Structured logging is a part of a bigger initiative that will allow us to lower the Mean Time To Resolve (MTTR), helping developers to resolve problems more quickly when outages occur.
It's critical to have improved observability to maintain these systems effectively. Data from proper monitoring (metrics), event logs, and tracing for request scope information can all help us better understand what is occurring in the system.
Logs, which are often the first and busiest point of interaction, give the clearest picture of what occurred within the system of all these. The backend is considerably simpler to comprehend, manage, and troubleshoot when there are good logs. It would be extremely difficult to comprehend what was happening if there were no logs or if the logs were inaccurate.
We will go over the following:
- What is Structured Logging?
- Importance of a Structured Logging Format
- What Data is Included in Structured Logs?
- Structured, Unstructured, and Semi-structured Log Differences
- Benefits of Structured Logging
- Why is Structured Logging Important?
What is Structured Logging?
Structured logging is the process of giving application logs a standardized, predetermined message format that enables them to be handled as data sets rather than text. The goal of structured logging is to take an application log that is now supplied as a string of text and turn it into an easy-to-search and analyze relational data collection.
Structured logging organizes logged data to make it simple to search, filter, and process for more sophisticated analytics. JSON is the preferred format for structured logging, however other forms are also acceptable. The best practice is to provide structured logging using a logging framework that can interface with a log management solution and supports custom fields.
Structured, semi-structured, and unstructured logging all fall under a broad category, each having its advantages and difficulties. Structured logs are simple to parse in your log management system but challenging to use without a log management solution. Unstructured and semi-structured logs are simple to read by humans but can be challenging for machines to extract.
Importance of a Structured Logging Format
Teams may ensure that logs will be seamlessly ingested and interpreted by a log management tool by organizing the logs. However, the tool must accept JSON files.
One of the most significant differences between manually reading unstructured logs and employing a log management tool is this. Unstructured logs have less value when viewed with log management software because they are text-based. Additionally, these restrictions won't matter as much if a log file is inspected line by line.
These logs can still be a problem, particularly when dealing with large amounts of data. Data logging that is structured helps to avoid problems that can occur when managing log data on a large scale.
What Data is Included in Structured Logs?
Logs are only as valuable as the data they contain. Dashboards, graphs, charts, algorithm analysis, and any other helpful information that may be used to assess environmental health are all produced using the data included in an event.
Searching for particular events is more effective because of these structured logs. Structured logs can contain any amount of data pieces in a single event when using parser applications like log analysis tools.
Here are some examples of data that can be added to an event:
- Date and time of the event
- The type of triggered action (e.g., informational, critical, warning, error, etc)
- Where the triggered event occurred (e.g., an API endpoint or running application)
- The event's description (e.g., a credit card failure could be logged to detect potential fraud)
- A unique event ID
- The customer ID or username
- Protocol used to access the application
- The port used to execute a function
Even while not all information should be recorded in logs, logged events should have enough details to allow for the correction of any serious errors. Never keep keys, passwords, or any other sensitive information in logs.
Sensitive data should never be stored, even if these logs are secured so that only authorized users can access them. However, in a cybersecurity incident where an attacker can escalate privileges, these logs could be exploited in a data breach.
Structured, Unstructured, and Semi-structured Log Differences
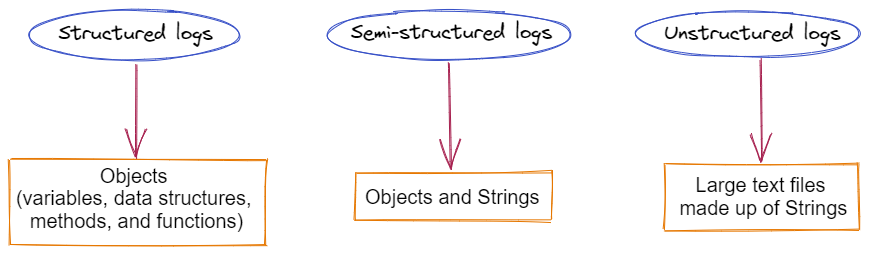
Unstructured logs are large text files made up of strings, which are intended for human reading and consist of organized sequences of characters. These strings are placeholders for attributes that are defined elsewhere in logs' variables. Sometimes the variable is a wildcard, a placeholder that denotes an ambiguous attribute.
