Grails Performance Monitoring
Get end-to-end visibility into your Grails performance with application monitoring tools. Gain insightful metrics on performance bottlenecks with Java monitoring to optimize your application.
What causes opacity in Grails production environments?
Dynamic Runtime Ambiguity
Grails resolves controllers, services, and domain logic dynamically at runtime, making it difficult for engineers to confirm which code paths executed under real traffic conditions rather than assumed framework behavior.
GORM Latency Blindness
GORM-generated queries execute implicitly, causing performance degradation without clear attribution to specific request flows, domain models, or transactional boundaries.
JVM Resource Contention
JVM scheduling, garbage collection, and thread usage degrade performance gradually, leaving teams unaware of contention until latency and errors become visible.
Asynchronous Flow Fragmentation
Execution context breaks across scheduled jobs, async services, and message processing, forcing engineers to manually reconstruct failure paths.
Plugin Interaction Uncertainty
Plugins introduce interception, filters, and lifecycle hooks that affect runtime execution, often without clear visibility when issues surface in production.
Environment Configuration Drift
Differences in configuration resolution, external integrations, and JVM tuning cause runtime outcomes that no longer match staging or test assumption.
Error Stack Obfuscation
Framework layers and dynamic method calls inflate stack traces, slowing root-cause isolation and increasing investigation time.
Scaling Without Visibility
Increased concurrency stresses Grails internals and JVM resources, leading to gradual degradation without clear early warning signals.
Complete Performance Visibility for
Grails Applications
Real-time observability for Grails workloads that helps teams understand request behavior, optimize execution flow, and resolve production issues faster.
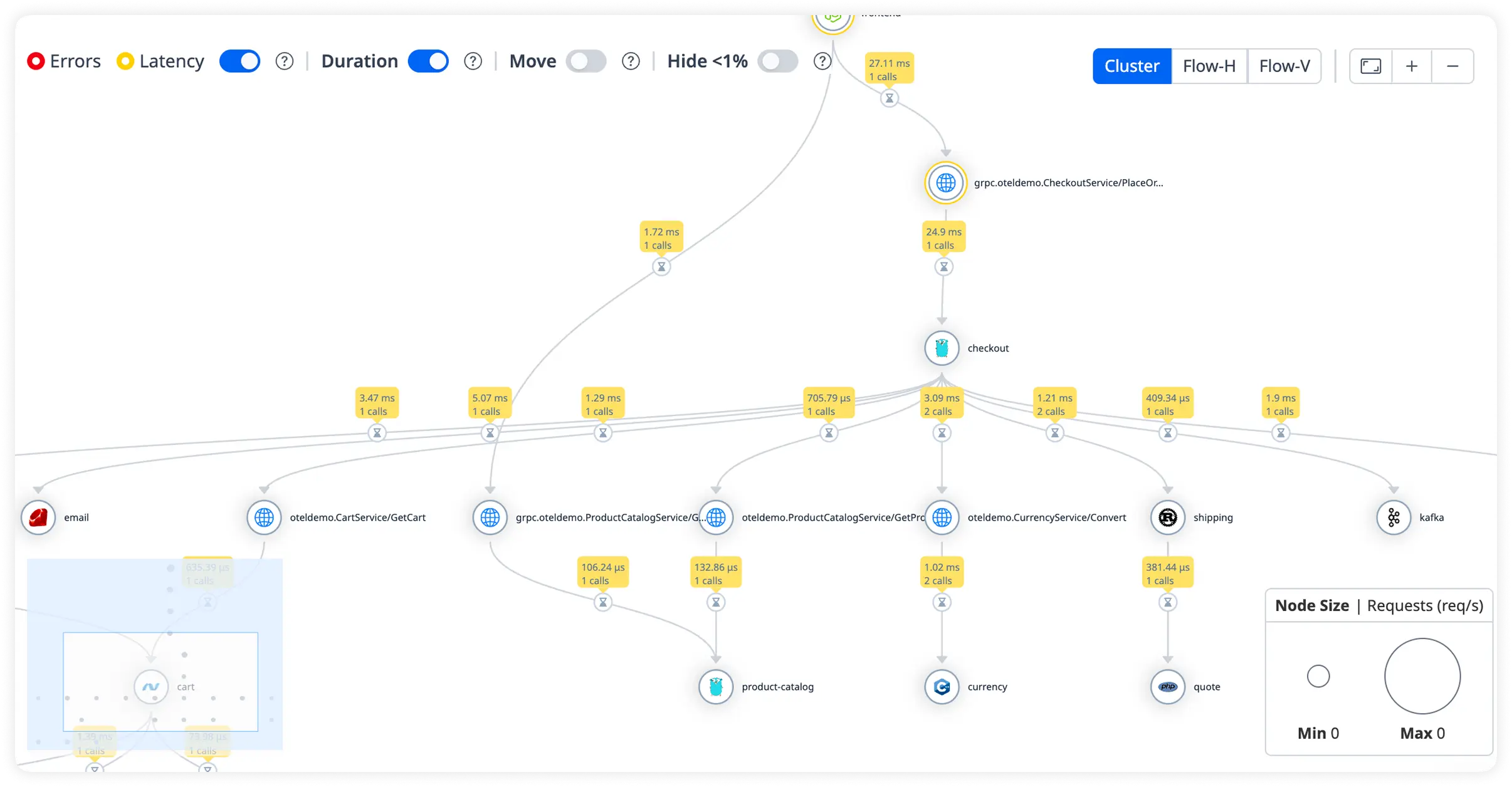
Detailed Request Duration Breakdown
Track how long each request takes from entry to response. Quickly uncover slow execution paths affecting application responsiveness.
