How Can Enterprise Organizations Reduce DevOps Tool Sprawl?

The world revolves around DevOps tools. DevOps engineers go insane when they have too many tools. The first statement is correct. Also, the second one.

Tooling that helps in the automation of software development and infrastructure provisioning workflows and pipelines is critical for both the engineers who create the automations and the developers who use the automated workflows on a daily basis.
Great tools simplify the job of both DevOps Engineers and software developers, are simple to use, don't require a lot of effort to manage, and are simple to incorporate into an existing tooling ecosystem. However, the reality is that DevOps tool sprawl is a very real issue.
Let's get started!!!
We will go over the following:
- What's the Big Deal about Tool Sprawl?
- Solving the Tool Sprawl Problem
- Roadmap for Tool Consolidation
- Preventing DevOps Tool Sprawl
What's the Big Deal about Tool Sprawl?

Digital complexity Continues to Rising
In just a few years, digital transformation has gone from a "nice to have" to a critical engine of strategic corporate growth and productivity. The pressure is on for company leaders to make rapid and meaningful success in digital efforts before falling behind competitors in this age of "always-on, always connected."
Underperforming legacy technology is considered a key obstacle to innovation, agility, and performance. That's why businesses are hurrying to embrace digital, but the end result is a disjointed collection of scattered systems and processes that don't communicate properly.
Worse, in the modern digital world, which is inhabited by an increasing volume of clouds, networks, servers, containers, virtual environments, applications, IoT endpoints, and more, complexity is much greater.
The most effective method of IT Operations gives IT leaders the insight and control they need over their systems, allowing them to catch and correct problems before they create downtime, as well as enable innovation and growth. Legacy techniques and tool sprawl, on the other hand, provide a significant challenge, effectively tying one arm behind the CIO's back.
According to Gartner, by 2020, over 80% of IT operations tools and procedures in IoT initiatives would be unable to meet requirements, resulting in low success rates, hence a fundamental shift in tooling is required now.
Legacy IT Monitoring is a Challenge
Part of the issue is that IT monitoring has always been considered as merely a utility rather than something that may provide value by improving IT service delivery, decision-making, and customer experience.
This antiquated attitude extends to what is monitored: availability and health are prioritised over performance and user experience. Technology investments are typically reactive, responding to problems rather than anticipating new requirements, such as the rollout of new applications.
Any attempts to update IT Operations support tools have been stymied by silos inside the IT department. Legacy metrics are rarely questioned, and accountability for new metrics is frequently delegated to these silos rather than IT leaders who may better align with business value.
It's fairly uncommon for organisations to have a culture of blindly following what has gone before, which keeps them in firefighting mode and unable to break free and become more strategic.
Tool sprawl is endemic on top of all of this, and it's tied to the cultural difficulties mentioned earlier. Reactive, fragmented techniques simply serve to encourage the creation of redundant monitoring tools, none of which provide clear visibility across the entire business.
These investments may have been undertaken in good faith to address the growing complexity of IT systems, but they have simply served to exacerbate the problem they were supposed to solve.
Innovation has Slowed Down
A DevOps team with tool sprawl is more likely to have poor observability since data from different tools isn't always connected. As a result, their capacity to identify abnormal system activity and locate the source of a fault is reduced, and their Mean Time To Detection (MTTD) and Mean Time To Repair (MTTR) times increase.
Additionally, having too many tools can cause your DevOps team to work harder. Toil, according to Google's SRE organisation, is "labour associated with running a production service that is manual, repetitive, automatable, tactical, devoid of enduring value, and scales linearly as the service expands."
Tool sprawl causes toil by requiring DevOps engineers to switch between a plethora of tools that may or may not be effectively integrated. This reduces the amount of time spent doing valuable and productive work during the day, such as coding.
Finally, tool sprawl lowers the scalability of your system. This is a significant roadblock for companies looking to expand. They can't scale their application, which means they'll have a hard time growing their user base and adding new features.
Lack of Integration
A well-integrated toolchain is essential for a successful DevOps process. When tool sprawl goes uncontrolled, it might lead to a collection of tools that aren't well integrated. DevOps teams are compelled to work around this by introducing ad-hoc solutions that reduce the toolchain's robustness and reliability.
Your DevOps architecture's rate of innovation and modernization will be slowed as a result. Engineers are afraid of breaking the existing infrastructure, thus they are hesitant to undertake potentially useful modifications.
Data silos are another issue brought on by tool sprawl. It can be difficult to pool data if separate DevOps engineers utilise their own dashboards and monitoring systems. This limits the system's total visibility and, as a result, the level of insight available to the team.
Collaboration is also hampered by data silos. They can't meaningfully communicate if each operations team is looking at a different data source and using their own monitoring tool.
Reduced Team Productivity
Engineers create tools to boost productivity rather than decrease it. However, having too many has the opposite effect.
Engineers' creative processes can be substantially hampered by tool sprawl. Forced to sift through a tangle of unstandardized and poorly connected tooling disrupts their flow, limiting their capacity to address problems. As a result, they are less effective as engineers, and the team's operational excellence suffers.
A toxic culture generated by a lack of collaboration and communication between different elements of the organisation is another hindrance to productivity. We observed how data silos led to a lack of team collaboration in the previous section.
The worst-case scenario is that it leads to a blame culture. Each member of the team, only aware of the information relevant to their component of the system, tries to justify it and treat their point of view as correct.
As a result, they overlook other aspects of the image and blame non-aligned team members for errors.
Solving the Tool Sprawl Problem