Variables are simple for people to understand, but machines frequently struggle with them. They sometimes find it difficult to differentiate between a variable in one string and a similar string elsewhere in the log file. When that occurs, the outcomes can be unclear, slowing productivity, increasing fallibility, and wasting processing cycles and man-hours.
Objects rather than strings make up structured logs. Variables, data structures, methods, and functions can all be found in an object. An object that is a component of a log message, for instance, can contain details about a platform or an application.
To make the logs most helpful in satisfying their specific goals, the organization can specify the criteria they intend to include in the object. In a structured log, this is the "structure."
Since structured logs are designed to be read by machines, the machines that do so may search through them more quickly, create cleaner output, and provide consistency across platforms. Although they are not the target audience, humans can nevertheless read structured logs.
Benefits of Structured Logging
There are numerous benefits to having well-defined and structured logs (like JSON):
- Better Consistency
By using structured logs, you may give your logs more structure and make them more consistent as the systems change. This makes it easier for us to index our logs in a system like Elastic Stack since we can be certain that we are adhering to some structure. - Better Root Cause Analysis
We can ingest and run more complex queries using structured logs than we can with unstructured logs alone. When looking for the logs that are relevant to the scenario, developers can run more enlightening searches. - Better Standardisation
We can standardize logging by having a single, clearly defined, structured method, which reduces the cognitive load of interpreting logs to determine what happened in systems and makes adoption easier. - Dynamic Log Levels
This enables us to release code with baseline warning settings and only switch to lower levels (debug logs) when necessary, allowing us to have relevant log levels. - Future-proof Log Consistency
By adopting a single schema, we ensure that we maintain the same structure even if, for example, our logging system changes tomorrow, enabling us to be future-proof. We can just provide a function in our loggers rather than explicitly declaring what to log. - Greater Transparency or Better Observability
You can see more clearly what's going on with your system when you use organized logs. This makes it possible for you to see what is happening in the system more clearly and makes your systems simpler to manage and troubleshoot over extended periods. - Production-Like Logging Environment in Development
Developers may benefit from the same features as production users due to the dockerized Kibana. Additionally, this motivates developers to use the Elastic stack more and experiment with its features, such as creating dashboards from log data, having better watchers, and other things.
Why is Structured Logging Important?
Finding an event in an unstructured log can be challenging since a simple query frequently yields significantly more data than required and the wrong data altogether.
A developer looking for a log event made when a given application's disk quota was exceeded by a specified amount, for instance, may discover all disk quota events produced by all applications. That will be a sizable file in an enterprise environment.
The developer would have to create a challenging regular expression to specify the search to discover the appropriate event. Additionally, the phrase becomes more difficult the more specific the event. Because each row value in the log record must be compared to the match expression's requirements, this method is computationally expensive at scale.
The computational cost increases if wildcards are employed. Additionally, the match expression won't function as intended if the log data changes.

In certain companies, developers create strings of code, while operations teams write code to turn those strings into structured data. This requires more time and costs more money to compute. If a developer or a member of the operations team makes an error, the logging process is disrupted and extra time is lost trying to identify the error's cause.
By arranging the data as it is generated, structured logging gets rid of these issues. A fixed column, key-value pairs, JSON, or any other format that works best for the business can be chosen.
Due to its compatibility with automation systems, especially alerting systems, JSON format is the format of choice for most enterprises today.
Due to the limitations of structured logging, text logs are still used in the workplace. Data can only be utilized for uses that are supported by the definition since structured logs describe data as it is created.
Furthermore, whether the structured data is kept on-site or in a data warehouse with rigid data architecture, updating the structured data will be a time-consuming and expensive task.
Organizations should think about who will use the data, what kind of data is gathered, where and how the data will be stored, and whether the data needs to be prepared before storing or if it can be prepared when utilized when choosing a logging strategy.
Conclusion
The textual format of typical log entries makes them simple to read for human analysts but challenging for computers to process. There are instances when we may wish to explore log files using automated processing, or we may want to utilize algorithms to classify, index, and search through log files based on particular criteria. To provide this functionality, IT companies must build structured logging.
Explore:
Atatus Log Monitoring and Management
Atatus is delivered as a fully managed cloud service with minimal setup at any scale that requires no maintenance. It monitors logs from all of your systems and applications into a centralized and easy-to-navigate user interface, allowing you to troubleshoot faster.
