Although the term "serverless computing" may appear contradictory at first, successful companies have long recognized the value of employing serverless technologies to streamline operations and lower costs. Serverless compute models, often known as serverless architecture, allow you to execute important user-defined functions using cloud-native features. Organizations are now using serverless computing to build agile ecosystems that improve cloud-native toolkits.
We will cover the following:
- What is Serverless?
- An Overview of Serverless Architecture
- How does Serverless Computing Work?
- Advantages and Disadvantages of Serverless Computing
- Use Cases for Serverless
What is Serverless?
Serverless computing is a design and deployment paradigm for event-driven applications in which computing resources are given as scalable cloud services. In typical application deployments, the server's computing resources are fixed and recurrent costs, regardless of how much computational work the server is doing.
The cloud user just pays for service utilization in a serverless computing deployment; there are no idle downtime costs. Instead of eliminating servers, serverless computing emphasizes the idea that computing resource considerations can be pushed to the background throughout the design process.
Since the actual hardware and infrastructure required are all maintained by the provider, developers may plugin code, create backend applications, create event-handling routines, and process data without worrying about virtual machines (VMs), servers, or the underlying compute resources.
Serverless computing, also known as serverless cloud computing, function as a service (FaaS), or runtime as a service (RaaS), is frequently associated with the NoOps movement.
Serverless transfers all management responsibilities for backend cloud infrastructure and operational tasks to the cloud provider, including provisioning, scheduling, scaling, patching, and more. Developers will have more time to concentrate on and improve their front-end application code and business logic as a result of this.
An Overview of Serverless Architecture
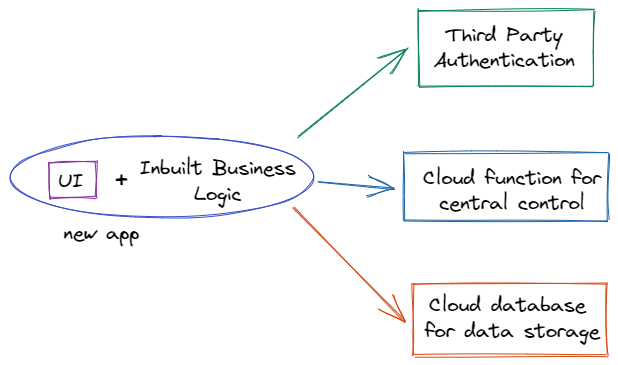
Serverless requires the cloud provider to manage both the cloud infrastructure and application scaling. Serverless applications are placed in containers that start up as soon as they're called.
Users prepurchase units of capacity in an Infrastructure-as-a-Service (IaaS) cloud computing paradigm, which means you pay a public cloud provider for always-on server components to operate your applications.
During periods of high demand, the user is responsible for scaling up server capacity and scaling down when that capacity is no longer required. Even when an application isn't in use, the cloud infrastructure that supports it is up and running.
On the other hand, the serverless architecture allows applications to be started only when they are required. The public cloud provider dynamically allocates resources for event-driven application code.
Once the code has completed its execution, the user is no longer charged. Serverless frees developers from routine and menial activities associated with application scalability and server provisioning and the cost and efficiency benefits.
Routine operations such as operating system and file system maintenance, security patches, load balancing, capacity management, scaling, logging, and monitoring are all offloaded to a cloud services provider with serverless.
A serverless application can be built from the ground up, or a hybrid solution combining serverless and traditional microservices components can be created.
How does Serverless Computing Work?
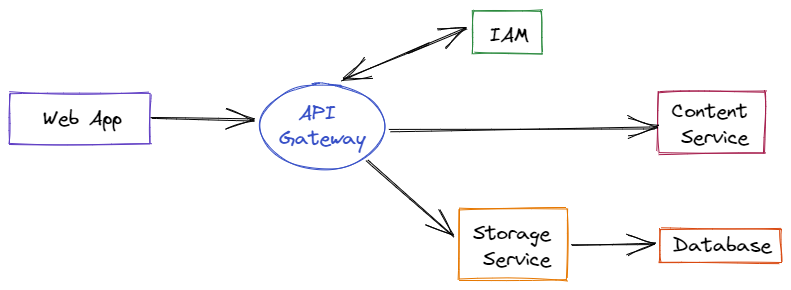
Developers don't have to worry about managing cloud machine instances using serverless computing. Instead, users can run code on cloud servers without having to worry about configuring or maintaining them. Instead of pre-purchased units of capacity, pricing is based on the real quantity of resources required by an application.
