11 Best Practices for Designing RESTful API

Although the RESTful Application Programming Interface (API) was first established in the year 2000, there are currently no set guidelines or standards for API development. Developers have experimented with many methods to improve REST API solutions throughout the years. Some of them were successful, while others were unsuccessful.
APIs that are poorly developed is difficult to maintain over time and are prone to failure. Hackers looking for sensitive data may target such APIs, making them subject to security issues.
Improved developer experience, faster documentation, and increased API adoption are all advantages of a well-designed API. But what goes into creating a good API?

In this blog, I'll go over some RESTful API design best practices.
- Learn the Basics of HTTP
- Use JSON
- Versioning
- Documentation
- HTTP Response Status Codes
- Filtering, Sorting, and Searching
- Errors
- Authentication
- SSL (Secure Sockets Layer)
- Avoid Using Verbs in the URIs
- Encode POST, PUT, and PATCH bodies in JSON
#1 Learn the Basics of HTTP
You should know the basics of the HTTP protocol if you want to construct a well-designed REST API. We are confident that this will assist you in making better design selections.
We found the MDN web documents' Overview of HTTP to be an excellent resource for this. However, in terms of REST API design, here's a TL;DR version of HTTP applied to REST:
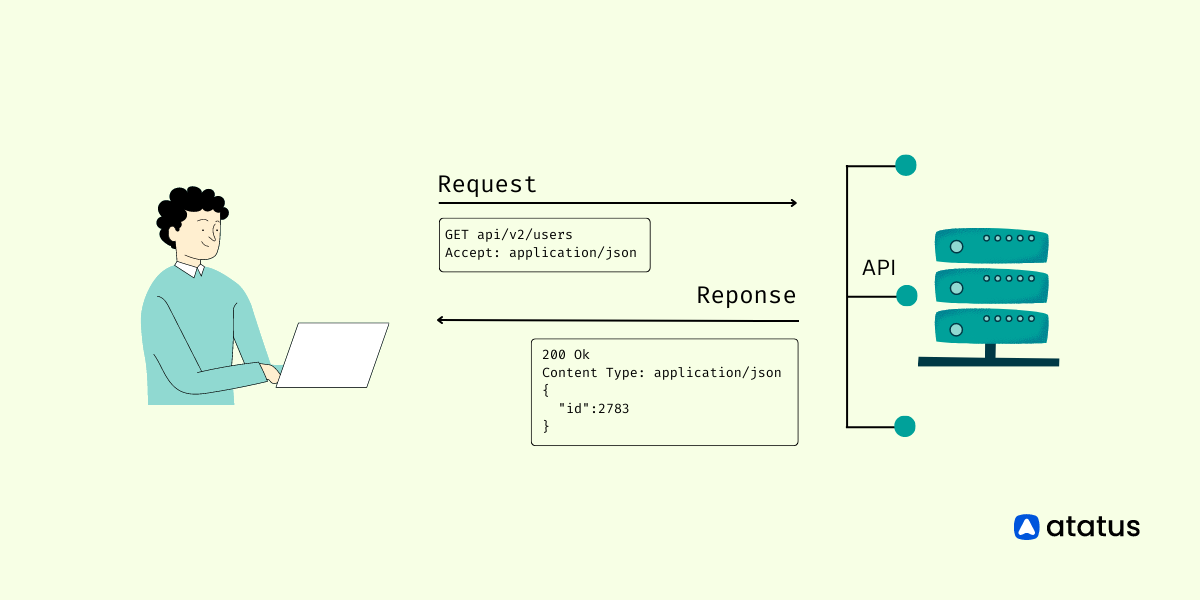
The most frequent HTTP verbs (or methods) are GET, POST, PUT, PATCH, and DELETE.
- Verbs correspond to CRUD activities at a high level: GET means read, POST means create, PUT and PATCH mean update, and DELETE means delete
- REST is resource-oriented, with each resource represented by a URI: /articles/
- GET /articles is an example of an endpoint, which is made up of a verb and a URI
- An endpoint can be thought of as a resource action. POST /articles, for example, may imply "create a new article"
The state of response is determined by its status code: 1xx indicates information, 2xx indicates success, 3xx indicates redirection, 4xx indicates client errors, and 5xx indicates server errors
Of course, you can use anything the HTTP protocol has to offer for REST API design, but these are the fundamentals, in my opinion.
#2 Use JSON
In today's world, JSON is the de facto standard for connecting with APIs. It is preferable over XML because it greatly decreases the payload, resulting in speedier data delivery. As a result, JSON should be used to communicate between the client and the server, and vice versa, in your REST APIs.
