Redis Operational Logs for Memory and Cluster Health
Track command execution, memory events, durability operations, and cluster synchronization in real time.
Monitor Redis logs and operational events in production environments
Collect Redis server logs
Ingest Redis server log output including startup messages, warnings, and runtime errors generated by standalone and clustered Redis instances.
Track persistence and snapshot events
Analyze Redis log entries related to RDB snapshots and AOF rewrites to understand persistence behavior and disk I/O impact.
Monitor replication and failover
Capture Redis replication logs to detect replica synchronization issues, role changes, and failover events in high-availability setups.
Detect memory pressure signals
Surface Redis log warnings related to maxmemory limits, eviction policies, and out-of-memory conditions before service degradation.
Observe key eviction and expiration
Inspect Redis log messages that indicate key eviction, expired keys processing, and cache behavior under load.
Analyze client connection issues
Identify Redis client connection errors, authentication failures, and timeout-related log entries affecting application access.
Correlate logs with runtime metrics
Link Redis log events with metrics such as memory usage, command throughput, and latency to investigate performance anomalies.
Support clustered Redis deployments
Aggregate logs from Redis Cluster nodes and sentinel-managed environments into a centralized operational view.
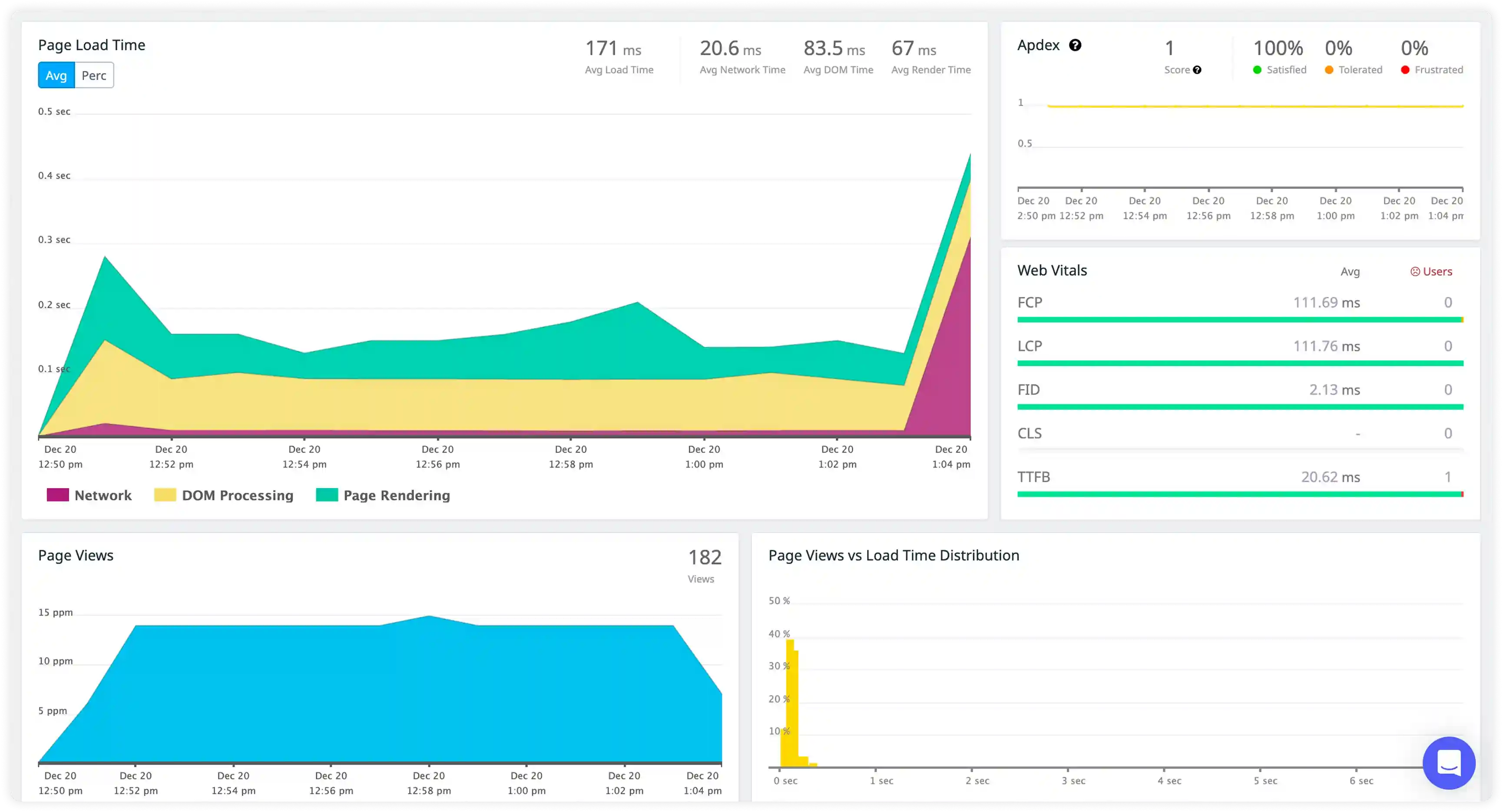
Command Execution and Keyspace Activity
- Track log generation across command execution, key access, and data operations to understand runtime behavior in Redis workloads.
- Correlate command logs with application requests and cache usage patterns to trace read and write activity.
