Slim Performance Monitoring
Get end-to-end visibility into your Slim performance with application monitoring tools. Gain insightful metrics on performance bottlenecks with PHP monitoring to optimize your application.
Where slim teams lose production clarity
Partial Runtime Visibility
Production signals arrive fragmented across layers, leaving engineers without a continuous view of how requests behave end to end.
Missing Execution Context
Failures surface without enough surrounding state, forcing teams to infer call paths, timing, and system conditions after the fact.
Delayed Root Isolation
Identifying where an issue originates takes longer than expected, extending incident duration even when fixes are straightforward.
Dependency Impact Blindness
Downstream services and external systems introduce latency and errors that remain invisible until user-facing degradation escalates.
Signal Noise Overload
Production alerts fire without sufficient diagnostic depth, pushing engineers to filter noise before meaningful analysis can begin.
Unclear Scale Effects
As concurrency rises, system behavior changes in subtle ways that teams cannot observe clearly in real time.
Reactive Incident Cycles
Teams respond after failures spread because early indicators lack clarity or arrive too late to act proactively.
Eroding Data Trust
Repeated blind investigations reduce confidence in production signals, slowing decision-making during critical moments.
Complete Performance Visibility for
Slim Applications
Real-time observability for Slim workloads that helps teams track request performance, optimize execution flow, and resolve production issues faster.
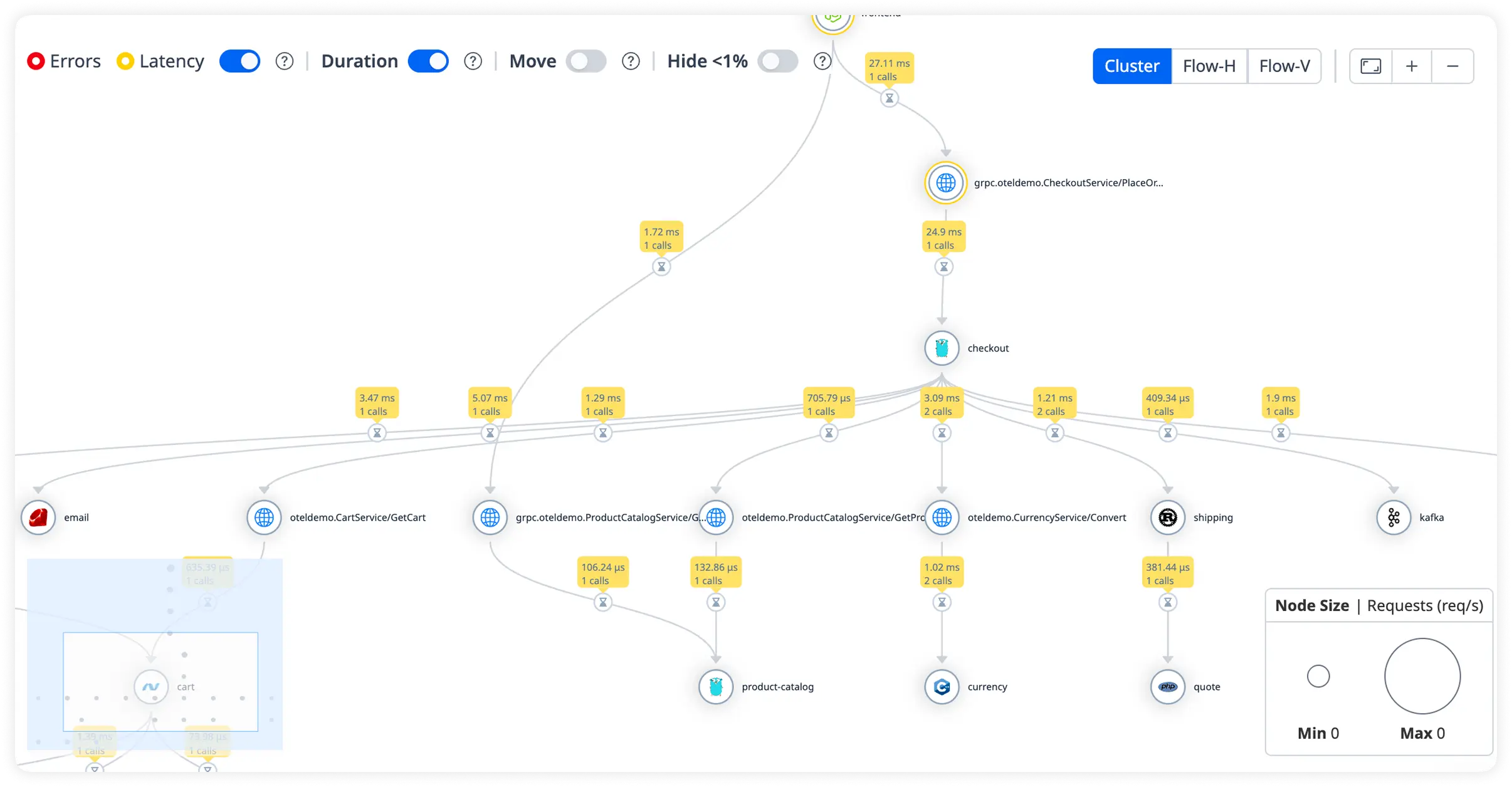
Trace-Level Visibility Across Slim Requests
Follow every Slim request across routes, database queries, and external services with complete execution clarity to quickly isolate latency, errors, and performance slowdowns.