When developers put their applications on cloud-based virtual servers, they must typically set up and maintain those servers, install operating systems, monitor them, and keep the software up to date.
A developer can construct a function in his or her preferred programming language and submit it to a serverless platform using the serverless approach. The cloud service provider is in charge of managing the infrastructure and software, as well as mapping the function to an API endpoint and transparently scaling function instances on demand.
Advantages and Disadvantages of Serverless Computing
The following are some of the advantages of serverless computing:
- Cost-effective
Users and developers only have to pay for the amount of time their code runs on a serverless compute platform. They are not obligated to pay for virtual computers that are not in use. - Developer Productivity
Instead of dealing with servers and runtimes, developers can focus on writing and developing applications. - Simple to Use
Instead of weeks or months, developers may deliver applications in hours or days. - Scalability
When the code isn't running, cloud providers handle the scaling up and spinning down.
The following are some of the disadvantages of serverless computing:
- Debugging is More Challenging
It's difficult to gather the data needed to debug and correct a serverless function because each time it spins up, it creates a new version of itself. - Inefficient
Long tasks can sometimes be substantially more expensive than running a workload on a virtual machine or dedicated server. - Latency
The time it takes for a scalable serverless platform to handle a function for the first time, often known as a cold start, is longer. - Vendor Lock-in
Switching cloud providers can be problematic because the delivery of serverless services differs from one vendor to the next.
Use Cases for Serverless
Serverless architecture is well-suited for use cases involving microservices, mobile backends, and data and event stream processing due to its unique set of attributes and benefits.
- API Backends
In a serverless platform, any action can be converted into an HTTP endpoint that can be consumed by web clients. When these activities are enabled for the web, they are referred to as web actions. Once you have your web actions, you can put them together into a full-featured API using an API gateway, which adds security, OAuth support, rate restriction, and custom domain support to your API. - Data Processing
Serverless is well-suited for operations such as data enrichment, transformation, validation, and cleansing, as well as PDF processing, audio normalization, picture processing, optical character recognition (OCR), and video transcoding. - Massively Parallel Compute
Any form of embarrassingly parallel task, with each parallelizable task resulting in one action invocation, is a solid use case for a serverless runtime. Data search and processing (particularly Cloud Object Storage), Map operations, and web scraping are just a few examples of tasks: business process automation, hyperparameter tuning, Monte Carlo simulations, and genome processing. - Serverless and Microservices
Supporting microservices architectures is the most popular use case for serverless today. The microservices approach emphasizes the creation of small services that each perform a single task and communicate with one another via APIs. While microservices can be constructed and run using PaaS or containers, serverless has gained momentum because of its benefits of little code, inherent and automated scaling, rapid provisioning, and a pricing strategy that does not penalize idle capacity. - Stream Processing Workloads
The combination of managed Apache Kafka, FaaS, and database/storage provides a solid platform for building real-time data pipelines and streaming applications. These architectures are well-suited to working with various data stream ingestions such as IoT sensor data, application log data, financial market data, and business data streams.
Conclusion
Serverless computing can help any industry, from finance to education to government. This means that sooner rather than later, your employees and customers will need serverless solutions.
Serverless computing is the way to save resources, increase efficiency, and promote productivity for those wishing to build event-based systems fast and efficiently.
Also Read:
Containers-as-a-Service (CaaS)
Atatus API Monitoring and Observability
Atatus provides Powerful API Observability to help you debug and prevent API issues. It monitors the user experience and is notified when abnormalities or issues arise. You can deeply understand who is using your APIs, how they are used, and the payloads they are sending.