- Identify failed commands, blocked operations, and abnormal key access affecting cache responsiveness.
- Detect disruptions in keyspace activity impacting application performance and data availability.
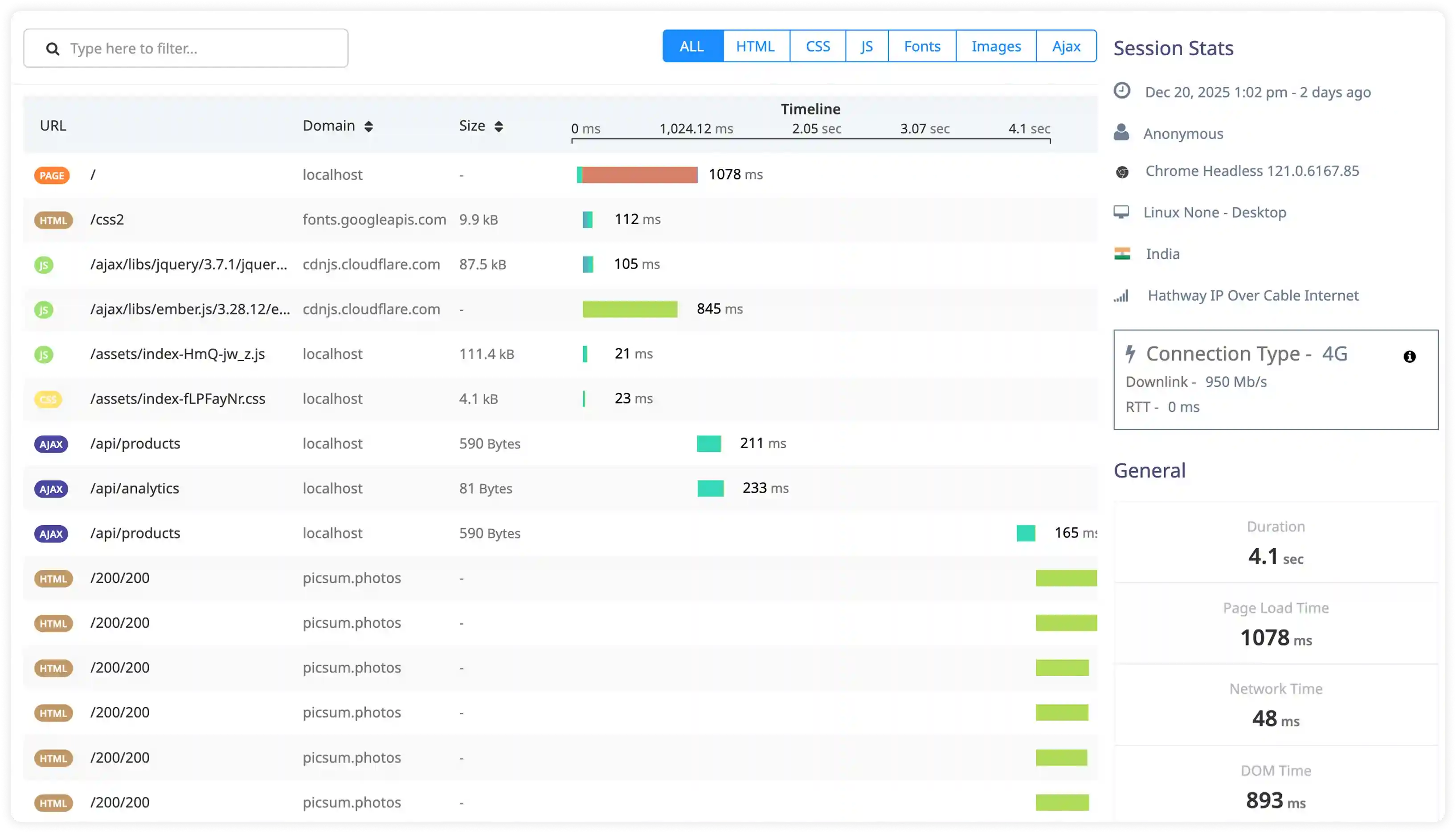
Memory Management and Persistence Signals
- Capture logs related to memory usage, eviction policies, and persistence operations such as RDB and AOF.
- Correlate memory pressure with eviction events, write failures, and cache saturation patterns.
- Identify recurring persistence failures caused by disk I/O constraints or configuration issues.
- Detect hidden risks affecting durability, data recovery, and cache stability.
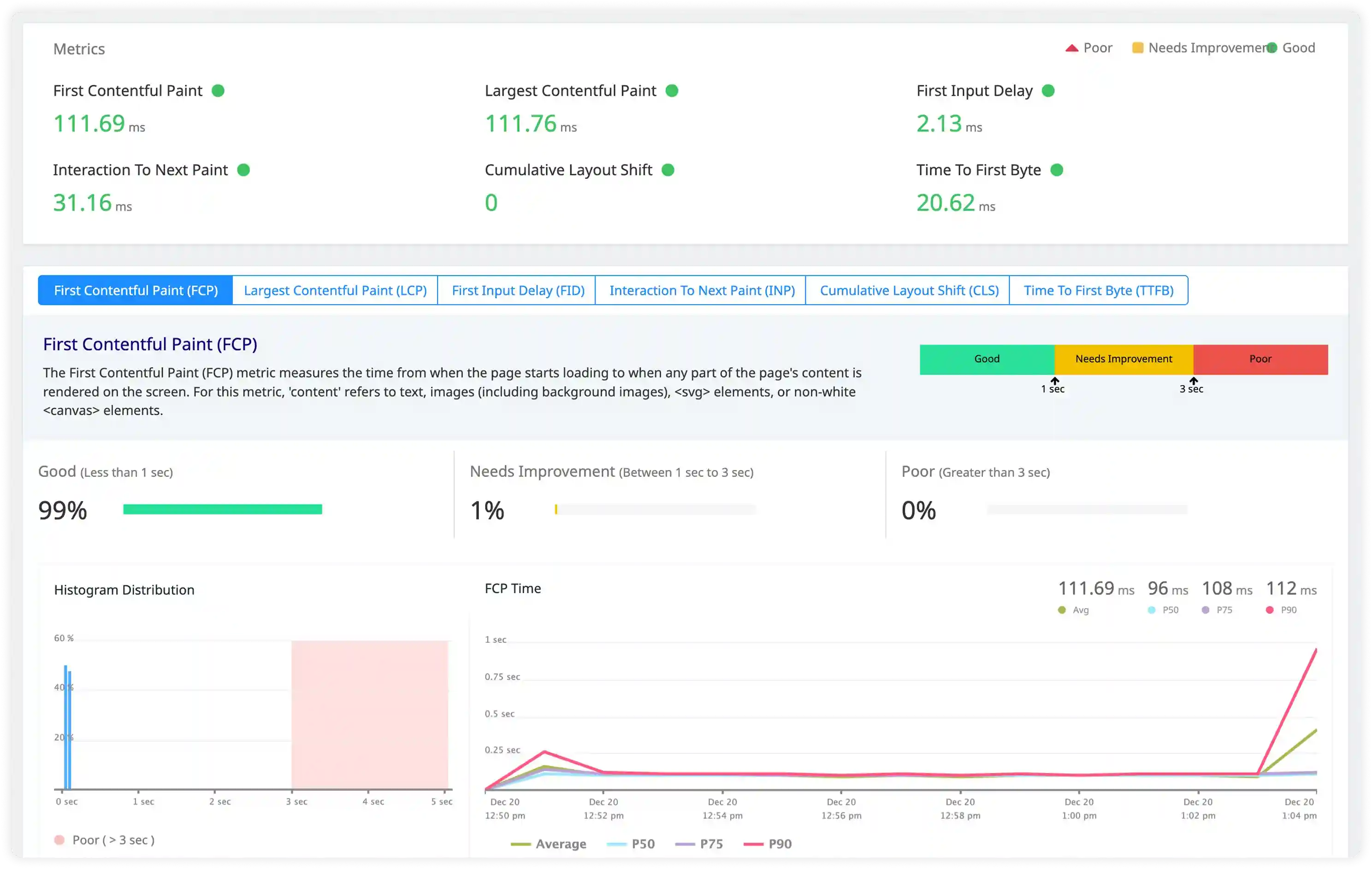
Replication and Cluster Behavior
- Analyze replication logs, synchronization activity, and cluster communication events across Redis nodes.
- Correlate replication lag and failover behavior with workload spikes and infrastructure conditions.