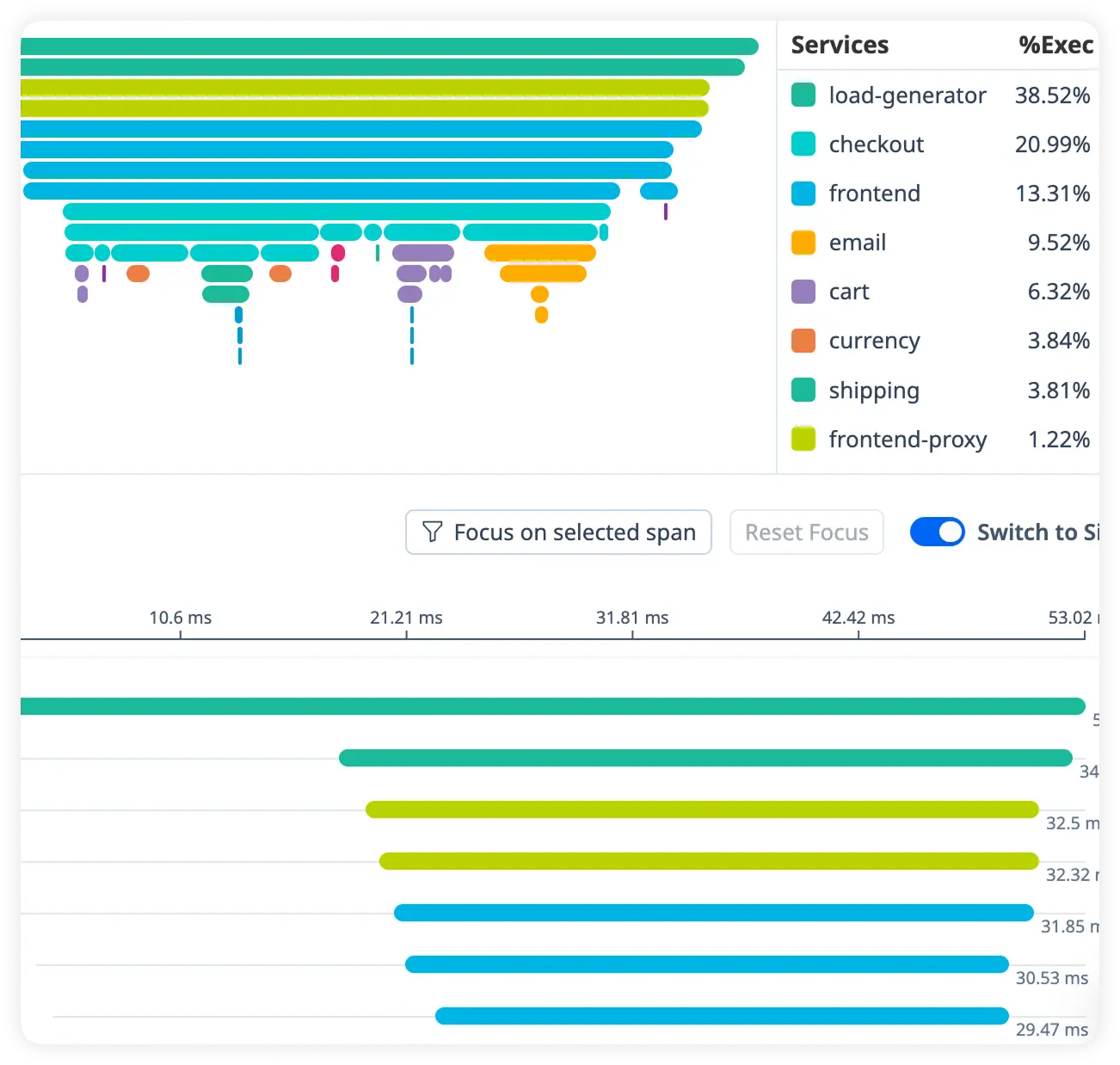
Visualize Slim Service Dependencies
See how Slim applications connect with databases and APIs using real-time latency, traffic volume, and health metrics to uncover hidden bottlenecks.