Note that REST is format-agnostic, meaning you can transmit data in any format you choose, including XML, HTML, JSON, and even custom formats.
You can set the Content-Type header of the response to application/json to ensure that your REST API communicates in JSON. Basically, your REST APIs should be able to return JSON data and receive JSON payloads.
#3 Versioning
The technique of managing changes to an API is known as API versioning. It's a good idea to keep your API up to date at all times. When creating REST-based APIs, keep in mind that change is unavoidable. To meet client needs, you may need to make a breaking modification to your API.
Versioning allows you to iterate more quickly while also preventing incorrect requests from reaching updated endpoints. It also helps to smooth over any big API version migrations by allowing you to keep offering older API versions for a while.
Whether an API version should be supplied in the URL or in the header is a point of contention. It should probably be in a header from an academic standpoint. However, the version must be included in the URL to ensure that the resources can be explored in a browser across versions as well as a more straightforward developer experience.
There is no such thing as a totally stable API. It's impossible to avoid change. It's how that transition is managed that matters. For many APIs, multi-month deprecation timelines that are well defined and published can be an appropriate strategy. It all boils down to what is reasonable in light of the API's business and potential users.
#4 Documentation
The documentation of an API is only as good as the API itself. The documents should be easy to find and open to the public. Before undertaking any integration effort, most developers will consult the documentation. When documents are concealed inside a PDF file or require authentication, they are not only difficult to locate but also difficult to search.
Complete request/response cycles should be demonstrated in the documentation. Pastable examples, such as links that can be pasted into a browser or curl examples that can be pasted into a terminal, are preferred. GitHub and Stripe are excellent at this.
You've committed to avoiding breaking things without warning after you've released a public API. Any deprecation timelines and details surrounding externally accessible API modifications must be included in the documentation. Updates should be sent out either a blog or a mailing list.
#5 HTTP Response Status Codes
This is a critical point to remember. This is arguably the most important thing you should take away from this article:
Your API's worst-case scenario is to send an error response with a status code of 200 OK.

There!!! I said it.
It's just a case of poor semantics. Instead, return a relevant status code that accurately indicates the error kind.
When a client sends a request to a server via an API, the client should receive feedback on whether the request succeeded, failed, or was incorrect. HTTP status codes are a set of defined codes that have different meanings depending on the situation. Always return the correct status code from the server.
Learn more about HTTP Status Codes.
#6 Filtering, Sorting, and Searching
It's best to keep the URLs for the base resources as short as possible. On top of the original URL, complex result filters, sorting criteria, and sophisticated searching can all be easily added as query parameters.
Let's take a closer look at these:
Filtering
For each field that implements filtering, use a separate query parameter. When using the /deals endpoint, for example, you might want to limit the results to only those that are currently available. A request like GET /deals?state=open might be used to do this. In this case, the state is a query parameter that acts as a filter.
Sorting
A generic parameter sort, like filtering, can be used to express sorting criteria. Allow the sort option to get a list of comma-separated fields, each with a potential unary negative to indicate descending sort order. Consider the following examples:
- GET /deals?sort=-priority - Returns a list of deals sorted by priority in descending order
- GET /deals?sort=-priority,created_at - Returns a list of deals in ascending priority order. Older deals are ordered first within a given priority.
Searching
Basic filters aren't always sufficient, and you'll need the capability of a full-text search. You might already be using ElasticSearch or another Lucene-based search engine.
Full-text search can be exposed on the API as a query parameter on the resource's endpoint when it's utilised as a technique for fetching resource instances for a given type of resource.
Let's take q. Search queries should be sent directly to the search engine, with API return in the same style as a regular list result.
By combining these, we may create queries such as:
- GET /deals?sort=-updated_at - Get deals that have been recently updated
- GET /deals?state=closed&sort=-updated_at - Retrieve deals that have been closed recently
- GET /deals?q=enterprise&state=open&sort=-priority,created_at - Get deals with the word 'enterprise' get the highest priority
If the URI becomes too long due to the addition of multiple query parameters in GET methods, the server may respond with a 414 URI. In the case of an HTTP status that is too long, params can be passed in the request body of the POST method.
#7 Errors
An API should give a helpful error message in a known consumable format, similar to how an HTML error page displays a useful error message to a visitor. An error should be represented in the same way that any other resource is represented, but with its own set of fields.
The API should always return HTTP status codes that are understandable. API errors are often divided into two categories:
- Client issues (400 series status codes)
- Server issues (500 series status codes)
At the very least, the API should ensure that all 400-series failures are represented as consumable JSON. This should be extended to the 500 series status codes if possible (i.e. if load balancers and reverse proxies can construct custom error bodies).