- Identify recurring node synchronization failures and cluster instability affecting high availability.
- Detect operational disruptions impacting distributed cache reliability and scaling..
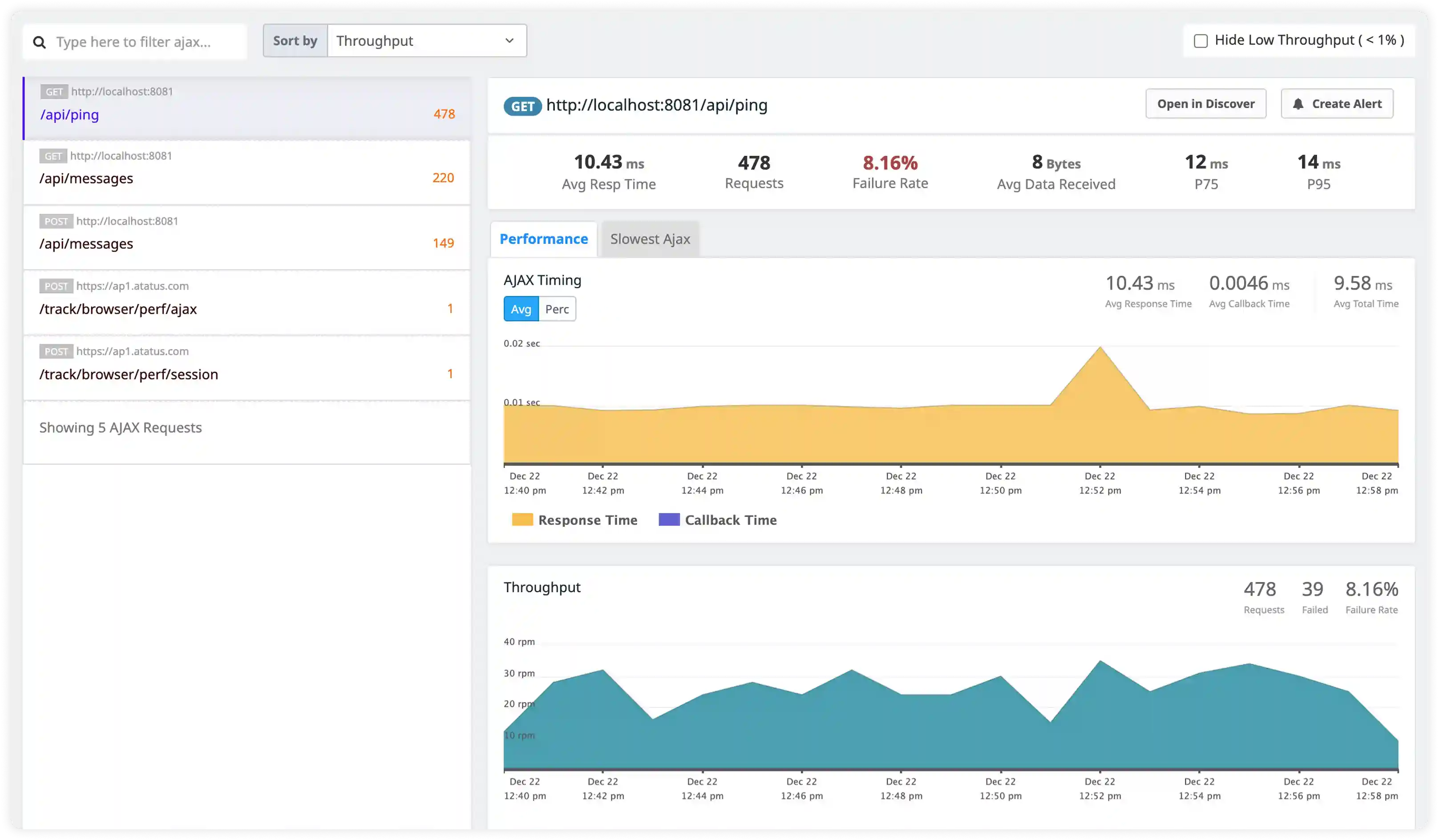
Security and Access Monitoring
- Track authentication attempts, unauthorized commands, and suspicious access patterns captured in Redis logs.
- Identify misuse patterns such as abnormal command frequency or unauthorized key modifications.
- Correlate Redis activity with application and network logs for incident investigation.
- Detect security risks and operational anomalies affecting Redis environments.
Why choose Atatus for Redis logs monitoring?
Redis-native log insights
Atatus ingests and interprets Redis server logs including persistence events, replication changes, and runtime warnings.
Cache performance clarity
Atatus helps teams investigate evictions, cache misses, and latency spikes using log-driven signals.
High-availability visibility
Atatus surfaces replication and sentinel events to track failovers and cluster health.
Faster operational diagnosis
Atatus centralizes Redis logs across environments to speed up incident troubleshooting.
High-throughput ready
Atatus processes heavy Redis log volumes without impacting performance.
Modern deployment coverage
Atatus aggregates Redis logs across VMs, containers, and cloud Redis environments.
Unified Observability for Every Engineering Team
Atatus adapts to how engineering teams work across development, operations, and reliability.
Developers
Trace requests, debug errors, and identify performance issues at the code level with clear context.
DevOps
Track deployments, monitor infrastructure impact, and understand how releases affect application stability.
Release Engineer
Measure service health, latency, and error rates to maintain reliability and reduce production risk.