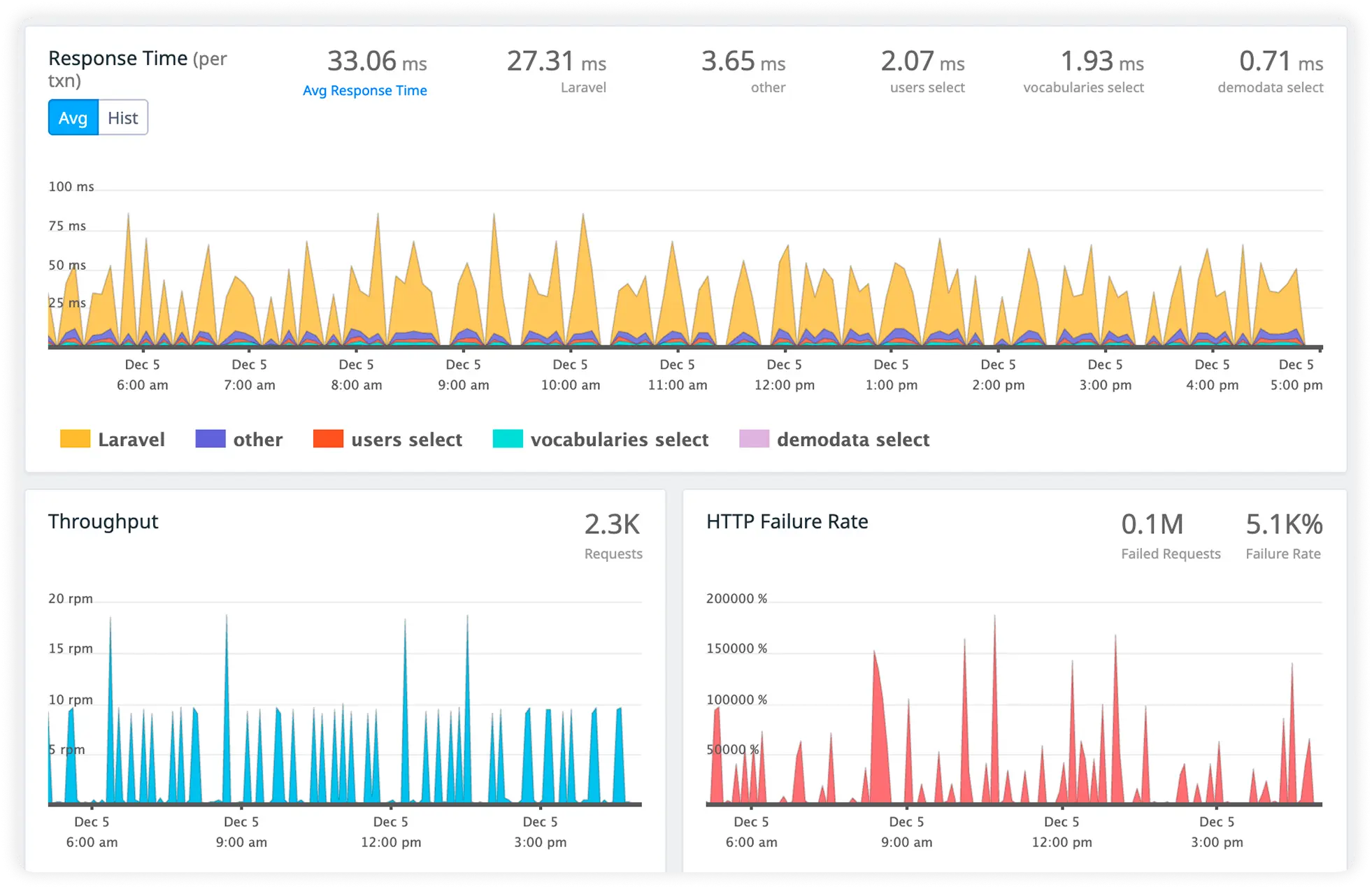
Monitor Critical Slim Endpoints
Track high-impact APIs and workflows to measure response time, failure rates, and throughput while maintaining fast and reliable user experiences.