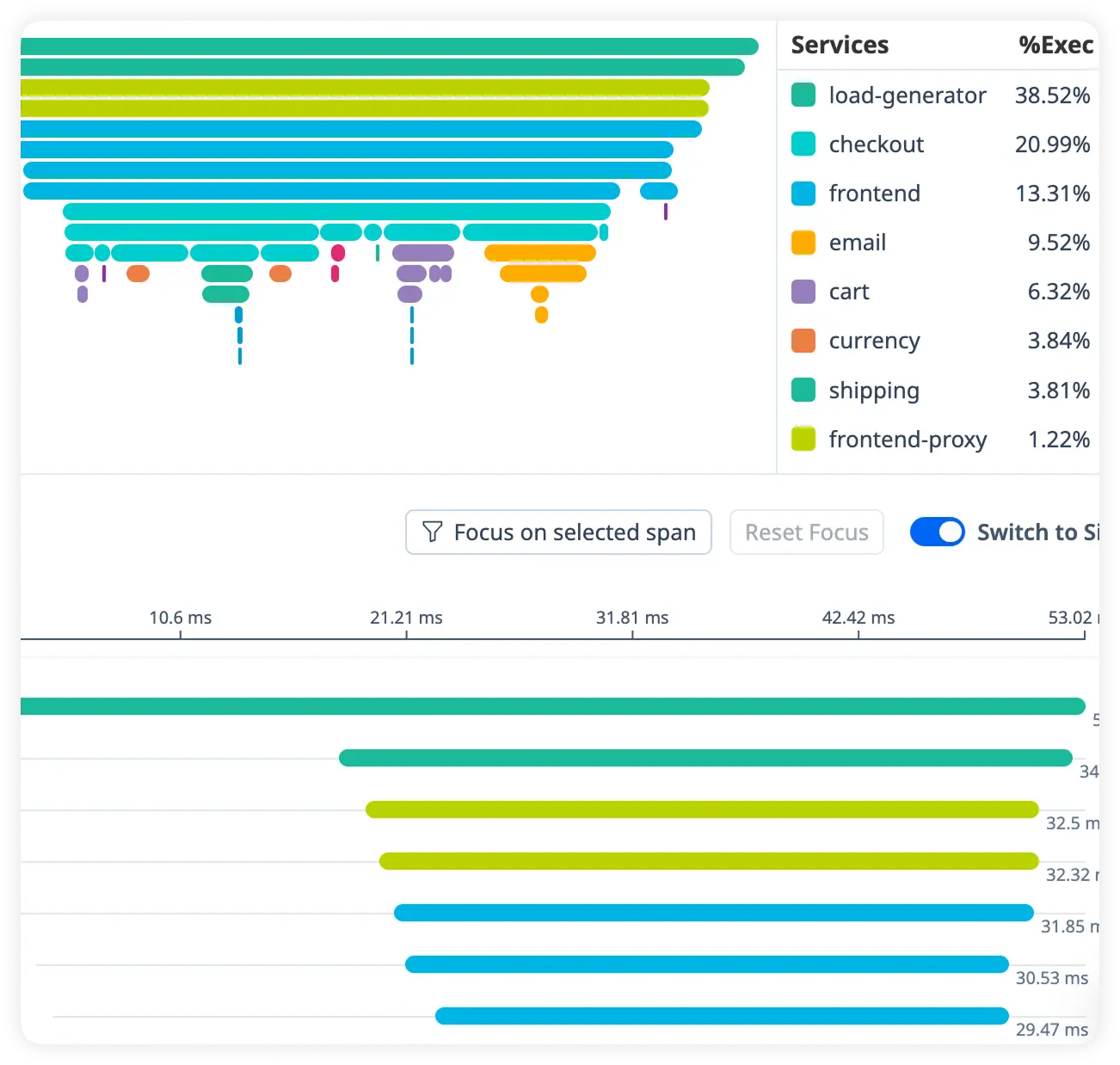
Controller Processing Time
Measure how much time each controller action consumes during request handling. Pinpoint slow processing steps across your Grails application.