A JSON error body should include a meaningful error message, a unique error code (which can be looked up in the docs for more information), and maybe a thorough description for the developer. For anything like this, the JSON output representation would be:
{
"code": 4001,
"message": "Something bad happened",
"description": "More details about the error here"
}A field breakdown will be required for validation errors for PUT, PATCH, and POST requests. This is best handled by assigning a fixed top-level error code to validation failures and storing the particular issues in a separate errors field, as seen below:
{
"code": 4024,
"message": "Validation Failed",
"errors": [{
"code": 5432,
"field": "first_name",
"message": "First name cannot have fancy characters!"
},
{
"code": 5622,
"field": "password",
"message": "Password cannot be blank!"
}
]
}#8 Authentication
A stateless RESTful API should be used. This means that cookie or session authentication should not be used for request authentication. Instead, each request should include some form of authentication information.
The authentication credentials can be reduced to a randomly generated access token delivered in the user name field of HTTP Basic Auth by always using SSL. The beautiful thing about this is that it's totally browser explorable - if the server returns a 401 Unauthorized response code, the browser will simply display a prompt asking for credentials.
This token-over-basic-auth form of authentication is only suitable in circumstances when copying a token from an administration interface to the API consumer environment is practical. In the event that this isn't possible, OAuth 2 should be utilised to provide secure tokens to a third party. Bearer tokens are used in OAuth 2 and the underlying transport encryption is provided by SSL.
Since JSONP queries cannot convey HTTP Basic Auth credentials or Bearer tokens, an API that wants to support JSONP will require a third means of authentication. A particular query parameter called access token might be utilised in this circumstance. Note that utilising a query parameter for the token has a security risk because most web servers save query parameters in server logs.
For the record, all three techniques are simply methods for transporting the token across the API border. It's possible that the underlying token is identical.
#9 SSL (Secure Sockets Layer)
SSL should always be used. There are no exceptions.
If you want us to think again, then...

It's definitely No!!! No exceptions.
Your web APIs are now available from any location with an internet connection (like coffee shops, libraries, airports among others). Not every one of them is safe. Many don't encrypt their conversations at all, making them vulnerable to eavesdropping or impersonation if authentication credentials are stolen.
Another benefit of always using SSL is that guaranteed encrypted communications simplify authentication efforts. Instead of signing each API request, simple access tokens can suffice.
Non-SSL access to API URLs is something to be wary of. These should not be redirected to their SSL counterparts. Instead, throw a hard mistake. A badly configured client could accidentally leak request parameters across the unencrypted endpoint when an automated redirect is in place. A hard error ensures that this error is caught early and that the client is appropriately set up.
#10 Avoid Using Verbs in the URIs
Verbs should not be used in the URL to describe the action being done. Using verbs in your RESTful API is a terrible idea. The HTTP method is a verb: GET, PUT, POST, and DELETE, whereas a RESTful API's URL should always contain nouns. Furthermore, a RESTful URI must relate to a resource (noun), not an activity (a verb).
This rule does have a couple of exceptions. Verbs, for example, are used for specific activities, as illustrated in the following code snippet:
/login
/logout
/register#11 Encode POST, PUT, and PATCH bodies in JSON
If you've taken the strategy outlined in this post, you've adopted JSON for all API output. Let's look at JSON as an example of API input.
In the body of API requests, many APIs use URL encoding. URL encoding means that key-value pairs in request bodies are encoded using the same rules as data in URL query parameters. This is straightforward, well-liked, and effective.
However, there are a couple of difficulties with URL encoding that make it problematic. It has no idea what data kinds are. This causes the API to parse strings into numbers and booleans. It also has no idea what a hierarchical structure is.
Although various conventions can be used to create structure from key-value pairs (for example, inserting [ ] to a key to represent an array), nothing compares to JSON's innate hierarchical structure.
If the API is straightforward, we believe URL encoding will suffice. However, we would argue that it is incompatible with the output format.
If your API is JSON-based, you should use JSON for API input as well.
If a JSON encoded POST, PUT, or PATCH request is made, the Content-Type header must be set to application/json, else the API will return a 415 Unsupported Media Type HTTP response code.
And It’s a Wrap!!!
A good RESTful API design process involves not just working within technological limits, but also offering a positive user experience by making the API design easily accessible and useable. When there are so many possibilities, it can be tough to choose one technique, but each method has its own usability and significance. Simply evaluate your demands and select the option that best meets them.
Atatus API Monitoring and Observability
Atatus provide Powerful API Observability to help you debug and prevent API issues. It monitors the user experience and be notified when abnormalities or issues arise. You can deeply understand who is using your APIs, how they are used, and the payloads they are sending.
