Full Visibility Into Your
AI Applications
Monitor every prompt, trace every chain, track every token. Atatus gives your team deep observability across all your LLM-powered products, in one unified platform.
Works with every major LLM provider
Everything you need to run
AI in production
From a single model call to complex multi-agent pipelines - Atatus captures it all with zero blind spots.
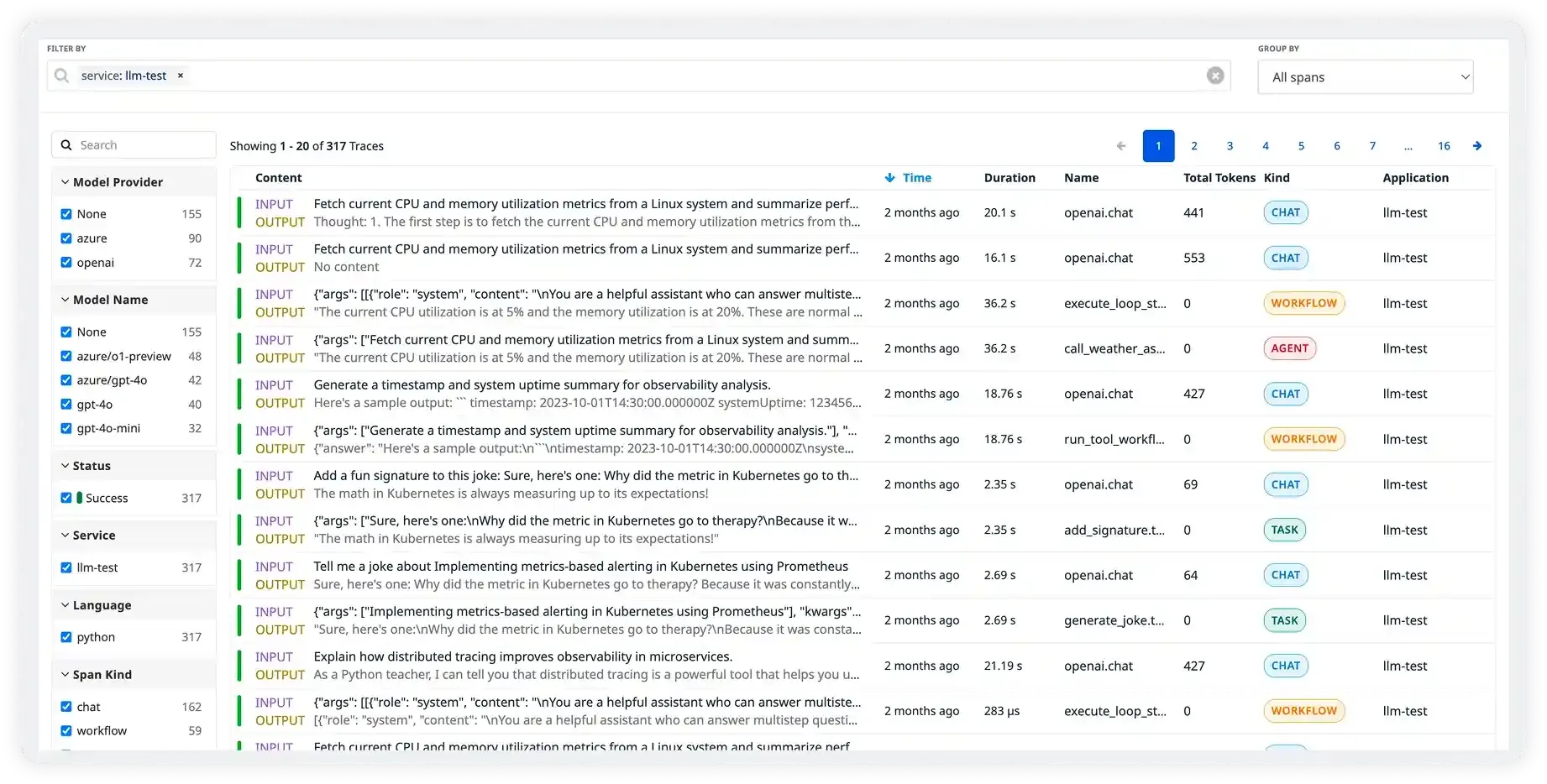
Distributed LLM Tracing
Trace every request end-to-end, from user input through retrieval, tool calls, and model completion. See exactly where time is spent and what data flows through your pipeline.
Token Usage & Cost Tracking
Know exactly what you're spending, per model, per feature, per user. Set budgets and get alerted before you overspend.
Latency Analytics
Track TTFT, total generation time, and p50/p95/p99 breakdowns. Spot regressions the moment they happen.
Session Tracking
Group traces by user session to see entire conversation flows. Understand the full context behind every LLM interaction and user journey.
User opened session
Vector search · Pinecone
LLM completion
Session completed
Built for production scale
Traces processed daily
2.4M+
across all Atatus customers
SDK overhead
<1ms
avg instrumentation latency
Setup time
2 min
median time to first trace
The observability platform built
for the AI era
Most monitoring tools were built for traditional software. Atatus was purpose-built for LLM applications, handling the unique challenges of prompt engineering, token economics, and non-deterministic outputs.
Purpose-Built for LLMs
Generic APM tools don’t understand prompts, tokens, or chains. Atatus speaks the language of LLM-native applications with first-class support for RAG pipelines, agents, and multi-step workflows out of the box.
Cut Costs Without Cutting Quality
Atatus surfaces which prompts, users, and features drive the most spend. Teams typically find 20–40% cost reduction opportunities within the first week without compromising response quality or user experience.
Debug in Minutes, Not Days
When your AI app misbehaves, Atatus gives you the full picture exact prompts sent, completions received, tool calls made, latency at every step. No more “it worked in testing” blind spots.
One Platform, Every Model & Framework
Switching models or frameworks shouldn’t mean switching monitoring tools. Atatus works across OpenAI, Anthropic, Gemini, Bedrock, Mistral, LangChain, LlamaIndex, and more, all in a single unified dashboard.
Prompt Quality & Evaluation
Track how your prompts perform over time. Compare versions, measure output quality, and catch regressions before they reach users — with built-in evaluation metrics tied to real production traces.
Trusted by teams building AI products at scale
“We were flying blind with our RAG pipeline — no idea which queries were expensive or slow. Atatus showed us in 10 minutes that 30% of our costs came from 5% of queries. Huge win”
Siddharth R.
Staff Engineer
“Integration was incredibly simple. It auto-hooks into everything and the support team was super responsive. It's now our go-to for all LLM observability. The cost tracking alone paid for itself”
Ananya K.
ML Engineer
“Powerful, flexible, and scalable. Atatus has helped us identify issues in record time. With session-level tracing we can finally debug multi-turn agent failures without guessing”
Marcus T.
CTO