Introducing LLM Monitoring Support
Released on: September 2025Atatus now supports LLM (Large Language Model) Monitoring, giving teams complete visibility into how AI-powered applications perform in production. Whether you are working with chatbots, copilots, or generative AI workloads, you can trace every LLM request and track tokens effectively. You can also monitor latency, detect issues in real time, and gain insights into model behavior. This helps developers, DevOps, and SREs ensure reliable, cost-efficient, and high-quality AI experiences.
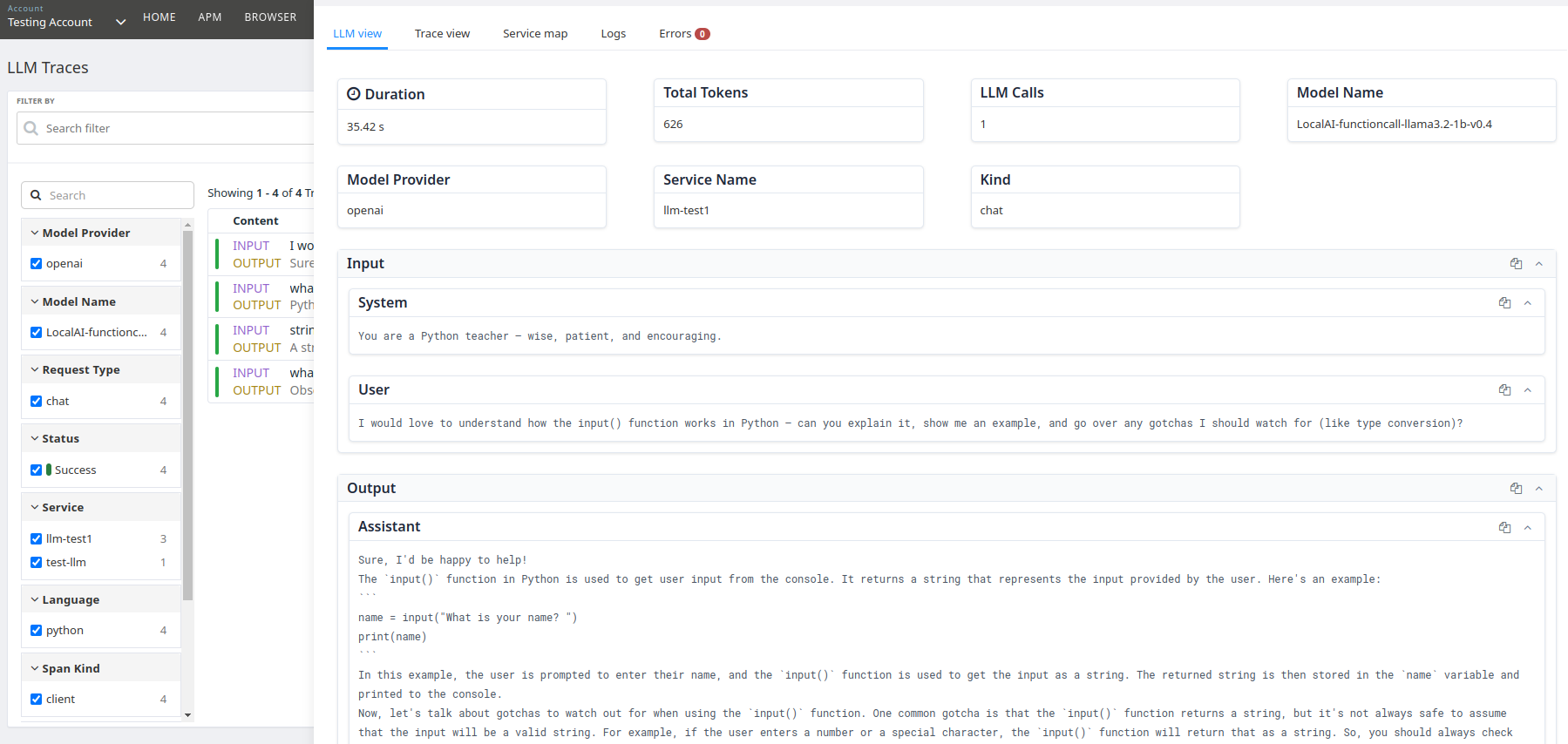
Key Benefits of LLM Monitoring in Atatus:
- Token & Cost Insights: Monitor token usage across requests to optimize costs, reduce waste, and prevent unexpected billing spikes.
- Input/Output Visibility: See the exact input prompts and corresponding outputs for every LLM call, enabling faster debugging, auditing, and optimization of AI interactions.
- End-to-End Tracing: Track every LLM call with detailed inputs, outputs, and execution context to debug faster and understand model behavior.
- Error Visibility: Catch failed or incomplete responses, detect anomalies, and resolve issues before they impact users.
- Performance Tracking: Measure duration, latency, and throughput to ensure smooth, responsive AI-driven applications.
Monitor your software stack for free with Atatus.
Start your free trialOR
Request a DemoFree 14-day trial. No credit card required. Cancel anytime.