Think About all of Your Possibilities
One strategy for teams to avoid tool sprawl is to think more thoroughly about the benefits and drawbacks of introducing a new tool. Tools include both functional and non-functional elements. Many teams are persuaded to adopt a new tool because of the functional advantages it provides. Allowing the team to visualise data or boosting some aspect of observability are two examples.
The non-functional components of the instrument are something they rarely consider. Performance, upgradeability, and security features are just a few examples.
If a tool were a voyage, the destination would be the function, and the route would be the non-functional components. Many teams are like oblivious travellers that say things like "wake me up when we get there" while ignoring potential dangers along the route.
Instead, they must think like ship captains, navigating the complexities of their new equipment with foresight and eliminating possible issues before the ship sinks.
Teams must consider operational difficulties before adopting a tool into their toolchain. These can range from the amount of personnel required to maintain the tool to the repository where new versions can be found.
Detoxing the Toolchain
Another technique for reducing tool sprawl is to use "all-in-one" tools that allow teams to get greater results with less equipment. According to a recent study, having a platform vendor with numerous monitoring, analytics, and troubleshooting capabilities are preferable.
Atatus is an excellent example of such a platform. It's an observability and monitoring solution that analyses and extracts insights from many data sources. Log analytics allows you to avoid human restrictions and consume data from all throughout the system.
Atatus can also be integrated with a variety of third-party platforms and solutions. These include Slack, Asana, VictorOps, GitLab, Datadog, BigPanda, and more.
While we don't recommend limiting your toolchain to just one, a platform like Atatus can help prevent tool sprawl before it becomes a problem.
Roadmap for Tool Consolidation
There is hope for individuals who are now battling out-of-control tool sprawl. The tool consolidation roadmap demonstrates how to transition from a fragmented or ad hoc toolchain to a modern toolchain with few superfluous components. The roadmap is divided into three sections.
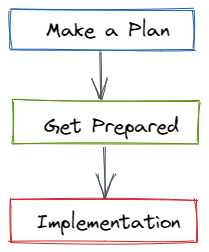
Phase 1: Make a plan
Before a team begins tool consolidation work, they must first outline what they will perform. The team must first determine the present toolchain's architecture, as well as the costs and advantages to tool users.
Then they must decide what they want to get out of the roadmap as a group. Each team member will have their own desired outcome, and the resulting toolchain must accommodate everyone's needs.
Finally, the group should create a timeline that details the tool consolidation phases and how long they will take to complete.
Phase 2 – Get Prepared
Preparation is the second phase. This requires the creation of a detailed list of use cases and their mapping to a list of potential solutions by the team. The goal of this phase is to figure out what high-level requirements the final solution must meet and flesh them out with a variety of use cases.
The DevOps team, for example, may desire greater visibility into database instance performance. They can then build use cases around it, such as "as an engineer, I'd like to see how much CPU an instance is using."
The team can then do research and inventory to identify potential solutions to enable those use cases.
Phase 3 – Implementation
Finally, the team will be able to put its strategy into action. This process entails a number of different elements. After ensuring that the chosen solution best supports their goals, the team must deploy it.
This requires testing to ensure that it functions as expected before deploying to production. Any alerting and event management tactics described in the plan must be implemented using the solution.
Atatus has alerts. This allows teams to be alerted about anomalies without having to explicitly establish a threshold.
Last but not least, the team must document its findings in order to influence future improvements, as well as train all members of the team on how to make the most of the new solution.
Preventing DevOps Tool Sprawl
The amount of effort spent on choosing the correct tool against the instrument's perceived value was previously unspoken. Is the time and effort it takes to choose a tool worth it, given the problem it solves?