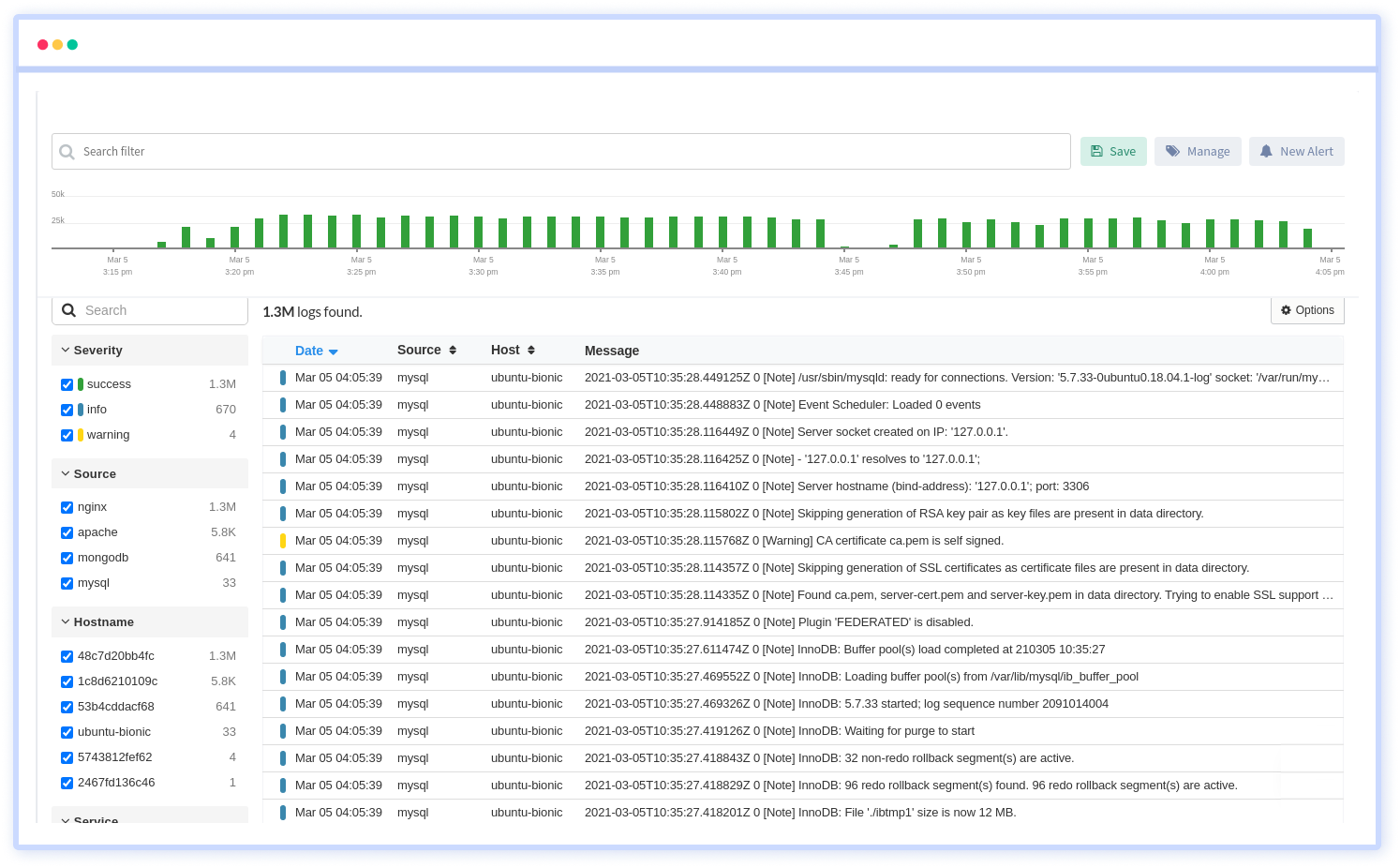
We give a cost-effective, scalable method to centralized logging, so you can obtain total insight across your complex architecture. To cut through the noise and focus on the key events that matter, you can search the logs by hostname, service, source, messages, and more. When you can correlate log events with APM slow traces and errors, troubleshooting becomes easy.