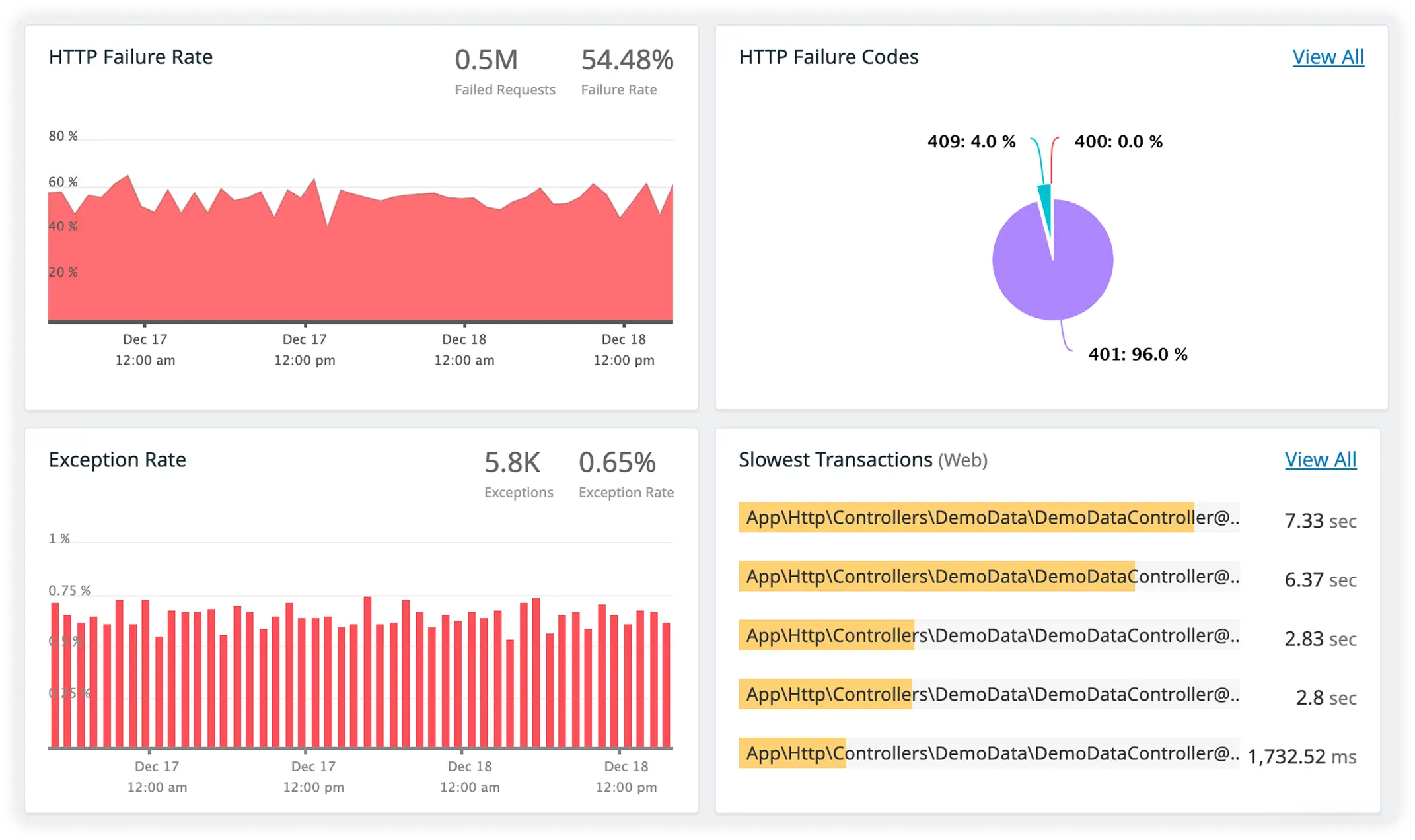
Track External Services
Monitor third-party APIs and remote calls with live performance data to detect slowdowns, failures, and reliability risks early.
