
According to ZK Research, 90% of MTTR is spent attempting to determine whether or not there is a problem. Longer MTTR can also be caused by incorrect diagnosis or poor remedies. With the purpose of decreasing future downtime, a high MTTR should urge IT managers to rethink their approach to troubleshooting, taking into account the full lifecycle, from how they monitor and detect to how they diagnose and resolve.
We will cover the following:
- What is Mean Time To Repair (MTTR)?
- How to Calculate MTTR?
- How to Improve MTTR?
- How to Use MTTR?
- Why is MTTR Important?
What is Mean Time To Repair (MTTR)?
The Mean Time To Repair (MTTR) is a metric used by maintenance departments to determine how long it takes to diagnose and fix broken equipment on average. It provides a picture of the maintenance team's ability to respond to and repair unplanned outages. It's vital to remember that the MTTR calculation takes into account the time from the start of the incident to the return of the equipment or system to production.
It's a critical failure metric that measures how long it takes to repair and return a component or system to working order. As a result, MTTR is a key indicator of an organization's ability to maintain its systems, equipment, applications, and infrastructure, as well as its efficiency in repairing such equipment when an IT outage occurs.
The MTTR begins when a failure is found and continues until service is restored to end-users, including all diagnostic, repair, testing, and other procedures. A low MTTR suggests that a component or service may be repaired quickly and that any IT issues that arise as a result will likely have a minimal impact on the business. A high MTTR indicates that a device failure could cause a major service interruption, which would have a greater impact on the business.
When deciding whether or not to repair or replace an asset, an MTTR analysis is also useful. If a piece of equipment becomes more difficult to maintain as it ages, it may be more cost-effective to replace it. The MTTR history can also be utilised to estimate new equipment or system lifecycle costs.
How to Calculate MTTR?
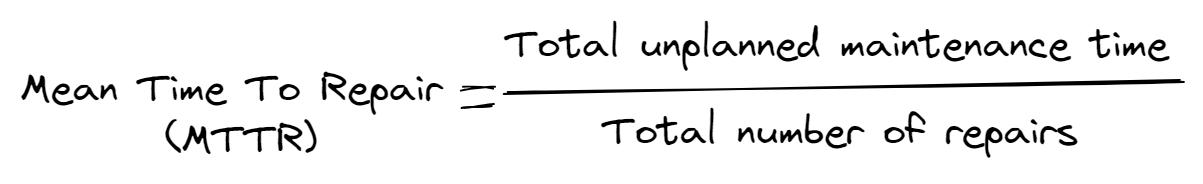
In the MTTR calculation, the total unplanned maintenance time is divided by the total number of repairs. The most frequent way to express MTTR is in hours. Keep in mind that MTTR requires that tasks are completed in a specific order and by trained maintenance personnel.
For example, if a pump fails five times every single workday and you spend an hour on each failure, your MTTR is 15 minutes (60 minutes / 5 = 12 minutes).
Another example may be an asset that has ten outages in a 90-day period. The outage times (from the time the asset is discovered to the time it is restored to production) are 24, 51, 79, 56, and 12 minutes, respectively. For this 90-day period, the MTTR is 44 minutes. That is the average time from when an issue is discovered to when the asset is recovered.
When calculating MTTR, there are two assumptions to keep in mind:
- The severity of each failure varies in most circumstances, thus although some failures may take days to repair, others may only take minutes. As a result, MTTR provides an average of what to expect.
- Every case of failure must be handled by qualified and properly trained maintenance personnel who follow standardised processes. This assures that the outcomes are correct.
Some of the greatest maintenance teams in the world are believed to have an MTTR of less than five hours, but because of the large number of variables, benchmarking your facility's MTTR with another's data is nearly impossible. The sort of asset you're assessing, its age, criticality, maintenance staff training, and so on all effect MTTR.
How to Improve MTTR?
The Mean Time To Repair (MTTR) is regarded as a key performance indicator (KPI). As a result, maintenance teams should try to improve it at all times. The advantages of lowering MTTR are self-evident: less downtime equals more consistent output, happier customers, and lower maintenance expenses.
Understanding the four stages of MTTR and taking efforts to lessen each of them is the best place to start.
- Identification
The time span between when a failure happens and when a technician notices the problem. Wireless sensors and alarm systems are excellent solutions to reduce the MTTR identification time period. - Knowledge
The time period following the discovery of a failure but before the initiation of repairs. The most time-consuming aspect of MTTR is usually determining or diagnosing the condition. - Fix
The amount of time it takes to truly fix the problem. Standardizing procedures to instruct well-trained professionals who are assigned to solving the problem can help reduce the time it takes to fix an issue. - Verify
The amount of time it takes to verify that the applied remedy is effective. A real-time monitoring system is a useful tool for gathering data and reporting fast to demonstrate that the remedy is working.
The most time-consuming component of MTTR is determining the cause of the failure. In reality, figuring out what caused the asset or system to fail takes up 80% of the MTTR. It will be critical to be able to immediately narrow down possible causes of failure by documenting, managing, and having a machine ledger on hand with things like maintenance schedules, repaired/replaced components, and history from equipment monitoring systems.
How to Use MTTR?
The Mean Time to Repair is commonly employed as a measure of a system's health and the effectiveness of an organization's repair efforts.
The MTTR can be used to assess operational stability, resource availability, and the value of a department, repair team, or service. It's also useful information for making data-driven judgments and improving resource allocation.
A high Mean Time to Repair could indicate that something is wrong with the repair procedure or the system itself.
Process difficulties that may be identified by a higher than normal MTTR include the following:
- Delays in detecting and notifying issues
- Diagnoses are difficult to come by
- Parts or resources are not readily available
- There is a demand for further technician training
- Processes are not well documented
However, a high MTTR for a certain asset could indicate an underlying issue with the system, such as age, which means the time it takes to repair the equipment is increasing or unusually high.
Noticing when the MTTR for a certain item exceeds a certain threshold may lead to a conversation about whether it is more cost-effective to repair the item or simply replace it, therefore saving money both now and in the future.
Why is MTTR Important?
Since MTTR appears to analyse how long business systems are down, it's a good predictor of the severity of an IT outage. When IT issues occur, the higher the MTTR of an IT team, the more likely the organisation will experience severe downtime, thereby causing business disruptions, customer discontent, and financial loss.
Failures in technology are unavoidable. The MTTR indicates how quickly and efficiently a company may expect to respond to a breakdown and resume normal operations. Lower MTTR ratings, on the whole, indicate a healthy computing environment and a positive IT function.
Conclusion
Incident response times are becoming increasingly crucial as enterprise IT is under pressure to improve service levels while lowering costs. While MTTR isn't a magic figure, it is a good sign of a company's capacity to respond to and resolve potentially costly issues swiftly.
Any tech-centric company must thoroughly know MTTR and its duties due to the direct impact of system downtime on productivity, profitability, and customer confidence.
Also Read:
Monitor Your Entire Application with Atatus
Atatus is a Full Stack Observability Platform that lets you review problems as if they happened in your application. Instead of guessing why errors happen or asking users for screenshots and log dumps, Atatus lets you replay the session to quickly understand what went wrong.
We offer Application Performance Monitoring, Real User Monitoring, Server Monitoring, Logs Monitoring, Synthetic Monitoring, Uptime Monitoring and API Analytics. It works perfectly with any application, regardless of framework, and has plugins.
Atatus can be beneficial to your business, which provides a comprehensive view of your application, including how it works, where performance bottlenecks exist, which users are most impacted, and which errors break your code for your frontend, backend, and infrastructure.
If you are not yet a Atatus customer, you can sign up for a 14-day free trial .


