Java Application Performance Monitoring
Get out-of-the-box visibility into critical KPIs and business performance with our Java monitoring tools. Analyze database transactions, debug with detailed traces, and visualize your applications and their dependencies for optimal insights and management.
Why Java production failures are hard to explain?
Production Black Boxes
Once services run on shared platforms, visibility fragments across teams. Platform engineers lose a unified view of how workloads behave under real traffic.
Symptom-First Incidents
Incidents surface as system-wide symptoms, but tracing impact across runtimes, services, and dependencies becomes slow and uncertain.
Slow Root Causes
Platform teams are pulled into investigations without clear signals, spending time correlating data instead of stabilizing the platform.
Scale-Only Failures
Issues appear only at peak scale, where platform changes, JVM behavior, and workload patterns intersect in unpredictable ways.
Blurred Ownership
When failures span multiple teams, platforms become the default escalation point, even when the root cause is unclear.
Silent Regressions
Incremental changes across services degrade platform reliability, but isolating responsibility becomes difficult over time.
Signal Distrust
Inconsistent signals across environments reduce confidence in platform-wide monitoring standards.
Reactive Debugging
Platform teams shift from enabling teams to firefighting systemic issues without clear causal insight.
Complete Visibility for High-Performance
Java Applications
End-to-end observability for Java workloads that helps engineering teams maintain speed, stability, and smooth production releases.
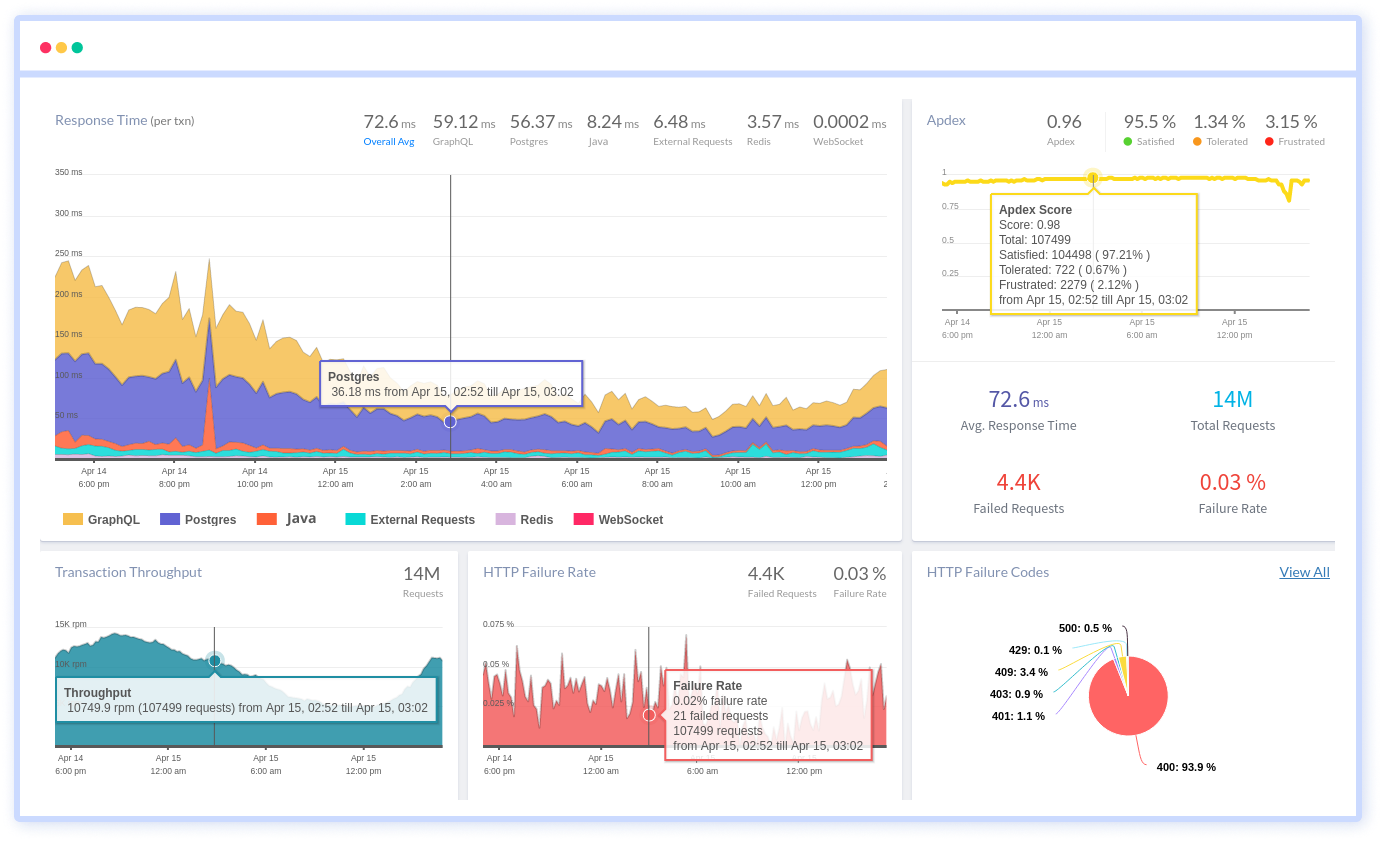
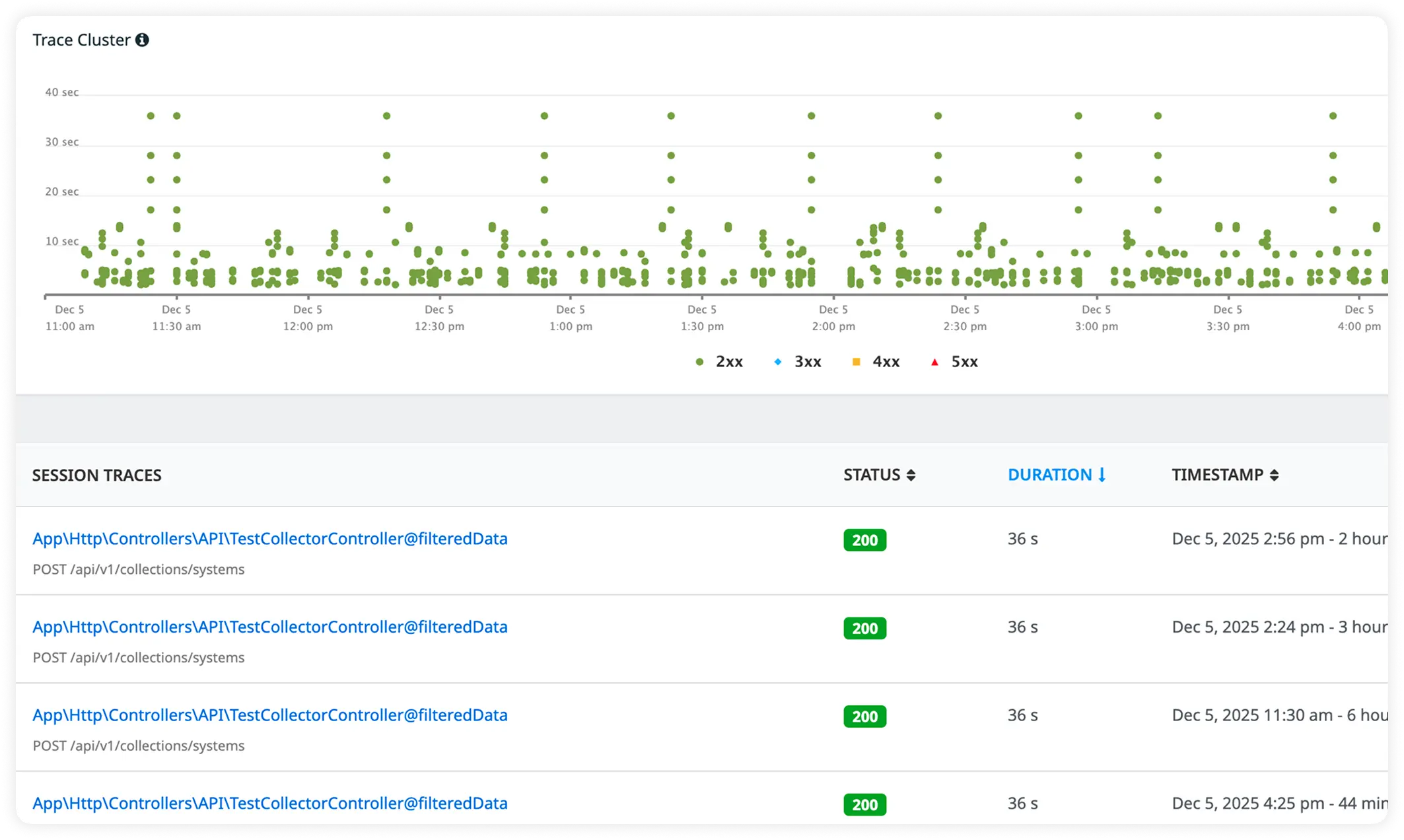
Follow Every Java Request End to End
Follow each request across microservices, APIs, databases, and background processes in a single distributed trace. Get deep insight into execution flow, thread activity, and performance behavior across your Java application.
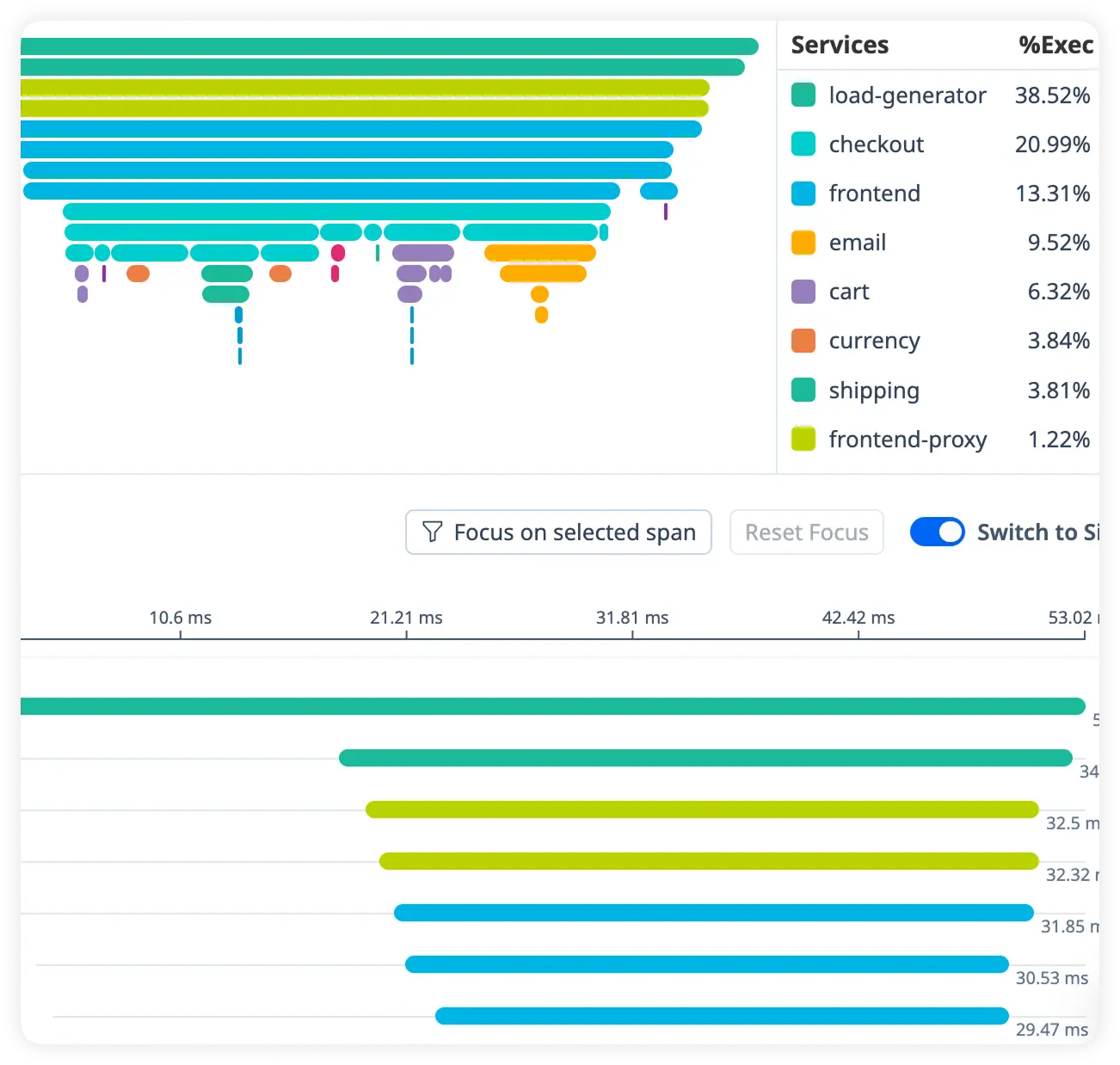
See How Your Java Services Interact