Your toolchain is likely complex and fragmented across planning, development environments, integration and security testing, performance and load testing, artifact production and distribution, configuration management, and operational monitoring due to the vast ecosystem of tools.
Given that you must devote a significant amount of time to selecting and evaluating each tool, it makes sense to minimise the number of tools you have and look for vendors that can tackle a number of related difficulties in a single tool. This not only cuts down on time spent selecting and validating tools but also keeps DevOps tool sprawl to a minimum.
And it's not that having more tools is bad; it's just that having more tools means there's more integration surface between them, which often requires special glue code to make them work together. And it's this glue code that's to blame for a lot of outages and broken pipelines, as well as a lot of technical debt.
Wrapping Up!!!
We've learnt not to prioritise what we want over how we get it. Consider how your toolchain works and how much complexity you can take, then look for ways to simplify it, such as integrating security scanning of new builds with version control, so that merged code is verified automatically from a single DevOps tool.
Monitor Your Entire Application with Atatus
Atatus is an Observability Platform that lets you review problems as if they happened in your application. Instead of guessing why errors happen or asking users for screenshots and log dumps, Atatus lets you replay the session to quickly understand what went wrong.
We offer Application Performance Monitoring, Real User Monitoring, Serverless Monitoring, Logs Monitoring, Synthetic Monitoring, Uptime Monitoring, and API Analytics. It works perfectly with any application, regardless of framework, and has plugins.
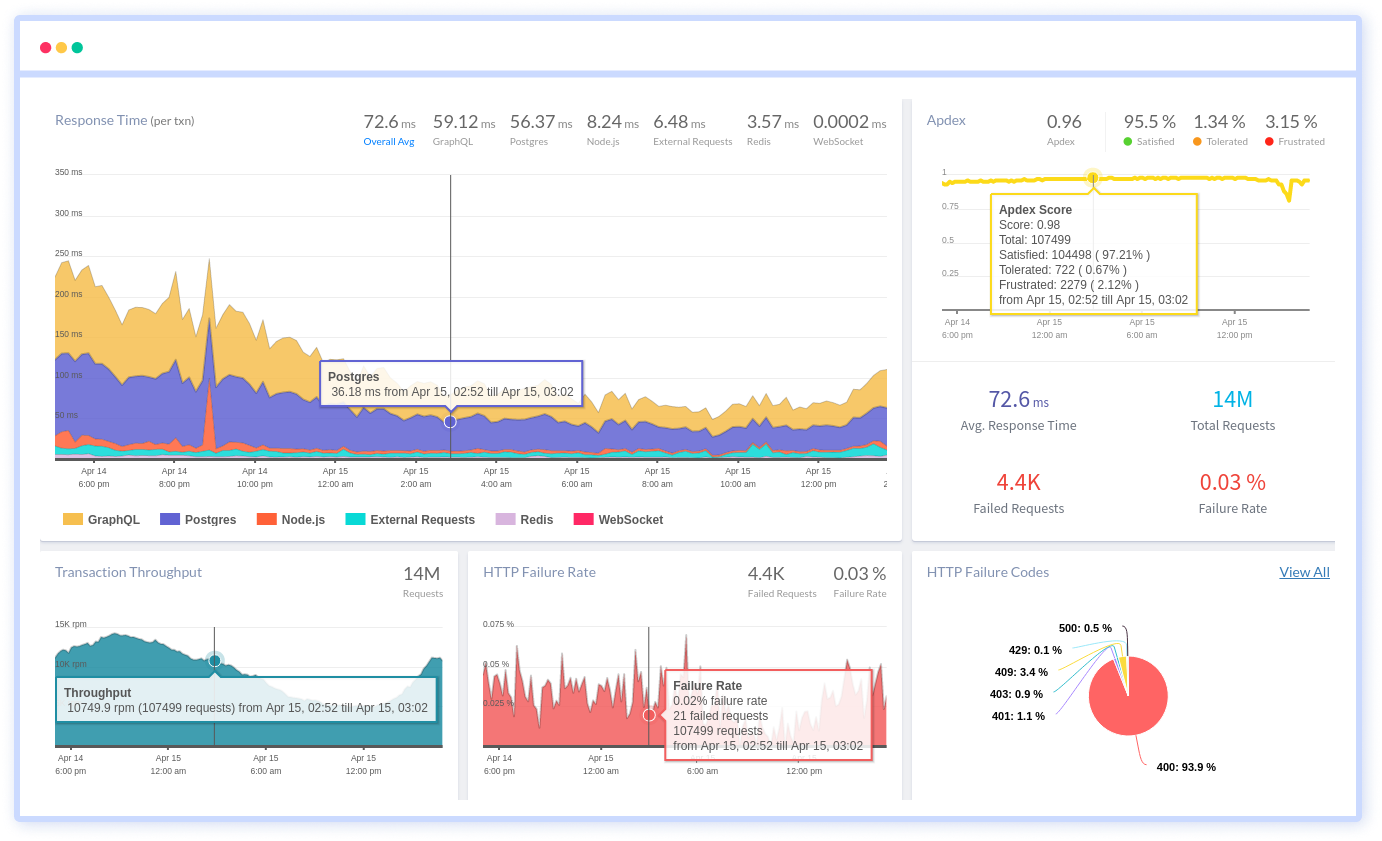
Atatus can be beneficial to your business, which provides a comprehensive view of your application, including how it works, where performance bottlenecks exist, which users are most impacted, and which errors break your code for your frontend, backend, and infrastructure.
If you are not yet a Atatus customer, you can sign up for a 14-day free trial .
#1 Solution for Logs, Traces & Metrics
![]() APM
APM
![]() Kubernetes
Kubernetes
![]() Logs
Logs
![]() Synthetics
Synthetics
![]() RUM
RUM
![]() Serverless
Serverless
![]() Security
Security
![]() More
More