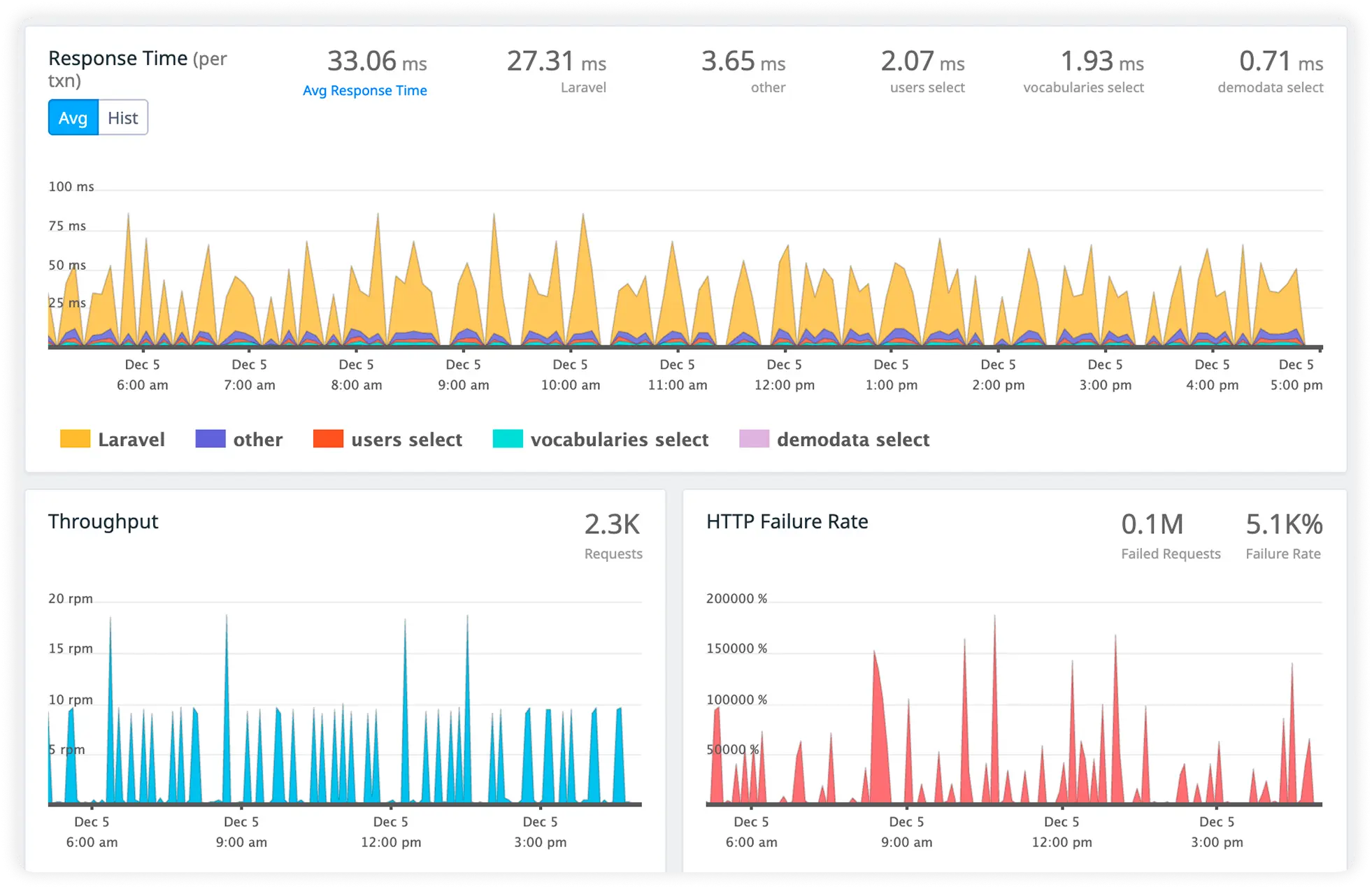
Database Call Duration
Analyze database query execution time and connection latency in real time. Eliminate inefficient database interactions slowing application performance.