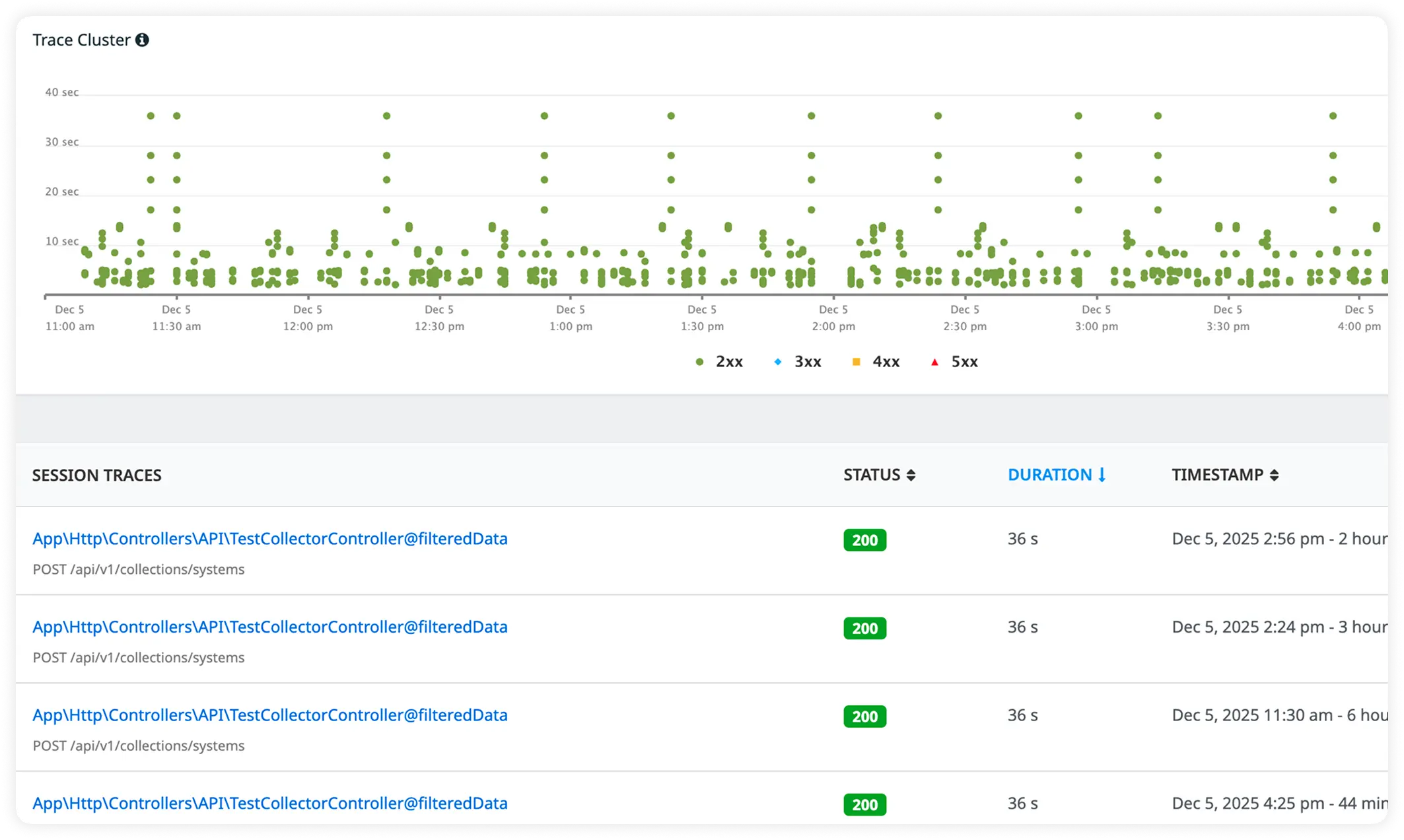
Why Engineering Teams Standardize on Atatus
Slim engineering teams choose Atatus when production clarity must remain reliable under real traffic, changing load, and limited operational headcount.
Clear Execution Order
Runtime behavior stays explicit, allowing engineers to follow how requests progress through systems without reconstructing assumptions.
Early Data Confidence
Teams trust production signals immediately, reducing hesitation and speeding up decision-making during incidents.
Minimal Adoption Overhead
Teams reach meaningful visibility without long rollout cycles or process disruption.
Repeatable Debugging Flow
Investigations follow consistent patterns, enabling faster resolution regardless of who is on call.
Lower On-Call Stress
Engineers spend less time guessing and more time acting, even during high-severity production events.
Shared Runtime Truth
Platform, SRE, and backend teams reference the same execution evidence during incident reviews.
Concurrency-Safe Visibility
Observability remains reliable as parallelism increases, preventing loss of insight during peak load.
Resilience During Failures
Teams retain meaningful visibility even when systems are partially degraded.
Durable Operational Trust
As systems evolve and ownership shifts, production understanding remains stable instead of degrading over time.
Unified Observability for Every Engineering Team
Atatus adapts to how engineering teams work across development, operations, and reliability.
Developers
Trace requests, debug errors, and identify performance issues at the code level with clear context.
DevOps
Track deployments, monitor infrastructure impact, and understand how releases affect application stability.
Release Engineer
Measure service health, latency, and error rates to maintain reliability and reduce production risk.