See how Java services communicate with databases, message brokers, caches, and external systems. Quickly identify latency bottlenecks, traffic patterns, and failure hotspots across your architecture.
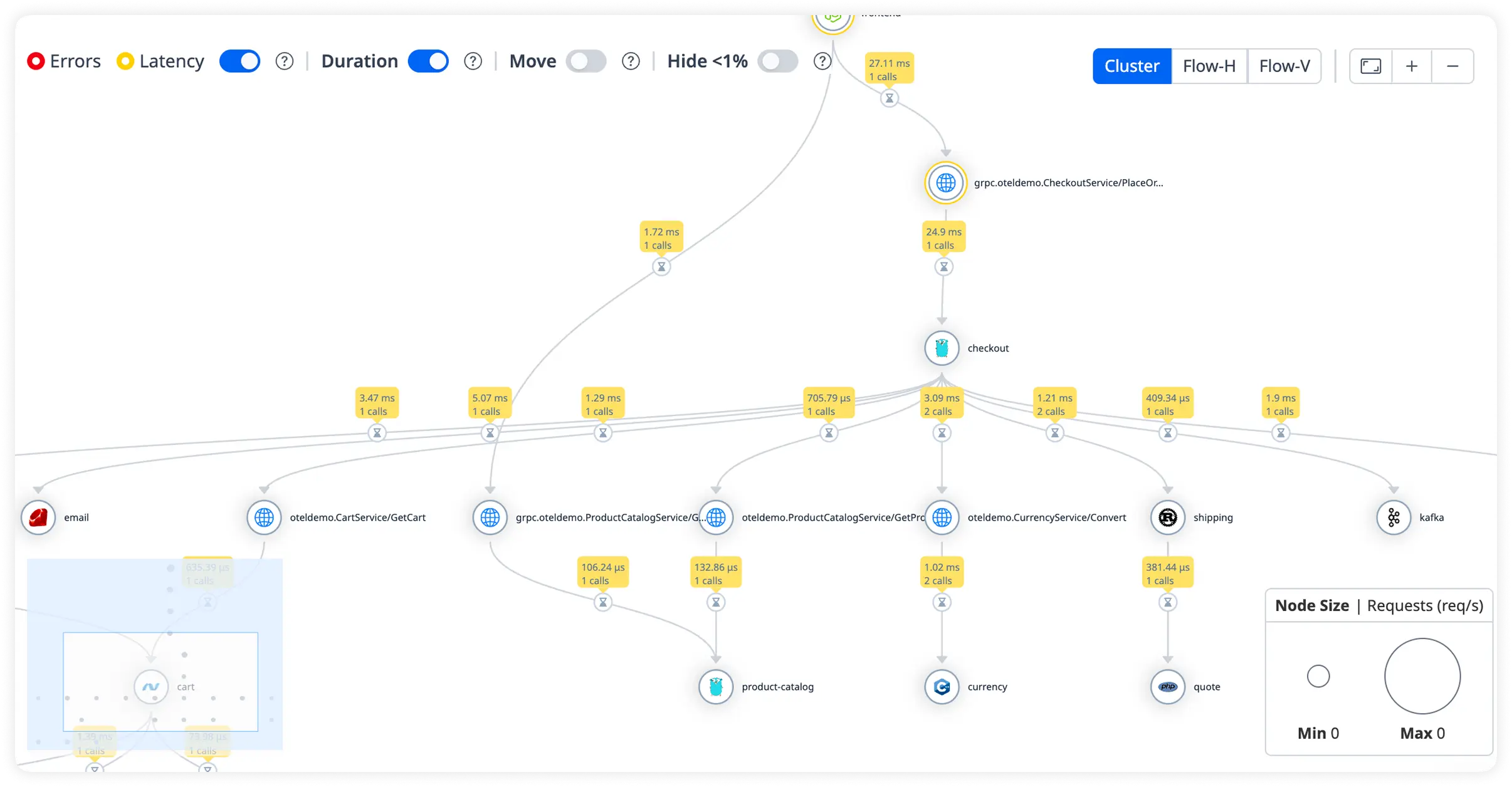
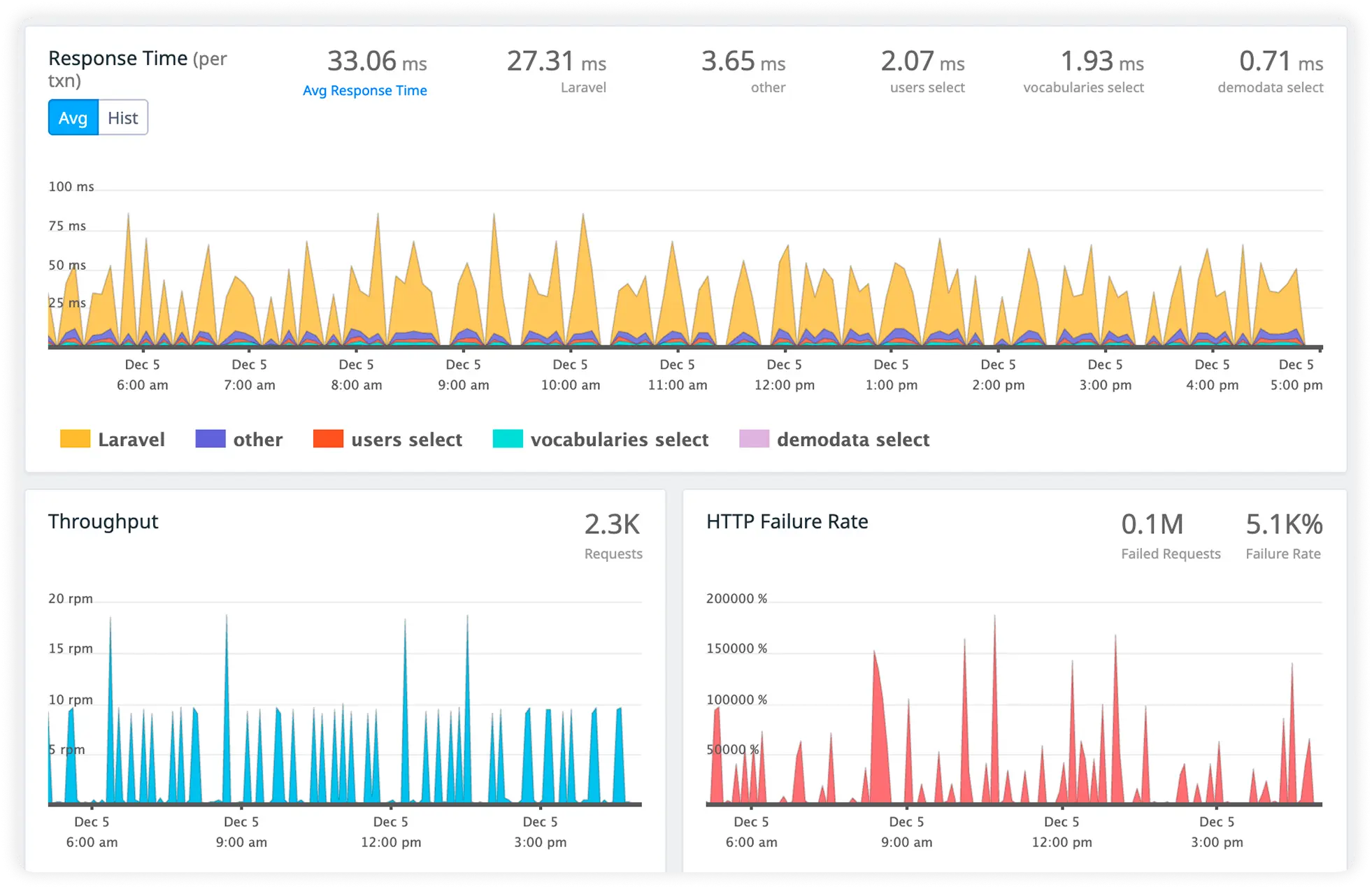
Keep Core Java Transactions Performing
Track core business operations such as order processing, authentication flows, API calls, and batch jobs. Detect slow transactions, error spikes, and performance regressions before they impact users.
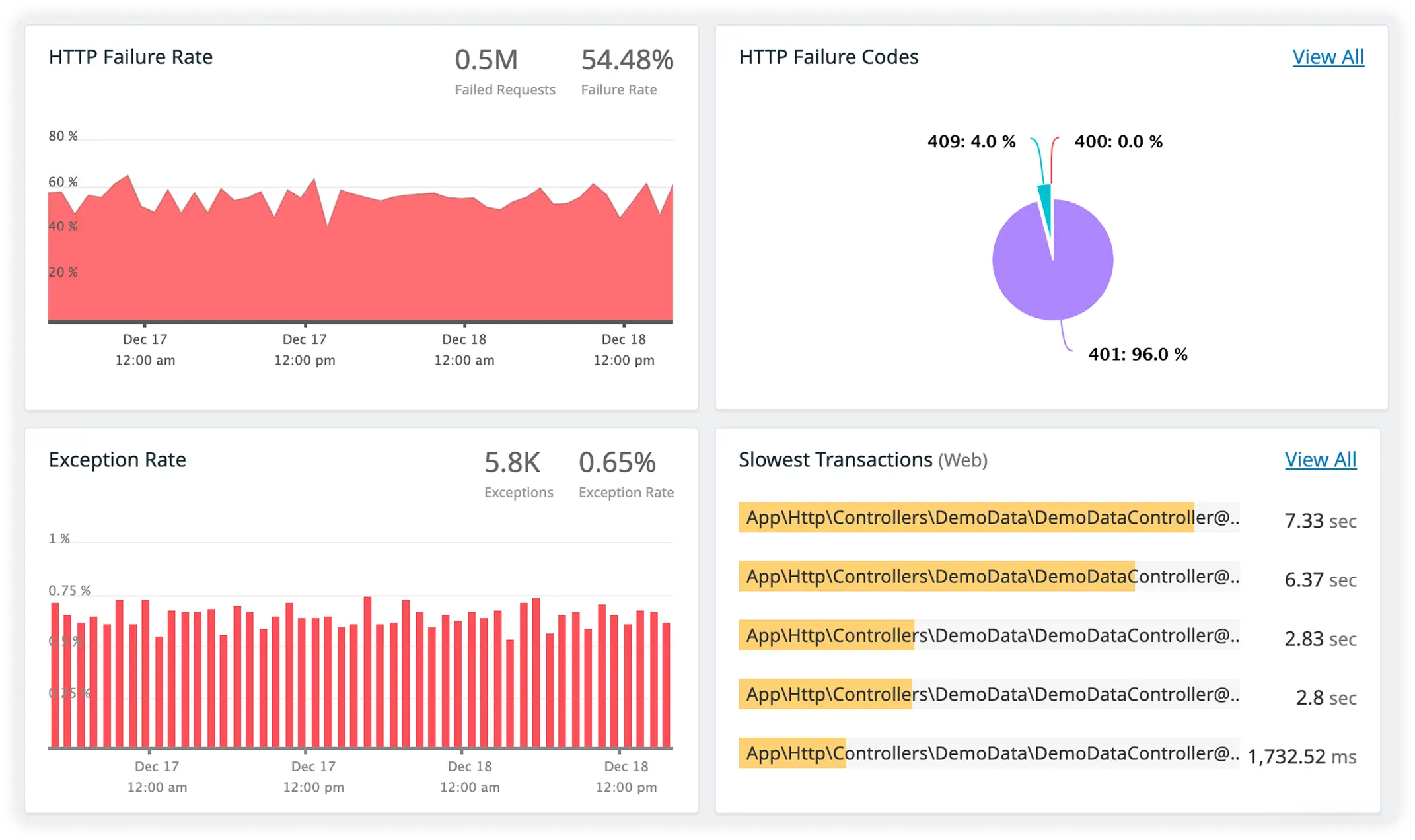
Stay Ahead of External Service Issues
Monitor third-party services, APIs, and integrations that your Java applications rely on. Stay ahead of outages and slowdowns that can cascade across your system.