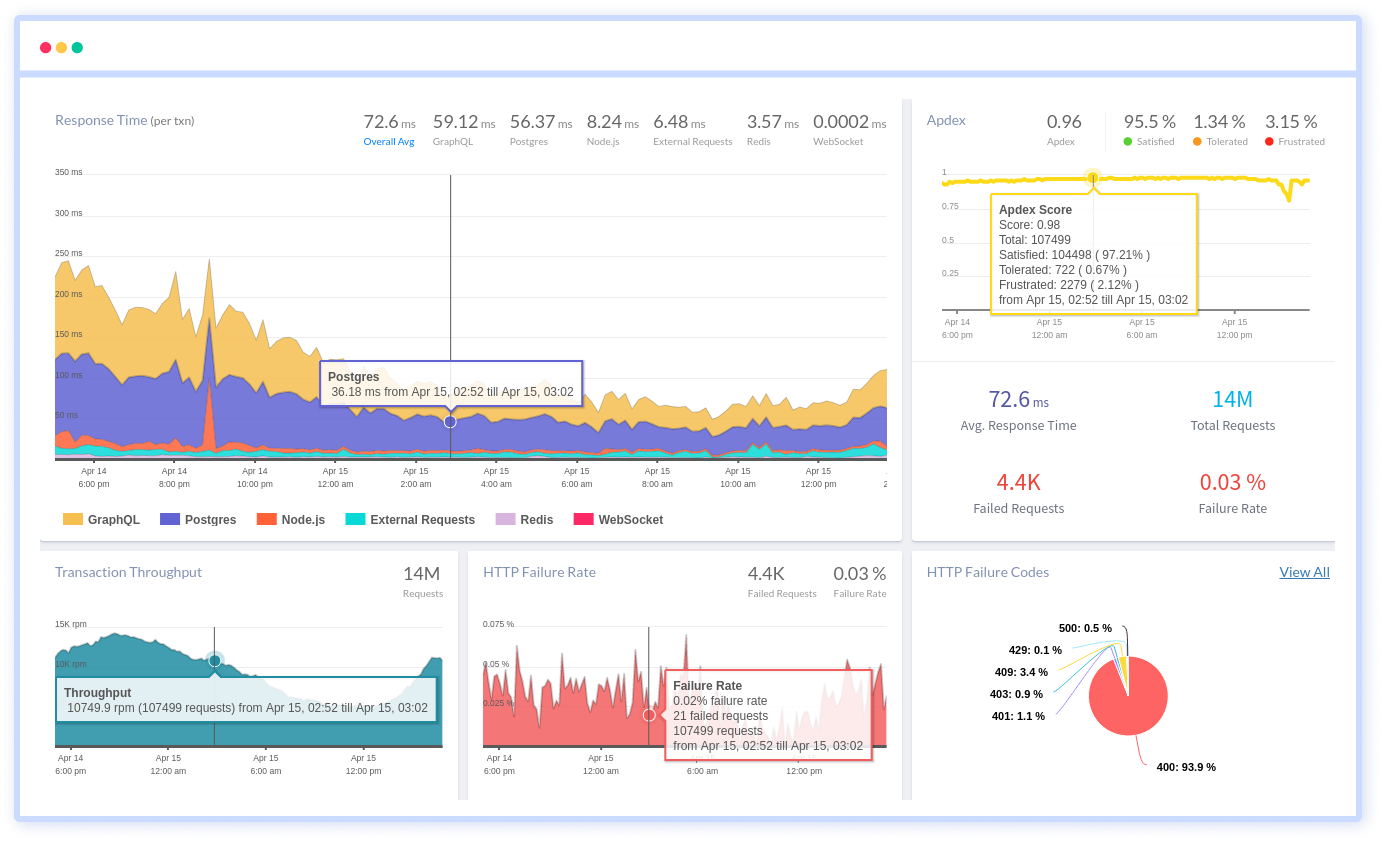
Atatus's user-centric API observability monitors the functionality, availability, and performance of your internal, external, and third-party APIs to see how your actual users interact with the API in your application. It also validates rest APIs and keeps track of metrics like latency, response time, and other performance indicators to ensure your application runs smoothly. Customers can easily get metrics on their quota usage, SLAs, and more.
#1 Solution for Logs, Traces & Metrics
![]() APM
APM
![]() Kubernetes
Kubernetes
![]() Logs
Logs
![]() Synthetics
Synthetics
![]() RUM
RUM
![]() Serverless
Serverless
![]() Security
Security
![]() More
More