison of a person's name and address. Because it identifies the person, the name in this instance serves as the URI. It doesn't specify where the person lives or how to locate them, though. The address or URL is necessary for this.
A URI can also be used to identify and distinguish between different file and resource types, including HTML and XML. However, URLs are only useful for locating and identifying websites and other resources.
Summary
The semantic web needs a Uniform Resource Identifier because it eliminates ambiguity. A URI, which uses a standard syntax, searches both the name and the location of a resource or file. Each filename and path is represented by a certain string of characters.
A method for other systems to access resources across the World Wide Web or a network is provided by URI. Web browsers and P2P (Peer to Peer) file-sharing applications use it to locate and download files. New file types can be defined using URI without affecting existing files.
Also Read:
Digital Experience Monitoring (DEM)
Monitor Your Entire Application with Atatus
Atatus is a Full Stack Observability Platform that lets you review problems as if they happened in your application. Instead of guessing why errors happen or asking users for screenshots and log dumps, Atatus lets you replay the session to quickly understand what went wrong.
We offer Application Performance Monitoring, Real User Monitoring, Server Monitoring, Logs Monitoring, Synthetic Monitoring, Uptime Monitoring, and API Analytics. It works perfectly with any application, regardless of framework, and has plugins.
Atatus can be beneficial to your business, which provides a comprehensive view of your application, including how it works, where performance bottlenecks exist, which users are most impacted, and which errors break your code for your frontend, backend, and infrastructure.
If you are not yet an Atatus customer, you can sign up for a 14-day free trial.