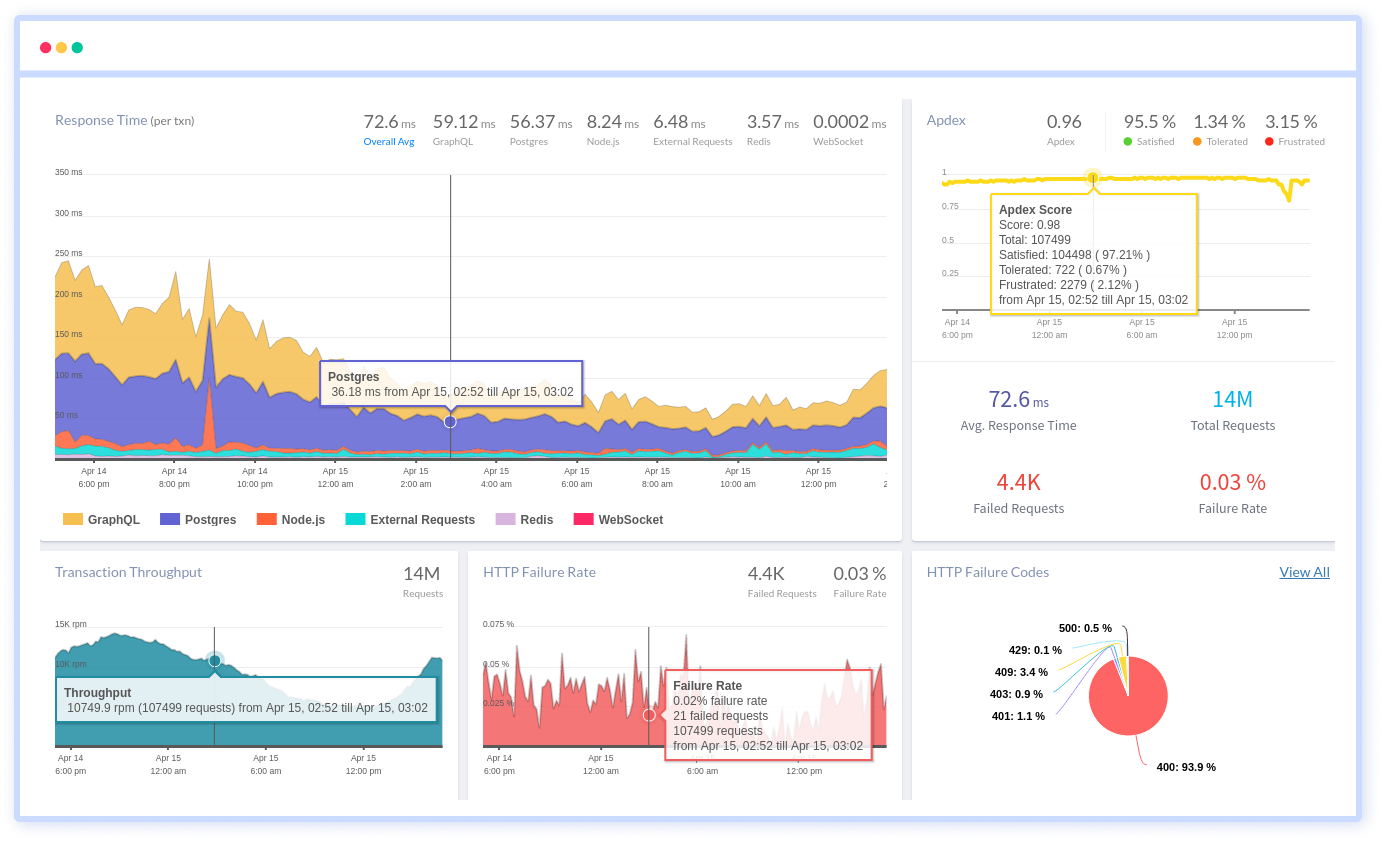
Atatus's user-centric API observability monitors the functionality, availability, and performance of your internal, external, and third-party APIs to see how your actual users interact with the API in your application. It also validates rest APIs and keeps track of metrics like latency, response time, and other performance indicators to ensure your application runs smoothly. Customers can easily get metrics on their quota usage, SLAs, and more.