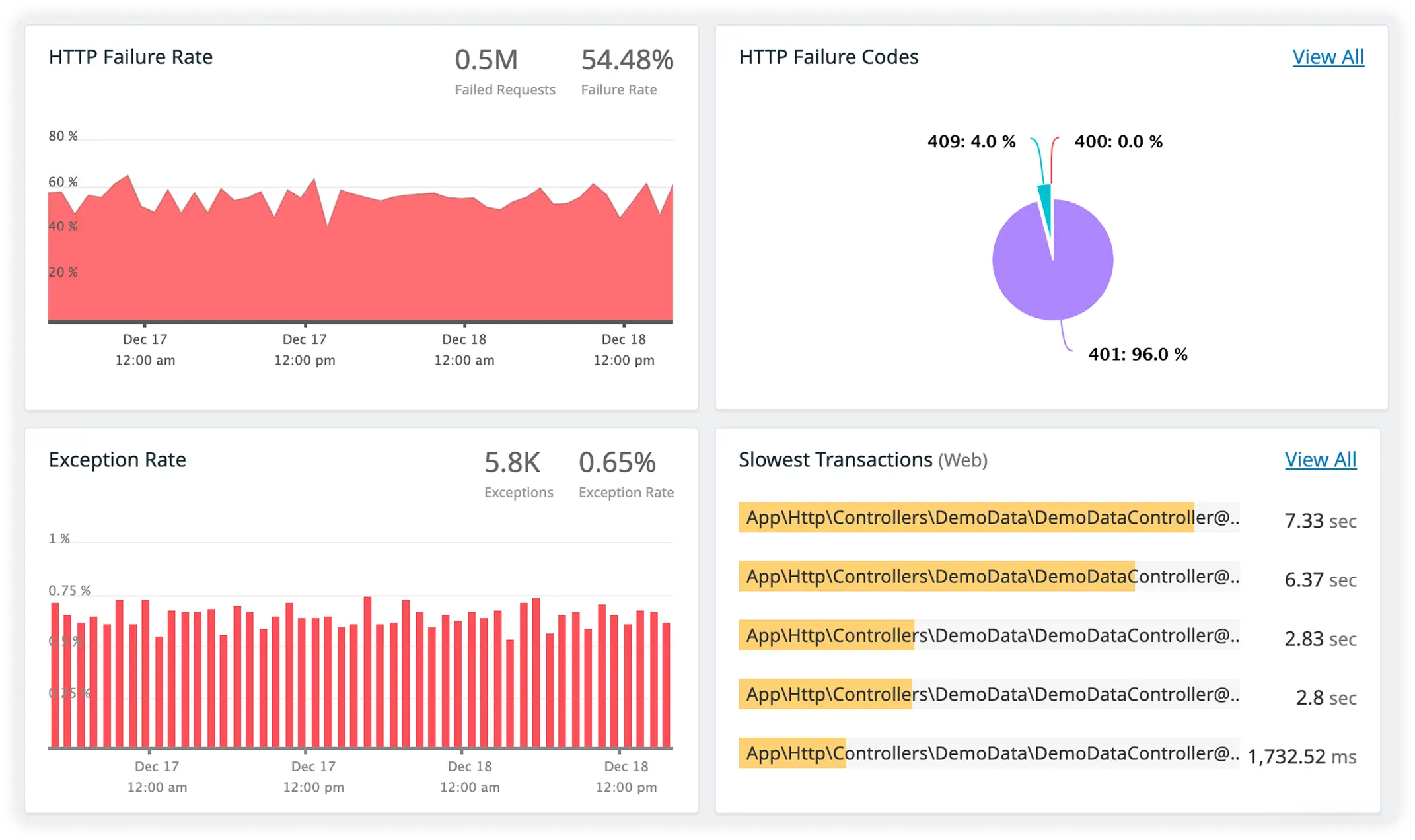
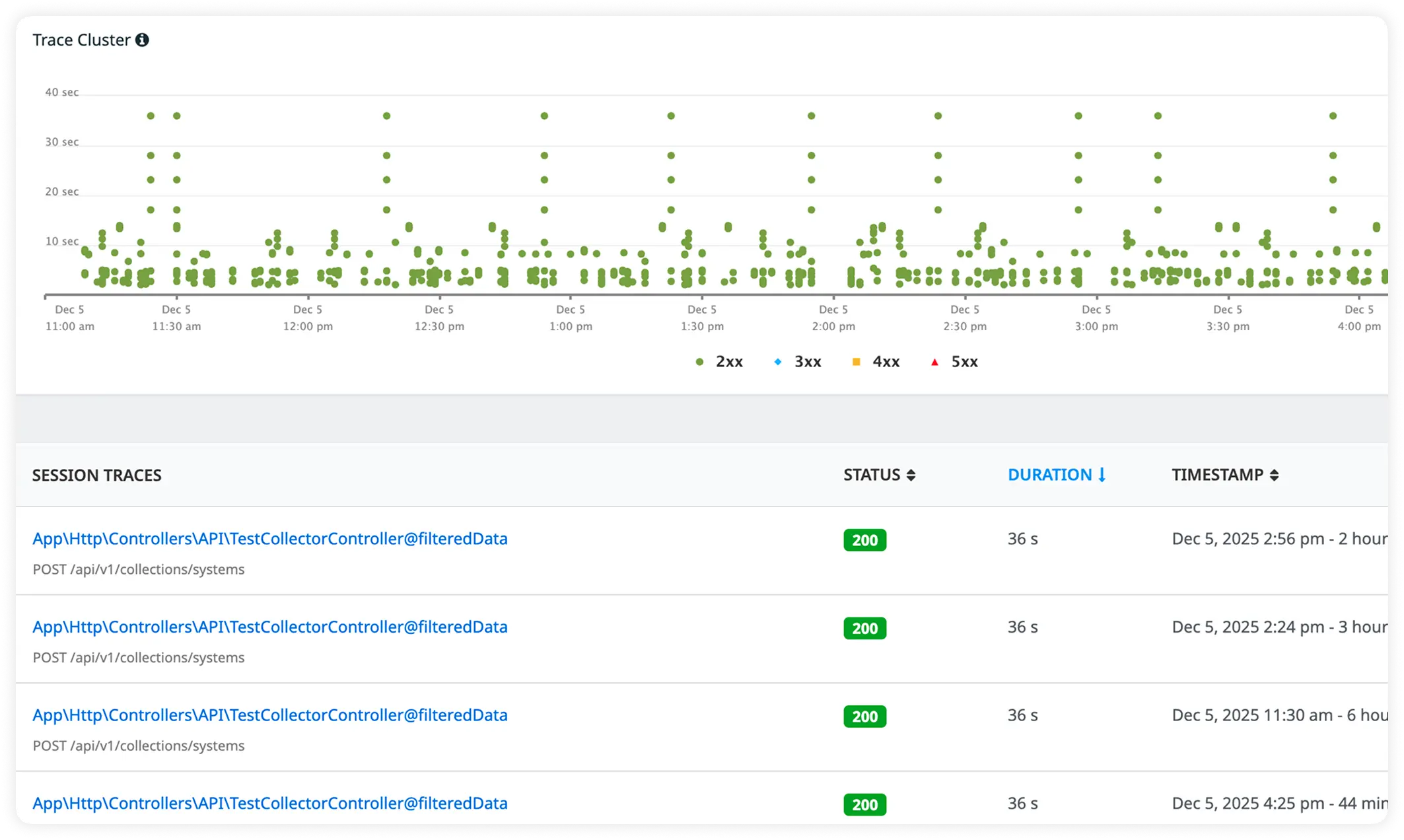
External HTTP Latency with End-to-End Request View
Track response times for external services while visualizing complete request flow across your application. Understand how dependencies impact overall performance.
Why Teams Choose Atatus?
Grails teams converge on Atatus when framework abstraction, JVM behavior, and production scale demand dependable execution insight.
Observable Execution Paths
Engineers reason about actual runtime flow instead of inferred convention behavior.
Rapid Trust Formation
Production signals become reliable early, reducing hesitation during incident response.
Framework-Aware Analysis
Teams interpret performance and failures with clear awareness of Grails and JVM interaction layers.
Consistent Investigation Patterns
Debug workflows follow structured paths rather than individual intuition.
On-Call Stability
Incident response remains predictable even during cascading failures.
Shared Operational Ground
Backend, platform, and SRE teams operate from the same execution reality.
Lower Interpretation Cost
Engineers spend less time decoding abstractions and more time resolving issues.
Growth Without Relearning
Operational understanding remains intact as plugins, traffic, and services expand.
Enduring Production Confidence
Teams retain confidence in runtime behavior as systems and ownership evolve.
Unified Observability for Every Engineering Team
Atatus adapts to how engineering teams work across development, operations, and reliability.
Developers
Trace requests, debug errors, and identify performance issues at the code level with clear context.
DevOps
Track deployments, monitor infrastructure impact, and understand how releases affect application stability.
Release Engineer
Measure service health, latency, and error rates to maintain reliability and reduce production risk.