How Engineering Teams Regain Control With Atatus?
Teams choose Atatus for clear visibility into Java performance without adding complexity to their stack.
Production Clarity
Teams gain a grounded understanding of how Java applications behave under real traffic, including how requests flow across services and shared infrastructure during normal operation and failure.
Fast Adoption
Insight becomes available quickly, without long setup cycles, heavy process changes, or extended learning curves for engineering teams.
Trusted Signals
Production signals stay consistent and explainable, allowing teams to rely on them during incidents instead of second-guessing their accuracy.
Lower Cognitive Load
Engineers no longer need to manually stitch together context from multiple sources, reducing mental overhead during investigations.
Shared Understanding
All engineering roles operate from the same production reality, making collaboration during incidents and reviews more efficient.
Confident Shipping
Teams make changes with greater certainty, knowing the impact will surface early before performance degradation reaches users..
Decisive Debugging
Teams move from detection to resolution with less trial and error, shortening investigation cycles.
Workflow Fit
The system aligns with how engineers debug issues in practice, supporting real-world investigation patterns rather than forcing rigid processes.
Operational Calm
Over time, incident response becomes steadier and more predictable, reducing escalation pressure and engineering fatigue.
Unified Observability for Every Engineering Team
Atatus adapts to how engineering teams work across development, operations, and reliability.
Developers
Trace requests, debug errors, and identify performance issues at the code level with clear context.
DevOps
Track deployments, monitor infrastructure impact, and understand how releases affect application stability.
Release Engineer
Measure service health, latency, and error rates to maintain reliability and reduce production risk.